







GR-2
在科幻电影中,我们经常能看到人类通过远程操控机器人完成各种复杂任务的场景。而今天,这样的科幻场景正在成为现实。随着字节跳动研究团队最新推出的第二代机器人大模型GR-2(Generative Robot 2.0)的问世,我们离梦想中的未来又近了一步。
GR-2

GR-2 介绍
GR-2是一种最先进的通用机器人代理,用于多功能和可通用的机器人操作。GR-2 首先在大量互联网视频上进行预训练,以捕捉世界动态。这种大规模的预训练涉及 3800 万个视频剪辑和超过 500 亿个代币,使 GR-2 能够在随后的策略学习中泛化到广泛的机器人任务和环境。
而且GR-2 对使用机器人轨迹的视频生成和动作预测进行了微调。它表现出令人印象深刻的多任务学习能力,在 97.7 多项任务中实现了 100% 的平均成功率。
此外,GR-2 展示了对新的、以前从未见过的场景的非凡泛化,包括新的背景、环境、对象和任务。值得注意的是,它可以有效地随模型大小扩展,突显了其持续增长和应用的潜力。
技术性突破
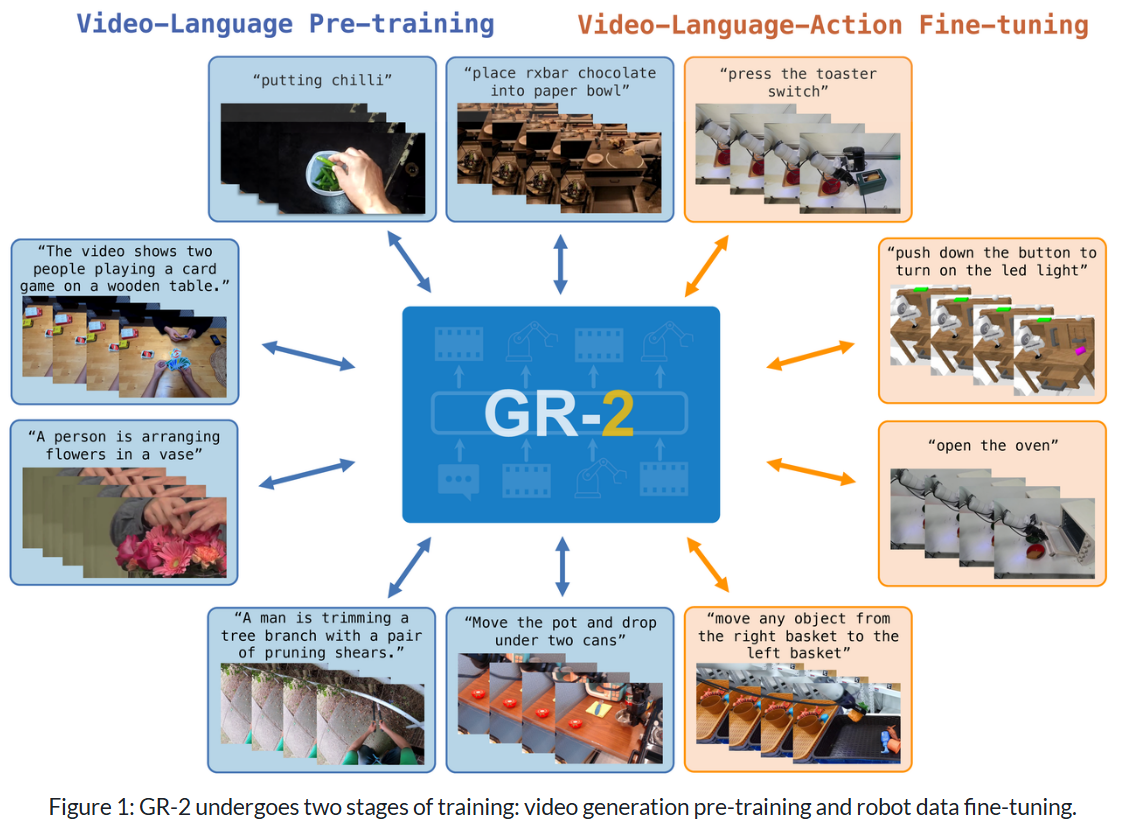
GR-2 训练过程展示
GR-2 的训练分为两个阶段:视频生成预训练和机器人数据微调。在预训练期间,我们在一个精心策划的大规模视频数据集上训练 GR-2 以生成视频,该数据集包含不同背景下的各种日常人类活动。通过掌握视频生成,GR-2 捕获了对下游策略学习至关重要的关键时间动态和语义信息。在微调过程中,我们根据机器人数据训练 GR-2 以协同预测动作轨迹和视频。
得益于新颖的模型架构,在预训练阶段收集的知识可以无损地转移到微调阶段。GR-2 与预训练数据中只有一个摄像头视图的视频不同,机器人数据通常包含多个视图。GR-2 旨在优雅地处理多个视图和在笛卡尔空间中生成动作轨迹。为了确保机械臂准确跟随轨迹,字节跳动团队开发了一种全身控制 (WBC) 算法,该算法采用轨迹优化进行运动跟踪。
