







(未完待续,持续更新)
目录
对内存的虚拟化,可以理解为给各个Guest OS提供各自独立的HPA空间;HPA空间分为两部分,一部分是真正的物理内存,这是本文关注的核心点,另外一个部分是各种CPU寄存器、MMIO等。
目前,内存虚拟化主要有以下几种方式:
- Para-virtualization, VMM simply replaces the mapping v2p stored in a guest page table with the composite mapping v2m. For safety, the VMM needs to validate any updates to the page table by the guest OS. By taking back write permission on those memory pages used as the page table,the VMM prevents the guest OS from writing to any guest page table directly. The guest OS has to invoke hypercalls to the VMM to apply changes to its page table. XEN provides a representative hypervisor following this design

- Full-virtualization,A shadow page table maintained by the VMM maps virtual addresses directly to machine addresses while a guest maintains its own virtual to physical page table The VMM links the shadow page table to the MMU so most address translations can be done effectively. The VMM has to ensure that the content in the shadow page table is consistent with what in the guest page table. Since the guest OS does not know the existence of the shadow page table and will change its guest page table independently, the VMM should perform all the synchronization work to make the shadow page table keep up with the guest page table. Any updates to the shadow page table need also to be reflected in the guest page table. All these synchronizations will result in expensive VM exits and context switches.

- Hardware assisted,To avoid the synchronization cost in the shadow page mechanism, both Intel and AMD provide hardware assists, EPT (extended pagetable) and NPT (nested page table). With the hardware assists, the MMU maintains ordinary guest page tables that translate virtual addresses to guest physical addresses. In addition, the extended page table as provided by EPT translates from guest physical addresses to host physical or machine addresses.

KVM实现了shadow page table和基于EPT/NPT计数的tdp,接下来我们将进行详解。
几个相关概念:
- Nested Guest,虚拟机里面跑个虚拟机,这里不做深入解释,文档可以参考Nested EPT to Make Nested VMX Faster
 https://www.linux-kvm.org/images/8/8c/Kvm-forum-2013-nested-ept.pdf
https://www.linux-kvm.org/images/8/8c/Kvm-forum-2013-nested-ept.pdf - TDP,即Two Dimensional Paging,即Intel的 EPT技术,

- nopaging,X86_CR0_PG为0,参考手册:Paging (bit 31 of CR0) — Enables paging when set; disables paging when clear. When paging is disabled, all linear addresses are treated as physical addresses;
- long mode,即x86-64,参考连接Setting Up Long Mode - OSDev Wiki
https://wiki.osdev.org/Setting_Up_Long_ModeSince the introduction of the x86-64 processors a new mode has been introduced as well, which is called long mode. Long mode basically consists out of two sub modes which are the actual 64-bit mode and compatibility mode (32-bit, usually referred to as IA32e in the AMD64 manuals).
- pae,即physical address extension,It defines a page table hierarchy of three levels (instead of two), with table entries of 64 bits each instead of 32, allowing these CPUs to directly access a physical address space larger than 4G,参考连接:WIKI Physical Address Extensionhttps://en.wikipedia.org/wiki/Physical_Address_Extension
- page32,即x86-32;
1 Memory Slot
在QEMU + KVM中,HPA通过多个Memory Slot组合而成;
struct kvm_memory_slot {
gfn_t base_gfn;
unsigned long npages;
unsigned long *dirty_bitmap;
struct kvm_arch_memory_slot arch;
unsigned long userspace_addr;
u32 flags;
short id;
};关键成员:
