







1. 课程设计名称
哈夫曼编译码通信系统设计
2. 课程设计任务及要求
(1)设计任务
①能够顺利建立一个哈夫曼树
②能够根据哈夫曼树进行对编码的翻译并显示
③对错误编码能够进行辨别
(2)设计要求
①建立哈夫曼树
②模拟一个通信出错的过程,接收方要能够检查出来
③模拟通信无差错的过程,即接收到的序列没有错误,则译码
3.数据结构设计
(1).二叉树结构体:
typedef struct
{
int weight;
int parent,lchild,rchild;
} HTNode,HuffmanTree;
typedef char **HuffmanCode;
weight; //结点的权值
parent,lchild,rchild; //结点的双亲,左孩子,右孩子的下标
HTNode,HuffmanTree; //动态分配数组来 储存哈夫曼树的结点
**HuffmanCode; //动态分配数组来储存哈夫曼编码作用:设计哈夫曼树的结点类型
(2)顺序存储结构
函数: void Select(HuffmanTree HT,int len,int &sl,int &s2)
原理:利用循环遍历整个哈夫曼树,找到两个权值最小的结点
函数: void CreatHuffmanTree(HuffmanTree &HT,int n)
原理:调用select函数寻找俩个权值最小的结点,然后将权值最小的俩个结点来构造出新的结点,即根据哈夫曼算法来构造哈夫曼树。
函数: void HuffmanCoding(HuffmanTree HT,HuffmanCode &HCint n)
原理:从叶子结点到根结点根据左分支为 0,右分支为1的原理对哈夫曼树中的每个结点进行编码,实质就是使用频率越高的字符采用越短的编码。
函数: void HuffmanDecoding(HuffmanTree HT,char a[],char zf[],char b[],int n)
原理:从跟结点到根叶子结点根据左分支为 0,右分支为 1的原理对二进制数字进行遍历,直到找到根结点。
函数: void menu()
原理:调用上述创建哈夫曼树CreatHuffmanTree(),哈夫曼编码HuffmanCoding()和哈夫曼译码HuffmanDecoding()函数来实现对通信系统的模拟过程,利用顺序结构进行界面设计及输出
4.算法详细设计:
(1) Select函数
作用:哈夫曼树HT中选择两个双亲域为0且权值最小的两个结点,并返回它们在HT中的序号s1和s2
原理:连续利用俩个循环结构求出权值最小的结点和第二小的结点,时间复杂度为O(n),空间复杂度为O(1).
void Select(HuffmanTree HT, int len, int& s1, int& s2)
{
int i, min1 = 32767, min2 = 32767;
for (i = 1; i <= len; i++)
{
if (HT[i].weight < min1 && HT[i].parent == 0)
{
min1 = HT[i].weight;
s1 = i;
}
}
for (i = 1; i <= len; i++)
{
if (HT[i].weight < min2 && i != s1 && HT[i].parent == 0)
{
min2 = HT[i].weight;
s2 = i;
}
}
}(2)CreatHuffmanTree函数
作用:利用输入的字符及权值构造哈夫曼树HT
原理:根据哈夫曼算法来构造哈夫曼树,时间复杂度为O(n),由于数组都是动态分配,故空间复杂度为O(1).
void CreatHuffmanTree(HuffmanTree& HT, int n)
{
int s1, s2;
if (n <= 1)
return;
int m = 2 * n - 1; //当n大于1时,n个叶子结点需要2*n-1个结点
HT = new HTNode[m + 1]; //0号单元未用,所以需要动态分配m+1个单元,HT[m]表示根结点
//将1~m号单元中的双亲、左孩子,右孩子的下标都初始化为0
for (int i = 1; i <= m; ++i)
{
HT[i].parent = 0;
HT[i].lchild = 0;
HT[i].rchild = 0;
}
cout << "请输入叶子结点的权值:";
//输入前n个单元中叶子结点的权值
for (int i = 1; i <= n; ++i)
{
cin >> HT[i].weight;
}
//通过n-1次的选择、删除、合并来创建哈夫曼树
for (int i = n + 1; i <= m; ++i)
{
//在HT[k](1≤k≤i-1)中选择两个其双亲域为0且权值最小的结点,并返回它们在HT中的序号s1和s2
Select(HT, i - 1, s1, s2);
//得到新结点i,从森林中删除s1,s2,将s1和s2的双亲域由0改为i
HT[s1].parent = i;
HT[s2].parent = i;
//s1,s2分别作为i的左右孩子
HT[i].lchild = s1;
HT[i].rchild = s2;
//i的权值为左右孩子权值之和
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
}(3)HuffmanCoding函数
作用:对每个结点进行哈夫曼编码
原理:for循环用来查找每一个节点,while循环进行哈夫曼编码,时间复杂度为O(n2),空间复杂度为O(1).
