









【概述】
前段时间,在异常测试的环境里,发现yarn任务无法提交,经过逐步排查,最后发现在一个极端的场景下,存在JN不会重新向kerberos进行认证,导致整体均无法提供服务的情况。本文就来详细聊聊问题出现时的情况以及分析复现过程。
【问题分析】
某天下午,突然被拉到一个群里,上层业务的开发兄弟@我,说所有的yarn任务都无法提交了,麻烦看下是怎么回事?
知晓问题后,先看了下RM的情况,发现两个RM都是standby的状态。进一步查看RM的日志,提示是无法连接到NN。
接着,又看了NN的状态,发现两个NN也都是standby的状态。又跟踪看了下NN的日志信息,发现NN一直无法正确初始化。
到这里,有些疑惑起来,于是和上层业务的开发兄弟,以及测试同事进行了沟通,了解了整个环境之前的一些状况,以及问题出现前后的一些操作。
得到的信息是:该环境做过异常测试,主要是对部分业务(kdc)进行了一段时间的关闭,然后启动进行恢复,在关闭过程中还对其他部分业务(hadoop)进行了重启,以观察系统的稳定性。
有了这些信息后,结合NN的日志深入进行分析,从日志中发现,两个NN均无法与JN建立连接。
2022-06-06 09:57:02,134 WARN org.apache.hadoop.ipc.Client: Couldn't setup connection for namenode-0@BIGDATA.COM to journalnode-0/192.168.191.162:8485
org.apache.hadoop.ipc.RemoteException(javax.security.sasl.SaslException): Failure to initialize security context而JN日志中的报错信息则是无法完成sasl交互,其服务端的用户信息为空,本质上就是未进行kerberos登录认证!
2022-06-06 09:48:28,908 WARN SecurityLogger.org.apache.hadoop.ipc.Server: Auth failed for 192.168.55.184:36223:null (Failure to initialize security context) with true cause: (Failure to initialize security context)为什么JN会在kdc已经恢复正常的情况下,仍旧没有进行kerberos认证的,JN又是在哪些场景下进行kerberos认证的,这还得从源码中分析得出结论。
带着上面的问题走读源码发现,JN只有两种场景会进行kerberos的认证以及重新认证:
1. JN在首次收到NN的请求时,进行kerberos认证登录
// JournalNode.java
public void start() throws IOException {
try {
...
InetSocketAddress socAddr = JournalNodeRpcServer.getAddress(conf);
SecurityUtil.login(
conf,
DFSConfigKeys.DFS_JOURNALNODE_KEYTAB_FILE_KEY,
DFSConfigKeys.DFS_JOURNALNODE_KERBEROS_PRINCIPAL_KEY,
socAddr.getHostName());
...
}
}2.JN需要进行editlog恢复,即从其他JN上下载editlog信息时,验证票据信息是否有效(即是否已经过期),如果票据已经失效,则尝试重新向kerberos登录认证。但不会进行失败重试(即便kdc恢复正常,也不会进行重试)
// Journal.java
private File syncLog(
RequestInfo reqInfo,
final SegmentStateProto segment,
final URL url)
throws IOException {
SecurityUtil.doAsLoginUser(
new PrivilegedExceptionAction<Void>() {
@Override
public Void run() throws IOException {
// We may have lost our ticket since last checkpoint, log in again, just in case
if (UserGroupInformation.isSecurityEnabled()) {
UserGroupInformation.getCurrentUser().checkTGTAndReloginFromKeytab();
}
...
}
});
...
}
// UserGroupInformation.java
public synchronized void checkTGTAndReloginFromKeytab() throws IOException {
if (!isSecurityEnabled() ||
user.getAuthenticationMethod() != AuthenticationMethod.KERBEROS ||
!isKeytab)
return;
KerberosTicket tgt = getTGT();
if (tgt != null && !shouldRenewImmediatelyForTests &&
Time.now() < getRefreshTime(tgt)) {
return;
}
reloginFromKeytab();
}对于第二种场景,完全是由NN主备切换触发的。这意味着:
1)在KDC无法提供服务
2)JN的票据已经过期
3)票据过期的JN,其editlog事务ID比其他JN的小,需要进行editlog恢复
4)在同时满足以上3个条件的情况下,NN进行了主备切换
此时,就会触发JN的kerberos重新认证,并且认证失败,此后对于任何RPC请求均无法正确完成sasl交互。这样也就有了上面的问题现象了。
有了代码逻辑的支撑,反过来再看NN的日志,发现过程中确实有出现NN的主备切换,并且对应时间点,KDC是没有提供服务的,同时,其中一个JN也恰好出现了与其他JN的editlog不一致,需要从其他JN下载editlog进行恢复的情况。
因此,基本断定,问题就出现在这。
【问题复现】
上面是从代码逻辑反推并结合日志给出的结果。但还需要实际测试来复现验证。因此,按照下述操作步骤操作,模拟问题出现的情况。
1)修改kdc的有效期为5分钟
2)重启kdc,使票据有效期生效
3)重启JN,等待3分钟后,再重启NN,保证JN的票据先失效,这样NN触发主备切换时,票据还在有效期,因此可以顺利执行主备切换的动作
4)停止kdc
5)修改其中一个JN的editlog,模拟成该JN的事务ID比其他JN小的情况,具体又包括:
a. 删除最新的1个edits_xxx_xxx文件,同时删除edits_inprogress_xxx文件
b. 修改committed-txid为最后一个edits的事务ID
例如,当前相关文件信息如下图所示:

删除edits_0000000000001505818-0000000000001505819和edits_inprogress_0000000000001505820两个文件,这样,最后一个editlog文件为edits_0000000000001505816-0000000000001505817。
再修改事务committed-txid文件中的事务ID
echo 000000000016FA19 | xxd -r -ps committed-txid6)kill Active NN的zkfc,触发NN主备切换
7)启动kdc
如此一来,就可以看到JN的日志中有这样的报错信息:
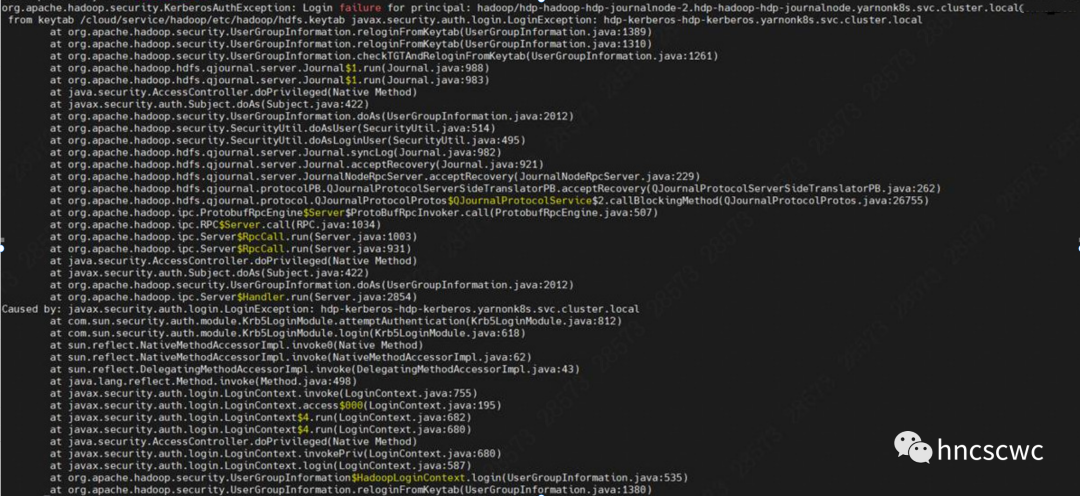 nn主备切换向jn请求时的报错日志信息:
nn主备切换向jn请求时的报错日志信息:
 以及,JN的kerberos认证失败后,处理rpc请求时,在sasl交互过程中的报错信息。
以及,JN的kerberos认证失败后,处理rpc请求时,在sasl交互过程中的报错信息。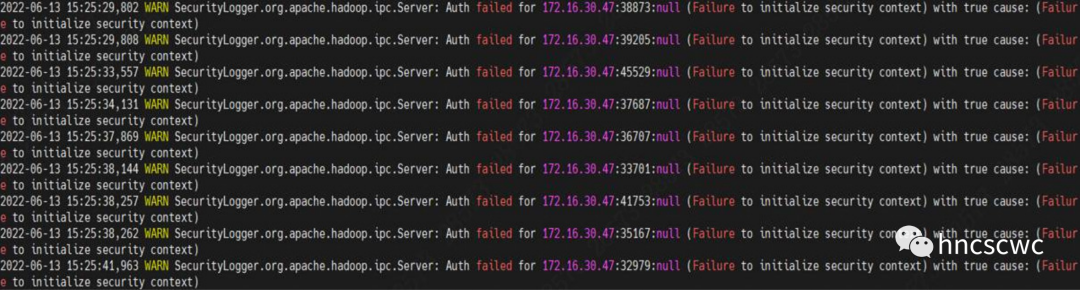
对应的代码段为:
// server.java
private void saslProcess(RpcSaslProto saslMessage) {
...
try {
saslResponse = processSaslMessage(saslMessage);
} catch (IOException e) {
rpcMetrics.incrAuthenticationFailures();
if (LOG.isDebugEnabled()) {
LOG.debug(StringUtils.stringifyException(e));
}
// attempting user could be null
IOException tce = (IOException) getCauseForInvalidToken(e);
AUDITLOG.warn(
AUTH_FAILED_FOR + this.toString() + ":" +
attemptingUser + " (" + e.getLocalizedMessage() +
") with true cause: (" + tce.getLocalizedMessage() + ")");
throw tce;
}
}【问题解决】
该问题对于线上环境来说,一旦出现还是比较严重的,因为完全没有办法可以自我恢复,只能靠手动重启JN才能恢复。
对于2.X版本的hadoop而言,也确实没有好的办法来彻底解决,因为JN本身始终是被动提供服务。一旦kdc认证失败,没有再次触发重新认证的逻辑。如果需要解决,可以考虑修改源码,增加一个线程来定时监测票据是否过期,并进行重新登录认证。
而对于3.X版本的hadoop而言,从3.1.0而言,新增了JN之间自动同步editlog的功能,这就变相的触发了票据过期重新登录的过程,并且这个是定时检测的,同时该功能默认是启用的。因此升级到此后的版本就可以解决该问题。
好了,这就是本文的全部内容,如果觉得本文对您有帮助,请点赞+转发,也欢迎加我微信交流~















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