- base_gfn/nrpages,对应的guest VM的physical address以及长度
- userspace_addr,guest VM的物理内存对应着一段qemu进程的匿名内存;参考qemu代码:
pc_init1() -> pc_memory_init() -> memory_region_init_ram() -> qemu_ram_alloc() -> qemu_ram_alloc_from_ptr() -> phys_mem_alloc qemu_anon_ram_alloc() --- void *ptr = mmap(0, total, PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0); --- - id,memory slot id,这个id来自用户态qemu;通过系统调用KVM_SET_USER_MEMORY_REGION
通过gfn,guest physical page frame number,我们可以索引到对应的memslot,函数如下:
search_memslots()
---
int slot = atomic_read(&slots->lru_slot);
struct kvm_memory_slot *memslots = slots->memslots;
// Latest used cache
if (gfn >= memslots[slot].base_gfn &&
gfn < memslots[slot].base_gfn + memslots[slot].npages)
return &memslots[slot];
// 二分法索引
while (start < end) {
slot = start + (end - start) / 2;
if (gfn >= memslots[slot].base_gfn)
end = slot;
else
start = slot + 1;
}
if (gfn >= memslots[start].base_gfn &&
gfn < memslots[start].base_gfn + memslots[start].npages) {
atomic_set(&slots->lru_slot, start);
return &memslots[start];
}
return NULL;
---在找到对应的memslot之后,我们通过 userspace_addr找到对应的host physical page;参考其中一个用例:
kvm_mmu_page_fault()
-> vcpu->arch.mmu->page_fault()
-> tdp_page_fault()
-> try_async_pf()
---
slot = kvm_vcpu_gfn_to_memslot(vcpu, gfn);
*pfn = __gfn_to_pfn_memslot(slot, gfn, false, &async, write, writable);
---
// The addr returned here is hva
addr = __gfn_to_hva_many(slot, gfn, NULL, write_fault);
return hva_to_pfn(addr, atomic, async, write_fault, writable);
-> hva_to_pfn_slow()
-> get_user_pages_unlocked()
---
---
-> __direct_map()在虚拟化系统中,我们通常会有gva、gpa和hpa;此处还引入了hva,即qemu进程的地址,通过其地址空间维护其分配给guest VM的内存。
2 Shadow Page Table
2.1 概述
KVM的初始paper中,首先对MMU的基本功能做了一个基本概述,如下:
kvm: the Linux Virtual Machine Monitor![]() http://course.ece.cmu.edu/~ece845/sp13/docs/kvm-paper.pdf
http://course.ece.cmu.edu/~ece845/sp13/docs/kvm-paper.pdf
- A radix tree ,the page table, encoding the virtualto-physical translation. This tree is provided by system software on physical memory, but is rooted in a hardware register (the cr3 register);
- A mechanism to notify system software of missing translations (page faults)
- An on-chip cache (the translation lookaside buffer, or tlb) that accelerates lookups of the page table
- Instructions for switching the translation root in order to provide independent address spaces
- Instructions for managing the tlb
第一代Intel VMX并没有直接提供内存虚拟化的功能,而是提供以下功能,对MMU的关键时间进行了拦截:参考Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C & 3D): System Programming Guide![]() https://courses.cs.washington.edu/courses/cse481a/18wi/readings/sdm-3.pdf
https://courses.cs.washington.edu/courses/cse481a/18wi/readings/sdm-3.pdf
- Primary processor-based VM-execution controls(VMCS 00004002H),参考<24.6.2 Processor-Based VM-Execution Controls>,
Bit Position(s)
Name
Description
9
INVLPG exiting
This determines whether executions of INVLPG cause VM exits.
15
CR3-load exiting
In conjunction with the CR3-target controls (see Section 24.6.7), this control determines whether executions of MOV to CR3 cause VM exits. See Section 25.1.3.
The first processors to support the virtual-machine extensions supported only the 1-setting of this control.
16
CR3-store exiting
This control determines whether executions of MOV from CR3 cause VM exits.
The first processors to support the virtual-machine extensions supported only the 1-setting of this control.