void HuffmanCoding(HuffmanTree HT, HuffmanCode& HC, int n)
{
//从叶子到根逆向求每个字符的哈夫曼编码,存储在编码表HC中
HC = new char* [n + 1]; //分配n个字符编码的编码表空间(头指针矢量)
char* cd = new char[n]; //分配临时存放编码的动态数组空间
cd[n - 1] = '\0'; //编码结束符
//从叶子开始逐个字符求哈夫曼编码
for (int i = 1; i <= n; ++i)
{
int start = n - 1; //start开始时指向最后,即编码结束符位置
int c = i;
int f = HT[i].parent; //f是指向结点c的双亲结点
//从叶子结点开始向上回溯,直到根结点
while (f != 0)
{
--start; //回溯一次,start向前指向一个位置
//判断是结点c是f的左孩子还是右孩子
if (HT[f].lchild == c)
{
cd[start] = '0'; //结点c是f的左孩子,则生成代码0
}
else
{
cd[start] = '1'; //结点c是f的右孩子,则生成代码1
}
c = f;
f = HT[f].parent; //继续向上回溯
} //求出第i个字符的编码
HC[i] = new char[n - start]; //为第i个字符编码分配空间
strcpy(HC[i], &cd[start]); //将求得的编码从临时空间cd复制到HC的当前行中
}
delete cd; //释放临时空间
}(4)HuffmanDecoding函数
作用:输入一串二进制数后进行哈夫曼译码
原理:根据输入的二进制从根节点开始寻找,直到找到叶子节点,时间复杂度为O(n),空间复杂度为O(1).
void HuffmanDecoding(HuffmanTree HT, char a[], char zf[], char b[], int n)
{
//a[]用来传入二进制编码,b[]用来记录译出的字符
//zf[]是与哈夫曼树的叶子对应的字符,n是字符个数相当于zf[]数组的长度
int q = 2 * n - 1; //q初始化为根结点的下标
int k = 0; //记录存储译出字符数组的下标
for (int i = 0; a[i] != '\0'; i++) //for循环结束条件是读入的字符是结束符
{
//判断读入的二进制字符是0还是1
if (a[i] == '0')
{
//读入0,把根结点(HT[q])的左孩子的下标值赋给q,
//下次循环的时候把HT[q]的左孩子作为新的根结点
q = HT[q].lchild;
}
else if (a[i] == '1')
{
//读入1,把根结点(HT[q])的右孩子的下标值赋给q,
//下次循环的时候把HT[q]的右孩子作为新的根结点
q = HT[q].rchild;
}
else
{
b[0] = '\0';
}
//判断HT[q]是否为叶子结点
if (HT[q].lchild == 0 && HT[q].rchild == 0)
{
//如果读到一个结点的左孩子和右孩子都为0,是叶子结点,
//说明已经译出一个字符,该字符的下标就是找到的叶子结点的下标
b[k++] = zf[q]; //把下标为q的字符赋给字符数组b[]
q = 2 * n - 1; //初始化q为根结点的下标
} //继续译下一个字符的时候从哈夫曼树的根结点开始
}
//译码完成之后,用来记录译出字符的数组由于没有结束符输出的时候会报错,
//所以紧接着把一个结束符加到数组最后
b[k] = '\0';
}5.调试与结果分析:
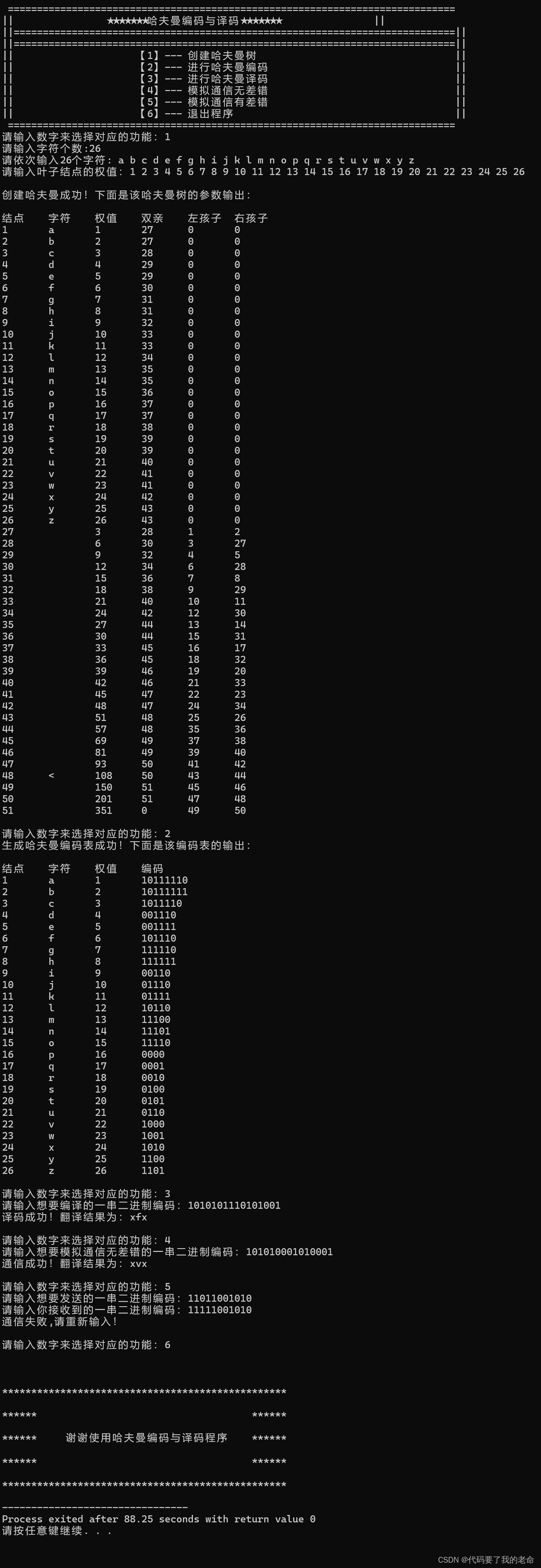
6.完整源代码
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<string.h>
#define MAX_MA 1000
#define MAX_ZF 100
using namespace std;
/*
a b c d e f g h i j k l m n o p q r s t u v w x y z
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
*/
/*
a b c d e f g h i j k l m n o p q r s t u v w x y z
2 6 7 9 5 21 12 16 18 12 13 1 24 26 28 29 53 42 41 3 23 36 35 39 65 21
