







 SQuAD2.0是斯坦福大学发布的包含可回答和不可回答问题的问答数据集,旨在解决机器对不可回答问题的识别问题。数据集通过众包方式添加了50000多个由人编写的不可回答问题,提高了模型的自然语言理解难度。现有的模型在SQuAD2.0上表现不佳,表明仍有大量改进空间。
SQuAD2.0是斯坦福大学发布的包含可回答和不可回答问题的问答数据集,旨在解决机器对不可回答问题的识别问题。数据集通过众包方式添加了50000多个由人编写的不可回答问题,提高了模型的自然语言理解难度。现有的模型在SQuAD2.0上表现不佳,表明仍有大量改进空间。
说明:SQuAD 2.0是斯坦福大学发布的问答数据集,其对应论文为《Know what you don’t know:Unanswerable questions for SQuAD》。该论文是2018年ACL会议(NLP顶会,CCF-A推荐国际会议-人工智能类)的最佳短论文。(以下引用量截止博文发布)
| 数据库 | 引用量 |
|---|---|
| 谷歌学术 | 2149 |
| Scopus | 828 |
| Web of Science | 629 |
报告时间:2022-08-18
零、摘要
提取式阅读理解系统通常可以在给定文档中根据上下文信息找到问题的正确答案,但它们也倾向于对上下文中没有说明正确答案的问题进行不可靠的猜测。现有的数据集要么只关注可回答的问题,要么使用自动生成的易于识别的不可回答的问题。为了解决这些不足,我们推出了最新版本的斯坦福回答数据集:SQuAD 2.0。该数据集将SQuAD 1.1的数据与50000多个不可回答的问题结合在一起,这些不可回答的问题是由众包人员使用对抗性(adversarial)的方式编写的,看起来类似于可回答的问题。为了在SQuAD 2.0上取得更好的表现,系统不仅必须在可能的情况下回答问题,而且还必须确定何时没有答案被段落支持并放弃回答。对于现有的模型来说,SQuAD 2.0是一项具有挑战性的自然语言理解任务:一个强大的神经系统在SQuAD 1.1上取得86%的F1,在SQuAD 2.0上却只取得66%的F1。
TODO:论文思维导图
一、简要介绍
1.1 背景
当前,机器阅读理解已经成为自然语言理解的中心任务。
其中,机器问答是自然语言理解的一类重要任务。
大规模数据集对机器问答的发展有着重要作用——它能够促使人们改进模型架构。
而斯坦福问答数据集(Stanford Question Answering Dataset,SQuAD)就是一个典型的大型问答数据集。
得益于这些数据集,提取式阅读理解系统已经能够做到:在上下文文档中,找到问题的正确答案。这类问题称为可回答的问题(answerable questions)。
