






 本文介绍了GPU的内部工作原理,特别是其计算架构,包括流式多处理器(SM)、并行处理能力、内存层次结构(寄存器、固定缓存、共享内存等),以及如何通过利特尔定律理解GPU的高吞吐量和延迟容忍。重点讲述了GPU在深度学习中的重要性及其与CPU的对比。
本文介绍了GPU的内部工作原理,特别是其计算架构,包括流式多处理器(SM)、并行处理能力、内存层次结构(寄存器、固定缓存、共享内存等),以及如何通过利特尔定律理解GPU的高吞吐量和延迟容忍。重点讲述了GPU在深度学习中的重要性及其与CPU的对比。
前言
大多数的人对CPU和顺序编成有着深度的了解,但对GPU的内部工作原理以及它的特殊之处并不熟悉。在当下这个时代,GPU已经变得非常重要,因为他们在深度学习中广泛使用。而今天这篇文章,可以帮助你们快速了解GPU的计算与内存架构。
CPU与GPU对比
CPU和GPU之间的主要区别在于它们的设计目标。CPU被设计为执行顺序指令1。为了提高它们的顺序执行性能,多年来在CPU设计中引入了许多功能。重点是减少指令执行延迟,以便CPU可以尽可能快地执行指令序列。这包括指令流水线,乱序执行推测执行和多级缓存(仅列出几个)等功能。另一方面,GPU被设计用于大规模并行和高吞吐量,代价是中等到高的指令延迟。这一设计方向受到了它们在视频游戏、图形、数值计算和现在的深度学习中的使用的影响。所有这些应用程序都需要以非常快的速度执行大量的线性代数和数值计算,因此,大量的注意力都集中在提高这些设备的吞吐量上。
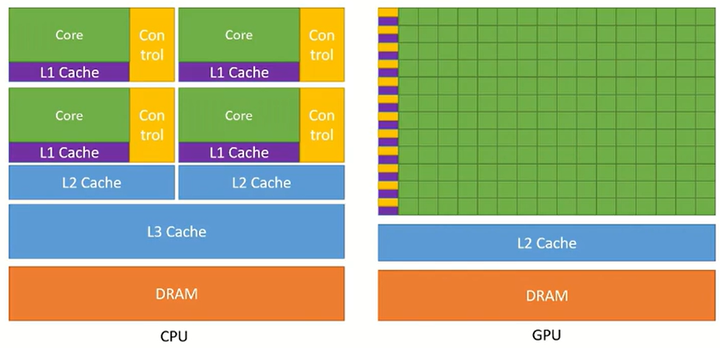
CPU与GPU设计比较
如果你对数值感兴趣,那我们就来看一下数值。数值计算硬件的性能是以每秒可以执行多少浮点运算(FLOPS)来衡量的。Nvidia Ampere A100提供19.5 TFLOPS的吞吐量。相比之下,英特尔24核处理器的吞吐量为0.66 TFLOPS。而且,GPU和CPU之间的吞吐量性能差距逐渐扩大。CPU将大量的芯片面积专用于减少指令延迟的功能。相比之下,GPU使用大量ALU来最大化其计算能力和吞吐量。它们使用非常少量的芯片区域用于缓存和控制单元,这些东西减少了CPU的延迟。
延迟容忍度、吞吐量与利特尔定律
GPU是如何容忍高延迟并提供高性能的?我们可以使用利特尔定律来理解这一点。它指出系统中请求的平均数量(队列深度的Qd)等于请求的平均吞吐率(吞吐量T)乘以服务请求的平均时间(延迟L)。
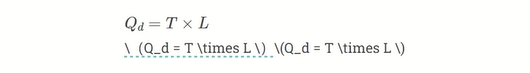
利特尔定律
在GPU的上下文中,这基本上意味着可以容忍系统中给定的延迟水平,以通过维护正在执行或等待的指令队列来实现目标吞吐量。GPU中的大量计算单元和高效的线程调度使GPU能够在内核执行时间内维护队列,并实现高吞吐量。
GPU计算架构