*/
//哈夫曼树的顺序储存表示
typedef struct
{
int weight; //结点的权值
int parent, lchild, rchild; //结点的双亲,左孩子,右孩子的下标
} HTNode, * HuffmanTree; //动态分配数组来储存哈夫曼树的结点
//哈夫曼编码表的储存表示
typedef char** HuffmanCode; //动态分配数组来储存哈夫曼编码
//在哈夫曼树HT中选择两个双亲域为0且权值最小的两个结点,并返回它们在HT中的序号s1和s2
void Select(HuffmanTree HT, int len, int& s1, int& s2)
{ //len代表HT数组的长度
int i, min1 = 32767, min2 = 32767; //先赋予最大值
for (i = 1; i <= len; i++)
{
if (HT[i].weight < min1 && HT[i].parent == 0)
{
min1 = HT[i].weight;
s1 = i;
}
}
for (i = 1; i <= len; i++)
{
if (HT[i].weight < min2 && i != s1 && HT[i].parent == 0)
{
min2 = HT[i].weight;
s2 = i;
}
}
}
//构造哈夫曼树HT
void CreatHuffmanTree(HuffmanTree& HT, int n)
{
int s1, s2;
if (n <= 1)
return;
int m = 2 * n - 1; //当n大于1时,n个叶子结点需要2*n-1个结点
HT = new HTNode[m + 1]; //0号单元未用,所以需要动态分配m+1个单元,HT[m]表示根结点
//将1~m号单元中的双亲、左孩子,右孩子的下标都初始化为0
for (int i = 1; i <= m; ++i)
{
HT[i].parent = 0;
HT[i].lchild = 0;
HT[i].rchild = 0;
}
cout << "请输入叶子结点的权值:";
//输入前n个单元中叶子结点的权值
for (int i = 1; i <= n; ++i)
{
cin >> HT[i].weight;
}
//通过n-1次的选择、删除、合并来创建哈夫曼树
for (int i = n + 1; i <= m; ++i)
{
//在HT[k](1≤k≤i-1)中选择两个其双亲域为0且权值最小的结点,并返回它们在HT中的序号s1和s2
Select(HT, i - 1, s1, s2);
//得到新结点i,从森林中删除s1,s2,将s1和s2的双亲域由0改为i
HT[s1].parent = i;
HT[s2].parent = i;
//s1,s2分别作为i的左右孩子
HT[i].lchild = s1;
HT[i].rchild = s2;
//i的权值为左右孩子权值之和
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
}
//哈夫曼编码
void HuffmanCoding(HuffmanTree HT, HuffmanCode& HC, int n)
{
//从叶子到根逆向求每个字符的哈夫曼编码,存储在编码表HC中
HC = new char* [n + 1]; //分配n个字符编码的编码表空间(头指针矢量)
char* cd = new char[n]; //分配临时存放编码的动态数组空间
cd[n - 1] = '\0'; //编码结束符
//从叶子开始逐个字符求哈夫曼编码
for (int i = 1; i <= n; ++i)
{
int start = n - 1; //start开始时指向最后,即编码结束符位置
int c = i;
int f = HT[i].parent; //f是指向结点c的双亲结点
//从叶子结点开始向上回溯,直到根结点
while (f != 0)
{
--start; //回溯一次,start向前指向一个位置
//判断是结点c是f的左孩子还是右孩子
if (HT[f].lchild == c)
{
cd[start] = '0'; //结点c是f的左孩子,则生成代码0
}
else
{
cd[start] = '1'; //结点c是f的右孩子,则生成代码1
}
c = f;
f = HT[f].parent; //继续向上回溯
} //求出第i个字符的编码