然而,有些问题在上下文中找不到正确答案,这类问题称为不可回答的问题(unanswerable questions)。对于不可回答的问题,系统倾向于作出不可靠的猜测。这就是机器问答的一个现有问题(problem)。
1.2 当前的解决方案(现有数据集的做法)
方案一:只关注可回答的问题
方案二:自动生成不可回答的问题,并使机器能够很容易地将其识别为不可回答的问题
1.3 作者对问题的分析
现有的系统与真正的语言理解还有相当大的距离。在 现有SQuAD(即SQuAD 1.1) 上的成功并不能保证模型在分散句子上的稳健性。造成这个问题的一个根本原因是:SQuAD 1.1专注于那些在语境文档中有正确答案的问题。因此,模型只需要选择看起来与问题最相关的文本范围(span),而不需要检查答案是否确实蕴涵(entail)在文本中。
现有的机器对于不可回答的问题,识别能力较差,只能识别那些机器生成的不可回答的问题。这是因为在训练模型时,缺少这种数据集:不可回答的问题由人类编写。
于是,作者以SQuAD 1.1为基础,针对相同的段落,增加53755个(人类编写的)不可回答的问题以及貌似合理的答案,得到SQuAD 2.0(以下称为“新数据集”)。
1.4 新数据集的特点
挑战性与高质量兼具。
使用新数据集训练的系统应该做到:尽可能地回答问题,同时识别出那些(人类编写的)不可回答的问题并放弃(abstain)回答。(知道它们不知道什么,know what they don’t know)
二、新数据集的目标
- 普通目标(generic goals):大规模、多样性、低噪声
- 对不可回答问题的特别期望(desiderata)
(1)相关。不可回答的问题应与上下文段落的主题相关。否则,使用简单的启发式方法就可以区分出不可回答的问题。
(2)存在貌似合理的(plausible)答案。在上下文中应该有一些文本段(span),其类型与问题要求的答案类型相匹配。例如, 如果问题是“哪家公司在1992年成立?“,那么一些公司(的名称)应该出现在上下文中。否则,使用类型匹配启发式方法就可以区分出不可回答的问题。
三、对现有数据集的调研
作者以第二节提出的两个特别期望(问题与上下文相关、存在貌似合理的答案)为标准,对现有的阅读理解数据集进行调查。
【术语】反例(negative example):一个反例是一个段落与一个不可回答问题的配对。
3.1 提取式的(extractive)数据集
使用这种数据集训练的系统必须从上下文文档或段落中提取问题的正确答案。
有些数据集将反例被排除在最终数据集之外,如TriviaQA、NewsQA等。
有两个研究者通过将现有问题与同一文章中的其他段落配对(基于TF-IDF重叠),来生成旧数据集的反例。作者将这些段落称为TFIDF实例。