GPU计算架构
GPU由流式多处理器(SM)阵列组成。这些SM(全称Steaming Multiprocessor)中的每一个又由若干流式处理器或核心或线程组成。例如,Nvidia H100 GPU有132个SM,每个SM有64个核心,总计高达8448个核心。每个SM具有有限数量的片上存储器(缓存),通常称为共享存储器或暂存器,在所有内核之间共享。同样,SM上的控制单元资源由所有核共享。此外,每个SM配备有用于执行线程的基于硬件的线程调度器。除此之外,每个SM还具有多个功能单元或其他加速计算单元,例如张量核或光线跟踪单元(光锥),以满足GPU所满足的.工作负载的特定计算需求。
GPU内存架构
GPU有几层不同类型的内存,每层用于达到不同的目的。
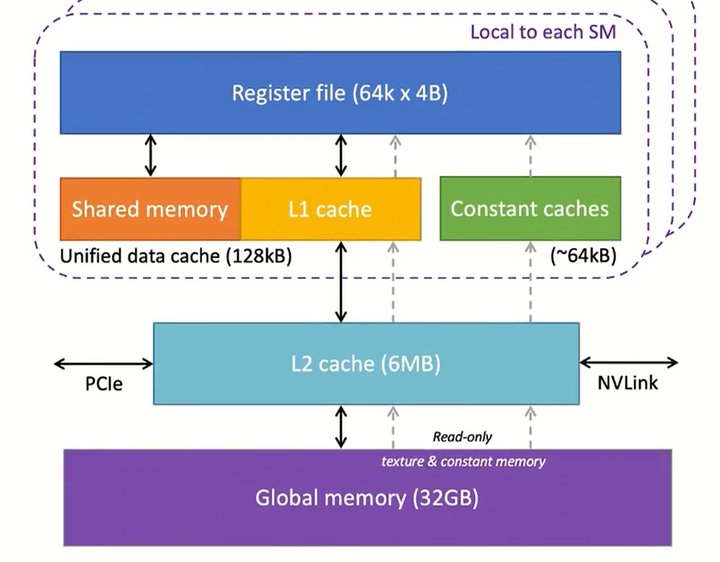
GPU内存架构
寄存器:我们将寄存器表开始。GPU中的每个SM都有大量的寄存器。例如,Nvidia A100和H100型号每个SM有65,536个寄存器。这些寄存器在内核之间共享,并根据线程的要求动态分配给它们。在执行期间,分配给线程的寄存器是线程私有的,其它线程不能读/写那些寄存器。
固定缓存:我们芯片上有固定的缓存。它们用于缓存在SM上执行的代码所使用的常量数据。为了利用这些缓存,程序员必须在代码中将对象声明为常量,以便GPU可以缓存并将它们保存在常量缓存中。
共享内存:每个SM还具有共享内存或暂存器,其是少量快速且低延迟的片上可编程SRAM存储器。它被设计为由SM上运行的线程块共享。共享内存背后的思想是,如果多个线程需要处理同一段数据,那么其中只有一个线程应该从全局内存中加载它,而其他线程将共享它。合理使用共享内存可以减少全局内存中的冗余加载操作,提高内核执行性能。共享内存的另一个用途是作为在块内执行的线程之间的同步机制。
一级缓存:每个SM都有一个一级缓存,可以缓存二级缓存中经常访问的数据。
二级缓存:有一个由所有SM共享的二级缓存。它从全局内存中缓存频繁访问的数据,以减少延迟。注意,一级和二级缓存对SM都是透明的,即,SM不知道它正在从一级或二级获取数据。就SM而言,它正在从全局存储器获取数据。这类似于一、二、三缓存在CPU中的工作方式。
全局内存:GPU还有一个片外全局内存,这是一个高容量和高带宽的DRAM。例如,Nvidia H100具有80 GB高带宽内存(HBM),带宽为3000GB/秒。由于远离SM,全局内存的延迟相当高。然而,片上存储器的几个附加层和大量的计算单元有助于隐藏这种延迟。
相信在你看完所有内容后,自己对GPU的理解更进了一步,以上就是对GPU计算与内存架构的详细讲解,如果还有其他疑问可以评论区留言,欢迎各位友好讨论!















 9891
9891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