HC[i] = new char[n - start]; //为第i个字符编码分配空间
strcpy(HC[i], &cd[start]); //将求得的编码从临时空间cd复制到HC的当前行中
}
delete cd; //释放临时空间
}
//哈夫曼译码
void HuffmanDecoding(HuffmanTree HT, char a[], char zf[], char b[], int n)
{
//a[]用来传入二进制编码,b[]用来记录译出的字符
//zf[]是与哈夫曼树的叶子对应的字符,n是字符个数相当于zf[]数组的长度
int q = 2 * n - 1; //q初始化为根结点的下标
int k = 0; //记录存储译出字符数组的下标
for (int i = 0; a[i] != '\0'; i++) //for循环结束条件是读入的字符是结束符
{
//判断读入的二进制字符是0还是1
if (a[i] == '0')
{
//读入0,把根结点(HT[q])的左孩子的下标值赋给q,
//下次循环的时候把HT[q]的左孩子作为新的根结点
q = HT[q].lchild;
}
else if (a[i] == '1')
{
//读入1,把根结点(HT[q])的右孩子的下标值赋给q,
//下次循环的时候把HT[q]的右孩子作为新的根结点
q = HT[q].rchild;
}
else
{
b[0] = '\0';
}
//判断HT[q]是否为叶子结点
if (HT[q].lchild == 0 && HT[q].rchild == 0)
{
//如果读到一个结点的左孩子和右孩子都为0,是叶子结点,
//说明已经译出一个字符,该字符的下标就是找到的叶子结点的下标
b[k++] = zf[q]; //把下标为q的字符赋给字符数组b[]
q = 2 * n - 1; //初始化q为根结点的下标
} //继续译下一个字符的时候从哈夫曼树的根结点开始
}
//译码完成之后,用来记录译出字符的数组由于没有结束符输出的时候会报错,
//所以紧接着把一个结束符加到数组最后
b[k] = '\0';
}
void menu()
{
int n; //记录要编码的字符个数
char a[MAX_MA]; //储存输入的二进制字符
char b[MAX_ZF]; //存储译出的字符
char c[MAX_MA]; //储存输入的二进制字符
char zf[MAX_ZF]; //储存要编码的字符
HuffmanTree HT = NULL;//初始化树为空树
HuffmanCode HC = NULL;//初始化编码表为空表
cout << " ============================================================================= \n";
cout << "|| ★★★★★★★哈夫曼编码与译码★★★★★★★ ||\n";
cout << "||============================================================================||\n";
cout << "||============================================================================||\n";
cout << "|| 【1】--- 创建哈夫曼树 ||\n";
cout << "|| 【2】--- 进行哈夫曼编码 ||\n";
cout << "|| 【3】--- 进行哈夫曼译码 ||\n";
cout << "|| 【4】--- 模拟通信无差错 ||\n";
cout << "|| 【5】--- 模拟通信有差错 ||\n";
cout << "|| 【6】--- 退出程序 ||\n";
cout << " ============================================================================= \n";
cout << "请输入数字来选择对应的功能:";
while (1)
{
int num;
if (!(cin >> num))
{
cout << "输入格式错误!请重新输入:" << endl;
}
else
{
switch (num)
{
case 1:
cout << "请输入字符个数:";
cin >> n;
cout << "请依次输入" << n << "个字符: ";
for (int i = 1; i <= n; i++)
cin >> zf[i];
CreatHuffmanTree(HT, n);