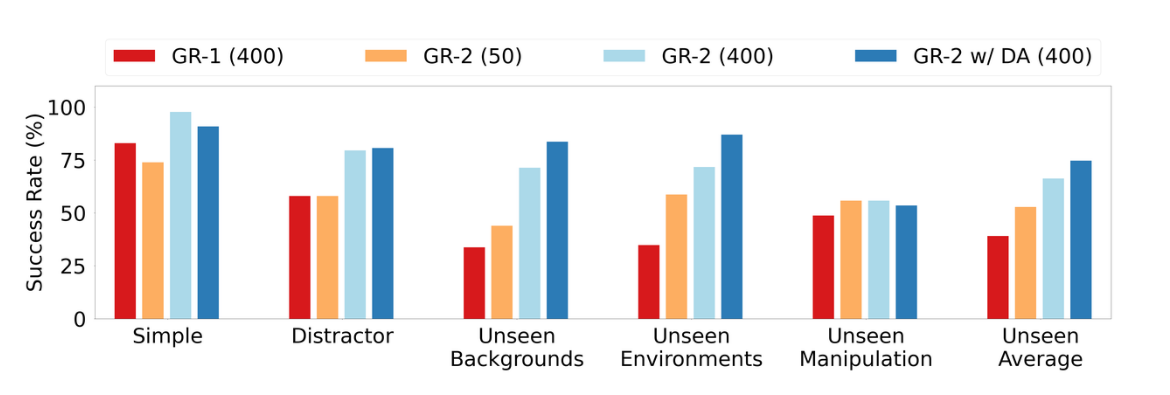
GR-2 学习成功率
GR-2 能够以非常高的成功率完成 105 个操作任务,在训练过程中GR-2 展示了强大的多任务学习能力。开发团队还在具有挑战性的场景中评估了 GR-2,包括干扰物、看不见的背景、看不见的环境和看不见的操作。GR-2 可以处理干扰物并正确处理目标物体。它在看不见的背景和环境中实现了很高的成功率,展示了强大的泛化能力。
GR-2 还能够执行机器人训练数据中看不到的操作且还能有效地学习 105 个任务,并做到每个任务只需 50 个轨迹。这大大降低了在实际应用中获取新技能和适应新环境的成本。
实测展示

GR-2 实测效果展示
从官方给出的实机演示来看,GR-2 的性能十分不错,在视频中 GR-2 可以正确的读取使用者发出的指令,将栏中的所有物品放到另一个栏中。不仅如此,GR-2 还可以使用烤面包机烘烤面包、使用咖啡机泡咖啡等一系列的行动,使用场景可以说是非常广泛。

GR-2 实测效果展示
GR-2的诞生,不仅仅是机器人技术的一次飞跃,更是人工智能与物理世界深度融合的里程碑。傅利叶创始人兼CEO顾捷表示:"我们的目标是为AI打造最佳具身载体。当人形机器人本体在各个维度都达到最优,它将成为AI的最佳具身选择。"
有关厚德云
厚德云致力于为用户提供稳定、可靠、易用、省钱的 GPU 算力解决方案。海量 GPU 算力资源租用,就在厚德云。















 4829
4829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