- Exception bitmap (VMCS 00004004H), 参考<24.6.3 Exception Bitmap>和<6.15 EXCEPTION AND INTERRUPT REFERENCE>,
- The exception bitmap is a 32-bit field that contains one bit for each exception. When an exception occurs, its vector is used to select a bit in this field. If the bit is 1, the exception causes a VM exit. If the bit is 0, the exception is delivered normally through the IDT, using the descriptor corresponding to the exception’s vector;
- Interrupt 14—Page-Fault Exception (#PF)
相关的VM-Exit的相关信息,参考<27.2.1 Basic VM-Exit Information>,
- Exit qualification(VMCS 00006400H),不同场景下:
- For a page-fault exception, the exit qualification contains the linear address that caused the page fault. On processors that support Intel 64 architecture, bits 63:32 are cleared if the logical processor was not in 64- bit mode before the VM exit;
- For INVLPG, the exit qualification contains the linear-address operand of the instruction
- Guest-linear address (VMCS 0000640AH),这个VMCS域的名字很有迷惑性,其实常见的page fault场景,并不会用到它,
- VM exits due to attempts to execute LMSW with a memory operand
- VM exits due to attempts to execute INS or OUTS for which the relevant segment is usable
基于这些功能,KVM实现了Shadow Page Table,即通过拦截Guest OS的页表操作,建立起

Shadow Page Table设置到CR3,完成GVA -> HPA的转化。
其中有以下要点:
- SPT包含的是GVA->HPA,所以,需要维护多份SPT;每当Guest OS发生地址空间切换时,即设置CR3时,需要进行拦截,并切换SPT
- 保证Guest OS的页表与SPT的一致,这里主要包括两个机制:
- 对Level 1以上页表使用write-protect,追踪其写更新;
- 对Level 1的页表利用INVLPG机制保证同步;
详情情况,参考接下里的几个小节。
2.2 SPT切换
Guest OS中,每个进程都有一个独立的地址空间,即一套单独的GVA->GPA mapping;Shadow Page Table是做GVA->HPA的mapping,那么每个进程都有一个SPT。那么在一个KVM上下文中,总共会有多少个SPT?参考以下函数:
kvm_set_cr3()
---
if (cr3 == kvm_read_cr3(vcpu) && !pdptrs_changed(vcpu)) {
if (!skip_tlb_flush) {
kvm_mmu_sync_roots(vcpu);
kvm_make_request(KVM_REQ_TLB_FLUSH, vcpu);
}
return 0;
}
...
kvm_mmu_new_cr3(vcpu, cr3, skip_tlb_flush);
vcpu->arch.cr3 = cr3;
---
kvm_mmu_new_cr3()
-> __kvm_mmu_new_cr3()
-> fast_cr3_switch()
-> cached_root_available()
---
root.cr3 = mmu->root_cr3;
root.hpa = mmu->root_hpa;
// #define KVM_MMU_NUM_PREV_ROOTS 3
for (i = 0; i < KVM_MMU_NUM_PREV_ROOTS; i++) {
这里有一个简单的老化算法:
CURRENT PREV[0] PREV[1] PREV[2] ---> FREE !!!
\________^ \_________^ \________^
swap(root, mmu->prev_roots[i]);
if (new_cr3 == root.cr3 && VALID_PAGE(root.hpa) &&
page_header(root.hpa) != NULL &&
new_role.word == page_header(root.hpa)->role.word)
break;
}
mmu->root_hpa = root.hpa;
mmu->root_cr3 = root.cr3;
---
-> kvm_mmu_free_roots() //KVM_MMU_ROOT_CURRENT在最后一个PREV SPT被释放之后,会为新的cr3申请一个新的,参考代码:
vcpu_enter_guest()
-> kvm_mmu_reload()
-> kvm_mmu_load()
-> mmu_alloc_shadow_roots()
---
sp = kvm_mmu_get_page(vcpu, root_gfn, 0,
vcpu->arch.mmu->shadow_root_level, 0, ACC_ALL);
root = __pa(sp->spt);
vcpu->arch.mmu->root_hpa = root;
---
-> kvm_mmu_load_cr3()
-> vcpu->arch.mmu->set_cr3(vcpu, vcpu->arch.mmu->root_hpa | kvm_get_active_pcid(vcpu));
-> vmx_set_cr3()
---
//This CR3 will be loaded when VM-Entry
vmcs_writel(GUEST_CR3, guest_cr3);
---
-> kvm_x86_ops->run(vcpu)同时,上述代码还包括了cr3的load的过程。
2.3 Write-protect
KVM x86 shadow page table的write-protect的建立的过程大致如下:

接来下,我们将从代码的角度解释这个过程;
KVM x86使用kvm_mmu_page来代表需要write-protect的page,或者说guest OS page table所在page;其中比较重要的成员有
- gfn,对应的Guest OS page table page的gfn
- spt,指向一个单独申请的page,对应就是spt的page,参与构建shadow page table
- gfns,指向一个单独申请的page,保存这其中spt中页表项对应的gpa
上图中的Step 2对应代码为(代码只保留了与上下文强相关的部分):