TF-IDF:一种用于信息检索与数据挖掘的常用加权技术,其中TF(Term Frequency)是词频,IDF(Inverse Document Frequency)是逆文本频率指数。
有两个研究者提出了一种基于规则的程序来编写旧数据集的问题,以使它们变得不可回答。他们的问题不是很多样:他们只用相似的单词替换实体和数字,用WordNet反义词替换名词和形容词。作者将这些不可回答的问题称为RULEBASED问题。
3.2 答案句子选择数据集
这种数据集用于测试:系统是否可以对答案句子的得分进行排名
WikiQA:不能保证与问题的高度相关性或具有貌似合理的答案;规模也很有限。
3.3 多项选择数据集
在实践中,多项选择选项通常不可用,这使得这些数据集不太适合训练面向用户的系统。
多项选择题也往往与抽取式的问题有很大不同,后者更强调填空、解释和总结。
四、新数据集的描述
4.1 数据集的创建
作者在Daemo众包平台上雇用众包工作者来编写不可回答的问题。

图2:呈现给众包工作者的界面示意图。
SQuAD 1.1中的每篇文章对应一个任务,每个段落最多提出5个问题(上图中左绿框部分)。在段落下同时显示了已有的可回答的问题,用于启发(上图中右绿框部分)。
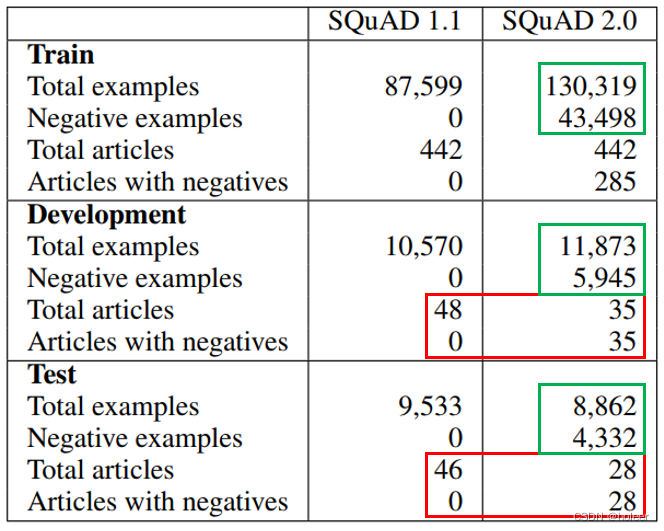
数据集分为三个子集:训练集、开发集、测试集。在划分这三个子集时,使用与SQuAD 1.1 相同的文章分区,并将原有数据与新数据结合。旧数据集和新数据集的统计信息如下表所示。对于开发集和测试集,研究者删除了没有收集到不可回答问题的文章(下图中红框部分)。这导致在开发集和测试集分割中的可回答问题和不可回答问题的比例大致为 1:1,而训练数据中可回答问题与不可回答问题的比例大致为 2:1(下图中绿框部分)。
4.2 人类的准确性(accuracy)
为了确认数据集中没有脏数据,作者雇用了另外的众包工作者来回答开发集和测试集中的所有问题。回答者要么在段落中标记问题的答案,要么把问题标记为不可回答。
为了减少噪音,为每个问题收集多个人工答案,并通过多数票策略选择最终的答案。平均每个问题收集到了4.8个答案。
4.3 抽样分析
作者从数据集中随机抽取了100个反例,进行手动检查。分析结果如下表所示。这些反例可以分为七类。而RULEBASED数据集只涉及到反义词和实体交换这两类。
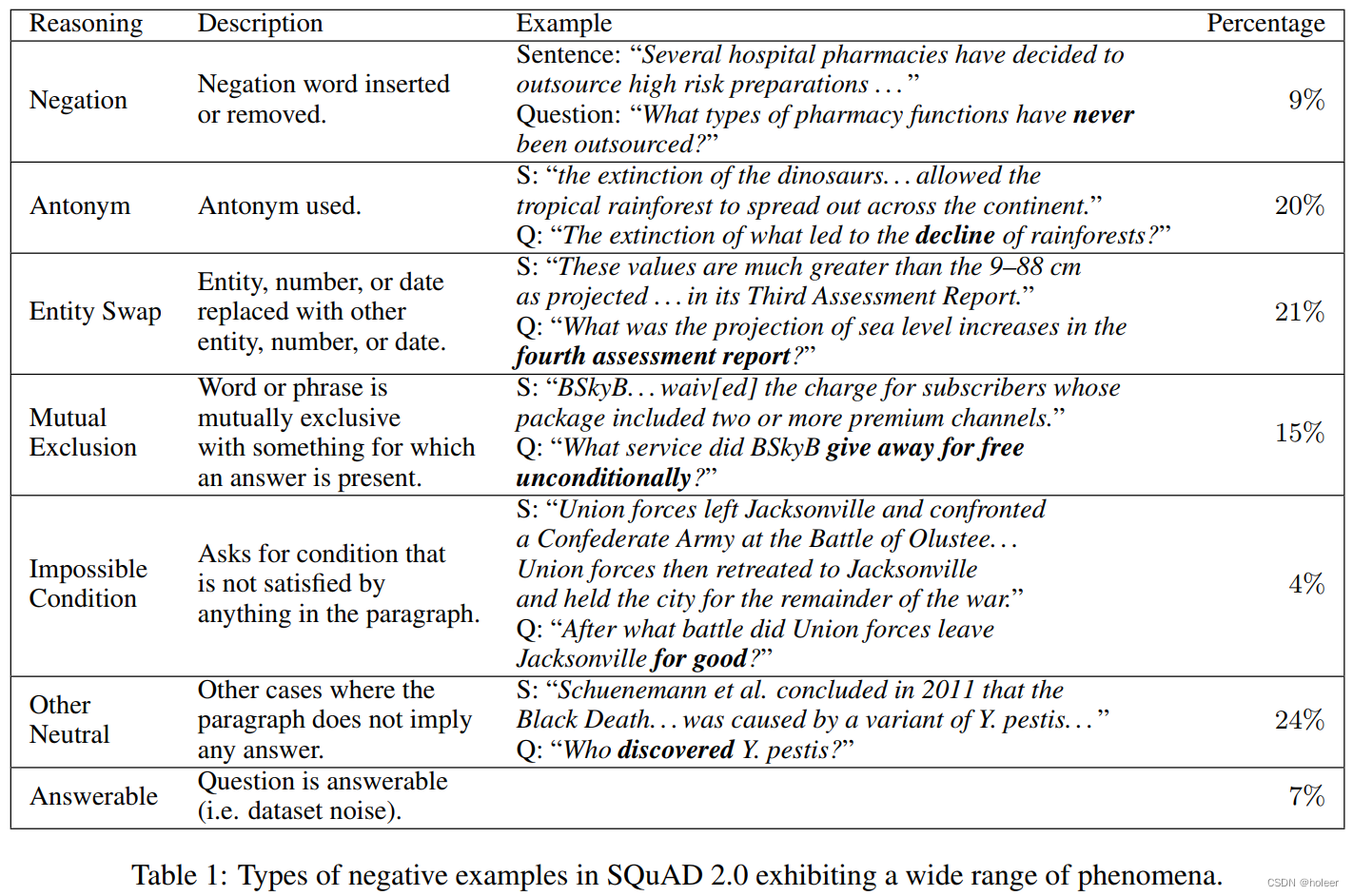
以上表格的参考翻译如下。
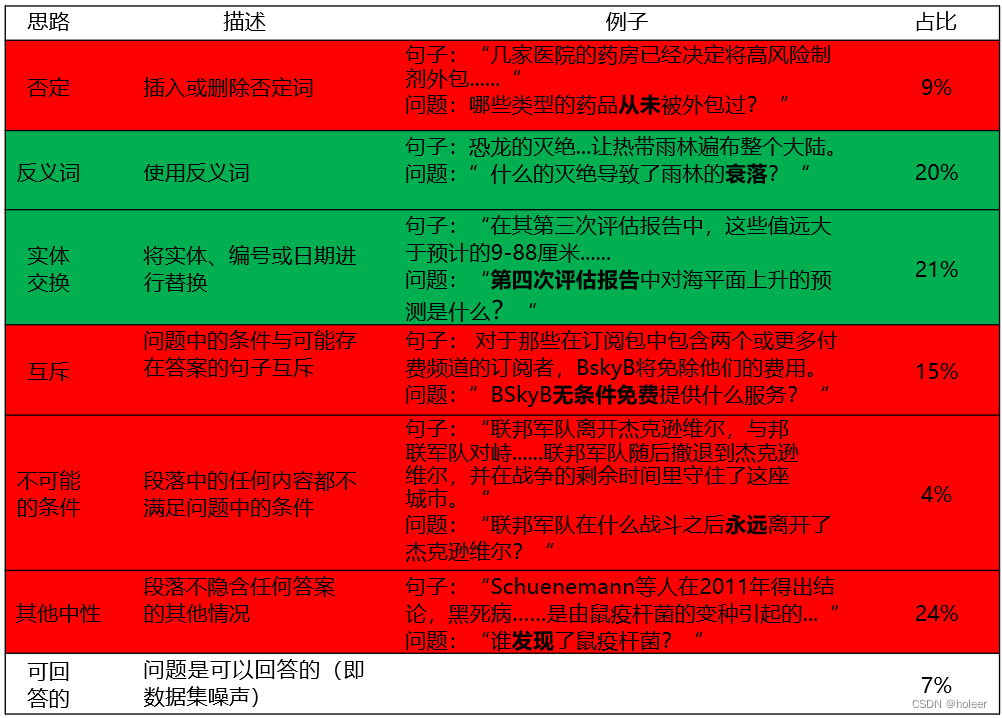
其中绿色部分为RULEBASED有涉及的,红色部分为RULEBASED未涉及的。
五、实验
5.1 模型