cout << endl;
cout << "创建哈夫曼成功!下面是该哈夫曼树的参数输出:" << endl;
cout << endl;
cout << "结点" << "\t" << "字符" << "\t" << "权值" << "\t" << "双亲" << "\t" << "左孩子" << "\t" << "右孩子" << endl;
for (int i = 1; i <= 2 * n - 1; i++)
{
cout << i << "\t" << zf[i] << "\t" << HT[i].weight << "\t" << HT[i].parent << "\t" << HT[i].lchild << "\t" << HT[i].rchild << endl;
}
cout << endl;
cout << "请输入数字来选择对应的功能:";
break;
case 2:
HuffmanCoding(HT, HC, n);
cout << "生成哈夫曼编码表成功!下面是该编码表的输出:" << endl;
cout << endl;
cout << "结点" << "\t" << "字符" << "\t" << "权值" << "\t" << "编码" << endl;
for (int i = 1; i <= n; i++)
{
cout << i << "\t" << zf[i] << "\t" << HT[i].weight << "\t" << HC[i] << endl;
}
cout << endl;
cout << "请输入数字来选择对应的功能:";
break;
case 3:
cout << "请输入想要编译的一串二进制编码:";
cin >> a;
HuffmanDecoding(HT, a, zf, b, n);
if (b[0] != '\0')
cout << "译码成功!翻译结果为:" << b << endl;
else
cout << "输入错误!没有此功能!请重新输入!" << endl;
cout << endl;
cout << "请输入数字来选择对应的功能:";
break;
case 4:
cout << "请输入想要模拟通信无差错的一串二进制编码:";
cin >> a;
HuffmanDecoding(HT, a, zf, b, n);
if (b[0] != '\0')
cout << "通信成功!翻译结果为:" << b << endl;
else
cout << "输入错误!没有此功能!请重新输入!" << endl;
cout << endl;
cout << "请输入数字来选择对应的功能:";
break;
case 5:
cout << "请输入想要发送的一串二进制编码:";
cin >> a;
cout << "请输入你接收到的一串二进制编码:";
cin >> c;
if (strcmp(a, c) == 0)
{
HuffmanDecoding(HT, a, zf, b, n);
if (b[0] != '\0')
cout << "通信成功!翻译结果为:" << b << endl;
else
cout << "输入错误!没有此功能!请重新输入!" << endl;
}
else
{
cout << "通信失败,请重新输入!" << endl;
}
cout << endl;
cout << "请输入数字来选择对应的功能:";
break;
case 6:
cout << "\n\n";
cout << "\n*************************************************" << endl;
cout << "\n****** ******" << endl;
cout << "\n****** 谢谢使用哈夫曼编码与译码程序 ******" << endl;
cout << "\n****** ******" << endl;
cout << "\n*************************************************" << endl;
exit(0);
default:
cout << "输入错误!没有此功能!请重新输入!" << endl;
cout << endl;
break;
}
}
}
}
int main()
{
menu();
return 0;
}














 941
941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