Guest OS发生page fault,并VM-Exit,并最终进入paging64_page_fault
// VM-exit reason handle
handle_exception()
-> kvm_handle_page_fault()
-> kvm_mmu_page_fault()
-> vcpu->arch.mmu->page_fault()
arch/x86/kvm/paging_tmpl.h FNAME(page_fault)
---
r = FNAME(walk_addr)(&walker, vcpu, addr, error_code);
if (try_async_pf(vcpu, prefault, walker.gfn, addr, &pfn, write_fault,
&map_writable))
return RET_PF_RETRY;
r = FNAME(fetch)(vcpu, addr, &walker, write_fault,
level, pfn, map_writable, prefault, lpage_disallowed);
---paging64_page_fault中三个核心步骤,
- walk_addr,索引Guest OS的页表中与本次page fault gva相关的各级页表项,参考代码:
arch/x86/kvm/paging_tmpl.h FNAME(walk_addr) --- walker->level = mmu->root_level; //通过cr3获取页表root pte = mmu->get_cr3(vcpu); ... do { index = PT_INDEX(addr, walker->level); table_gfn = gpte_to_gfn(pte); offset = index * sizeof(pt_element_t); pte_gpa = gfn_to_gpa(table_gfn) + offset; walker->table_gfn[walker->level - 1] = table_gfn; walker->pte_gpa[walker->level - 1] = pte_gpa; //对于非nested场景,该函数返回原gpa real_gfn = mmu->translate_gpa(vcpu, gfn_to_gpa(table_gfn), nested_access,&walker->fault); real_gfn = gpa_to_gfn(real_gfn); //通过memslot,将gpa转换为hva,即qemu的用户态地址 host_addr = kvm_vcpu_gfn_to_hva_prot(vcpu, real_gfn, &walker->pte_writable[walker->level - 1]); //从qemu用户态拷贝页表项 ptep_user = (pt_element_t __user *)((void *)host_addr + offset); if (unlikely(__copy_from_user(&pte, ptep_user, sizeof(pte)))) goto error; walker->ptep_user[walker->level - 1] = ptep_user; ... walker->ptes[walker->level - 1] = pte; } while (!is_last_gpte(mmu, walker->level, pte)); --- - try_async_pf,获取gfn对应的pfn,即hpa
try_async_pf() --- slot = kvm_vcpu_gfn_to_memslot(vcpu, gfn); *pfn = __gfn_to_pfn_memslot(slot, gfn, false, &async, write, writable); --- // The addr returned here is hva addr = __gfn_to_hva_many(slot, gfn, NULL, write_fault); return hva_to_pfn(addr, atomic, async, write_fault, writable); -> hva_to_pfn_slow() -> get_user_pages_unlocked() --- --- - paging64_fetch(),该函数会建立spt,参考代码:
arch/x86/kvm/paging_tmpl.h FNAME(fetch) --- for (shadow_walk_init(&it, vcpu, addr); shadow_walk_okay(&it) && it.level > gw->level; shadow_walk_next(&it)) { ... if (!is_shadow_present_pte(*it.sptep)) { table_gfn = gw->table_gfn[it.level - 2]; sp = kvm_mmu_get_page(vcpu, table_gfn, addr, it.level-1, false, access); --- if (!direct) // direct is false account_shadowed(vcpu->kvm, sp); -> kvm_slot_page_track_add_page() // This page will be write-protect --- } if (sp) link_shadow_page(vcpu, it.sptep, sp); } gfn = gw->gfn | ((addr & PT_LVL_OFFSET_MASK(gw->level)) >> PAGE_SHIFT); base_gfn = gfn; ... ret = mmu_set_spte(vcpu, it.sptep, gw->pte_access, write_fault, it.level, base_gfn, pfn, prefault, map_writable); ---在为page fault addr建立spt的过程中,会依次建立各个层级的spte,并进行track;
track机制基于kvm_arch_memory_slot.gfn_track,memory slot中每个page一个u16,参考代码注释:
add guest page to the tracking pool so that corresponding access on that page will be intercepted;
Track在如下位置被建立:
kvm_mmu_get_page()
-> account_shadowed() // for shadow page table case
---
/* the non-leaf shadow pages are keeping readonly. */
if (sp->role.level > PT_PAGE_TABLE_LEVEL)
return kvm_slot_page_track_add_page(kvm, slot, gfn,
KVM_PAGE_TRACK_WRITE);
---
-> update_gfn_track()
-> slot->arch.gfn_track[mode][index] += count;Step 3中的过程与Step2基本相同;唯一不同的在mmu_set_spte()中,参考代码:
mu_set_spte()
-> set_spte()
---
if (pte_access & ACC_WRITE_MASK) {
...