作者选择了三种模型架构: BiDAF-No-Answer(BNA) 模型、 Document QA No-Answer(DocQA) 模型的两个版本(带有ELMo、不带有ELMo)。
这些模型能够学会预测一个问题不可回答的概率。在测试阶段,当这个概率超过某个阈值时,模型就会放弃回答。作者对每个模型分别调整阈值,使它们在开发集上的F1分数最大化。
F1分数:又称平衡F分数,它是精确率和召回率的调和平均数,最小值为0,最大值为1。论文中出现的F1都乘上了100倍。
5.2 主要结果
首先,作者在SQuAD 2.0 上训练并测试了所有三个模型。
使用两个指标对模型的表现进行评价: 平均完全匹配(Exact Match,EM) 和F1得分。
对于一个反例,如果模型弃权,将得到1分;如果做出任何其他响应,则会得到0分。这个规则对于完全匹配和F1都适用。
结果如下表所示。从表中可以看出,在SQuAD 2.0测试这块区域上,模型得到的最高F1也只有66.3,比人类表现低了23.2分。(红色框部分)
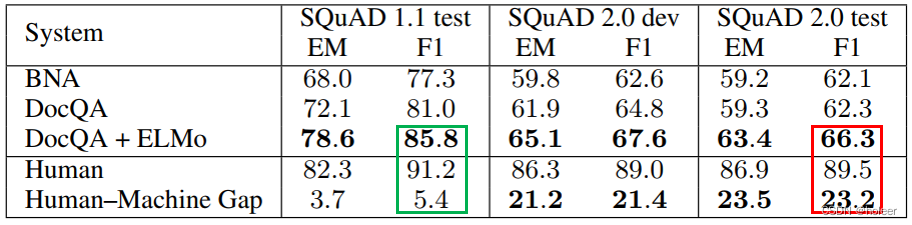
作者还给出了一个基线(可视为参考分数):如果模型对任何问题都放弃回答,则会得到48.9分。现有模型的表现更接近此基线,而不是人类表现。因此,在此任务上,模型尚有巨大的改进空间。
此外,作者还加入了模型在旧数据集上的表现。与旧数据集相比,新数据集上的人机差距要大得多,这说明:对于现有模型来说,新数据集要困难得多。(绿色框部分)
5.3 与含有自动生成反例的数据集比较
自动生成反例的方法,是否也可以产生(像新数据集这样富有)挑战性的数据集呢?
作者进行了第二组实验,将在旧数据集上训练的模型分别用TFIDF反例和RULEBASED反例增强,然后与新数据集上训练的模型对比。结果如下表所示。SQuAD 2.0 上的最高分,比其他两个数据集的最高分还要低15.4分,这表明自动生成的反例对于现有模型来说更容易检测。

六、讨论
关系提取系统必须理解文本何时不蕴含两个实体之间的可能关系。
而新数据集迫使模型去理解:段落是否蕴含着(某个文本范围是)问题的答案。做到这一点的模型可以在更深的层次上理解语言。
七、报告反馈(来自导师)
要重视数据集的收集、积累、分析。构建一个高质量的数据集也是一种重要的贡献,在构建完成之后应验证数据集的有效性。
参考资料
ACL 2018 | 最佳短论文SQuAD 2.0:斯坦福大学发布的机器阅读理解问答数据集
SQuAD —— text span答案类型开创者


















 4769
4769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









