







~学习模型把握三点:该模型的适用条件、该模型解决的问题、该模型的三要素
2.1 感知机模型
感知机是二类分类的 线性分类(存在某个超平面能够将数据集的正实例点和负实例点完全正确的分开) 模型。
- 其输入是实例的特征向量x。其中,
 ,
, 。X为特征空间,x为该特征空间内的某一特征向量。
。X为特征空间,x为该特征空间内的某一特征向量。 - 输出是实例的类别
 ,输出空间为
,输出空间为 。
。 - 是一种判别模型。
- 有输入空间到输出空间的函数为:
 ,w和b为感知机模型参数,w为权值/权值向量,b为偏置。(感知机学习旨在对数据进行线性划分,得到分离超平面;在二维中也就是找到一条直线将二类分开,这种情况下,w和b固定唯一一条直线)
,w和b为感知机模型参数,w为权值/权值向量,b为偏置。(感知机学习旨在对数据进行线性划分,得到分离超平面;在二维中也就是找到一条直线将二类分开,这种情况下,w和b固定唯一一条直线) 
2.2 感知机学习策略
损失函数是所有的误分类点到超平面的总距离。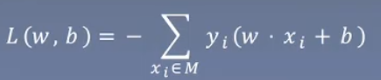
- 正确分类情况下,
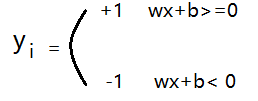 误分类情况下,
误分类情况下,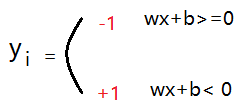
所以对于误分类的点,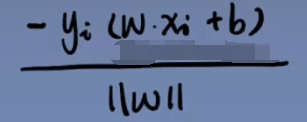 为单个误分类点到超平面的距离(分子恒大于0)。由于w的二范数为一个常数,对损失函数无影响,可直接写为L(w,b)的形式。
为单个误分类点到超平面的距离(分子恒大于0)。由于w的二范数为一个常数,对损失函数无影响,可直接写为L(w,b)的形式。
- 通过损失函数求出W和B的值 带入模型就行。
2.3 感知机学习算法
算法2.1 (随机梯度下降法——原始形式)

- 上述以伪代码形式展开讲解,易于理解。但要注意一下几点:(1)整体思路是先随便给一个超平面,然后查看有没有误分类点,若有则修改超平面至当前实例修正为正确分类点,直至结束。(2)需要考虑到在修正第n+1个误分类点时,是否又把其他的点误分类。(看书 p30例2.1的迭代过程)(3)当训练数据集线性可分时,感知机学习算法的迭代是收敛的(选择的初值,以及误分类点的选择顺序都会导致最终的超平面不同。(4)一个实例点被反复误分类的次数越多,说明他距离分离超平面越近,这样的实例点对学习结果影响很大。
算法2.2:(随机梯度下降法——对偶形式)
感知机模型的对偶形式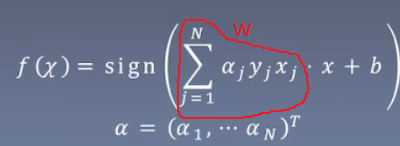 ,在这种情况下,假设空间由
,在这种情况下,假设空间由![]() 和b决定。
和b决定。
?至于为什么w和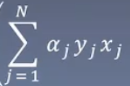 为什么等价没有想通。。。。
为什么等价没有想通。。。。

- 对偶行驶中训练实例仅以内积的形式出席那,可以预先将训练集中实例间的内积计算出来并以矩阵的形式存储,这个矩阵就是Gram矩阵。















 1040
1040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