spte |= PT_WRITABLE_MASK | SPTE_MMU_WRITEABLE;
...
if (mmu_need_write_protect(vcpu, gfn, can_unsync)) {
ret |= SET_SPTE_WRITE_PROTECTED_PT;
pte_access &= ~ACC_WRITE_MASK;
spte &= ~(PT_WRITABLE_MASK | SPTE_MMU_WRITEABLE);
}
}
---
mmu_need_write_protect()
---
if (kvm_page_track_is_active(vcpu, gfn, KVM_PAGE_TRACK_WRITE))
return true;
---在建立起write-protect和track之后, 所有的guest OS对页表的更新都会被trap,参考代码:
paging_page_fault()/tdp_page_fault()
---
if (page_fault_handle_page_track(vcpu, error_code, walker.gfn)) {
shadow_page_table_clear_flood(vcpu, addr);
return RET_PF_EMULATE;
}
--
segmented_write()
-> .write_emulated()
emulator_read_write()
-> emulator_read_write_onepage()
-> write_emulate()
-> emulator_write_phys()
-> kvm_page_track_write()
---
head = &vcpu->kvm->arch.track_notifier_head;
if (hlist_empty(&head->track_notifier_list))
return;
idx = srcu_read_lock(&head->track_srcu);
hlist_for_each_entry_rcu(n, &head->track_notifier_list, node)
if (n->track_write)
n->track_write(vcpu, gpa, new, bytes, n);
srcu_read_unlock(&head->track_srcu, idx);
---
kvm_mmu_init_vm()
---
node->track_write = kvm_mmu_pte_write;
node->track_flush_slot = kvm_mmu_invalidate_zap_pages_in_memslot;
kvm_page_track_register_notifier(kvm, node);
---
kvm_mmu_pte_write()
---
if (!READ_ONCE(vcpu->kvm->arch.indirect_shadow_pages))
return;
// From gpa to kvm_mmu_page, gfn will be checked in macro below
for_each_gfn_indirect_valid_sp(vcpu->kvm, sp, gfn) {
...
}
---大体分为两部分:
- 在指令模拟部分,将更新写入Guest OS的page table
- 将相关更新同步到shadow page table
2.4 Unsync SPT
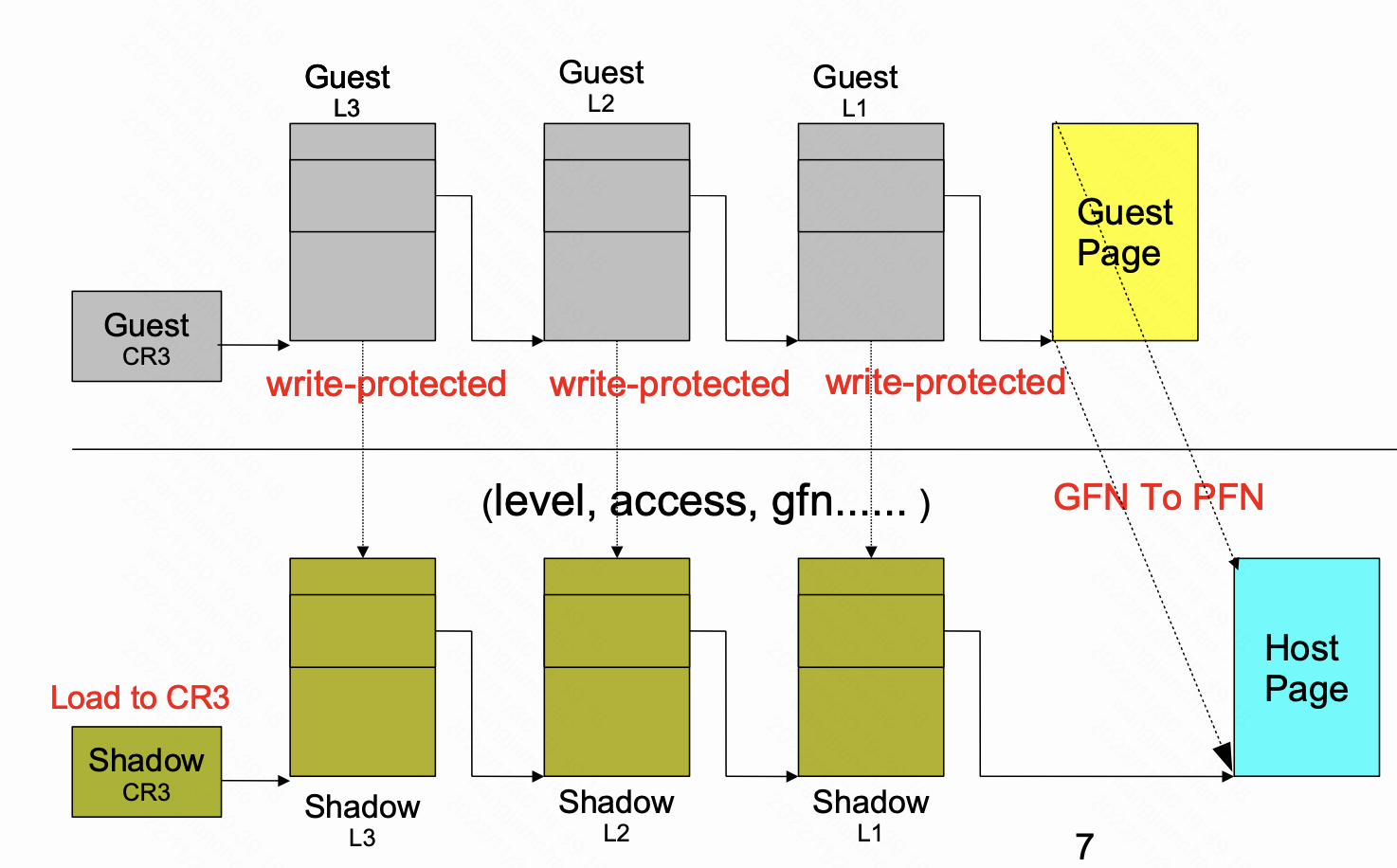
通过write-protect Guest OS page table来实现shadow page table的同步;为了降低VM-Exit,unsync shadow page被引入,引用链接中的内容:
