







感知机
这里先讲一些题外话,机器学习其实就是建立模型,通过一部分数据也就是所谓的训练集来构造函数模型,构造好就可以对新的输入实例进行直接分类,感知机模型自然也不例外。
一、感知机(perceptron)模型
1.感知机是神经网络和支持向量机的基础。
感知机属于分类模型,感知机模型其实就是对数据进行分类。所以,依据什么来分类?这是一个最关键的问题,感知机模型最重要的就是建立这个分类依据---分离超平面。
2.感知机模型:输入空间X属于n维空间向量
输出空间Y属于{+1,-1},故属于分类中的判别模型。
映射函数:f(x)=sign(w·x +b),这个映射函数就叫感知机。
其中,当x>=0时,sign(x)=+1;
当x<0时,sign(x)=-1.
所以,w·x+b=0就是这个分类超平面,是不是很熟悉,可以理解为其就是平面方程。故而,只要确定w和b值就可以解决这个问题。那如何才能找出更精确的w和b值,更合理的进行分类呢?这个问题至关重要。下面会给出解答。
二、感知机学习策略
首先给出一个前提条件,由于感知机模型最重要的是求这个分离超平面,所以它的输入数据集必须具有线性可分性,什么是线性可分?就是存在一个平面可以把数据集分为两部分。假如一个数据集全裹在一块,自然不能使用感知机模型来建模。
1.感知机(perceptron)学习策略:现在开始解决那个问题,找出最合理的w和b值。
最合理的w和b值,就应该可以将整体的分类损失误差降到最低,没毛病吧。那么问题又来了,如何来计算整体损失误差,这里我们需要定义一个损失函数。
2.我们这个需要明确一个问题,只有错误分类的点才有损失误差,对于正确分类的点的损失误差是0.所以,损失函数我们可以定义为,所有误分类点到那个分离超平面的总距离,这里总距离最小,也就是损失误差最小,也就是最合理的w和b值。
故点到平面的距离,都记得吧,w是这个平面的法向量,每一个点的损失为:
1
—————— |w·X+b|
| W |
而对于误分类的点(x,y)来说,-y(w·x+b)>0。因为其w·x+b>0时,y=-1;其w·x+b<0时,y=+1。而对所有误分类点,|w|值都一样,所以可以舍去这个值。
所以可以定义损失函数为
L(w,b)= -∑ y(w·x+b)
所以这个损失函数是非负的,我们只要将训练集不断适用于这个损失函数,直到其值最小,就可以得到w和b值。
三、感知机(perpetron)学习算法
感知机学习算法包括原始形式和对偶形式。
1.原始形式
误分类点(x,y)
我们要得到minL(w,b),对w求偏导:∧w= -∑ yx
对b求偏导:∧b= -∑ y
*****这里给出一个定理:如果函数F(a)在a处有定义并且可微,那么函数F(a)在a点沿着梯度相反的方向-∧F(a)是下降的,也就是假如b=a-m∧F(a),m>0时,有F(a)>F(b)。
这就是梯度下降法的定义。
故在本思考中,当w=w+yx时,新得到的L(w,b)的值就在减小。有一点需要提出的是,每一次加上一个误分类点(x,y)更新w使得L(w,b)值下降是肯定的,但并不是一次就能使所有误分类点的梯度都下降,而是一次随机选取一个误分类点使其梯度下降。这就是随机梯度下降法。
2.感知机学习算法的原始形式
输入:训练数据集T={(x1,y1),(x2,y2),(x3,y3),....,(xn,yn)},y∈{-1,+1},学习率η(0<η<=1)
输出:w,b;感知机模型f(x)=sign(w·x+b)
(1)选取初值w0,b0;
(2)在训练集中选取数据(xi,yi);
(3)如果yi(w·xi+b)<=0
w=w+ηyixi
b=b+ηyi, 这里的=为赋值符号
(4)转至(2),直至训练集中没有误分类点。
其实这种算法的本质就是,当一个实例点被误分类,即位于分离超平面的错误一侧时,则调整w,b值,使分离超平面向误分类点的一侧移动,以减少该误分类点与超平面间的距离,直至超平面越过该误分类点使其被正确分类。就是移动平面靠近误分类点,相对距离就减少,没有什么太高深的含义。
3.下面举一个例子实现该算法。
有一个训练数据集,正实例点x1=(3,3),x2=(4,3),负实例点x3=(1,1),试用感知机学习算法的原始形式求感知机模型f(x)=sign(w·x+b)。其中x=(x(1),x(2)).
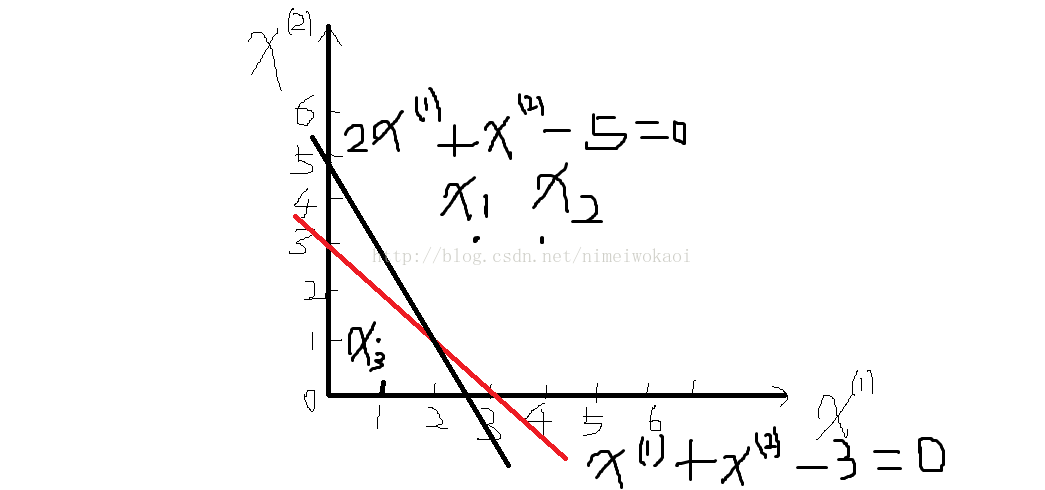
首先,构建最优化问题:
minL(w,b)= -∑ y(w·x+b),η=1
(1)取初值w0=0,b0=0.
(2)对x1=(3,3),y1=1,y1(w0·x+b0)=0,未能正确分类,所以更新w、b
w1=w0+y1x1=(3,3),
b1=b0+y1=1
所以得到线性模型
w1·x+b1=3x(1)+3x(2)+1
(3)对x1,x2,显然,y(w1·x+b1)>0,被正确分类,不修改w,b;
而对x3=(1,1),y3=-1,y3(w1·x+b1)<0,被误分类,更新w,b
w2=w1+y3x3=(2,2),
b2=b1+y3=0
又得到
w2·x+b2=2x(1)+2x(2).
(4)接下来对x3,w3=(1,1),b3=-1;
对x3,w4=(0,0),b4=-2
**
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