For the performance reason, we allow the guest page table to be writable if and only if the page is the last level page-structure (Level 1). Base on TLB rules:
- We need to flush TLB to ensure the translation use the modified page structures, then we can Intercept the TLB flush operations and sync shadow pages
- Sometimes, TLB is not need to be flushed(old PTE.P = 0, PTE.A=0, raise access permission), then it can be synced though page fault
参考代码中判断shadow page需要进行track的逻辑:
kvm_mmu_get_page()
-> account_shadowed()
---
/* the non-leaf shadow pages are keeping readonly. */
if (sp->role.level > PT_PAGE_TABLE_LEVEL)
return kvm_slot_page_track_add_page(kvm, slot, gfn,
KVM_PAGE_TRACK_WRITE);
---对于level 1的sp,处理如下:
mmu_set_spte()
-> set_spte() // can_unsync = true
-> mmu_need_write_protect()
---
if (kvm_page_track_is_active(vcpu, gfn, KVM_PAGE_TRACK_WRITE))
return true;
for_each_gfn_indirect_valid_sp(vcpu->kvm, sp, gfn) {
if (!can_unsync)
return true;
if (sp->unsync)
continue;
kvm_unsync_page(vcpu, sp);
-> sp->unsync = 1
-> kvm_mmu_mark_parents_unsync()
}
---
handle_invlpg()
-> kvm_mmu_invlpg()
-> FNAME(invlpg)()
---
for_each_shadow_entry_using_root(vcpu, root_hpa, gva, iterator) {
level = iterator.level;
sptep = iterator.sptep;
sp = page_header(__pa(sptep));
if (is_last_spte(*sptep, level)) {
pt_element_t gpte;
gpa_t pte_gpa;
if (!sp->unsync)
break;
pte_gpa = FNAME(get_level1_sp_gpa)(sp);
pte_gpa += (sptep - sp->spt) * sizeof(pt_element_t);
...
if (kvm_vcpu_read_guest_atomic(vcpu, pte_gpa, &gpte,
sizeof(pt_element_t)))
break;
FNAME(update_pte)(vcpu, sp, sptep, &gpte);
}
if (!is_shadow_present_pte(*sptep) || !sp->unsync_children)
break;
}
---3 Two Demensional Page Table
3.1 概述
在Intel发布的第二代虚拟化拓展中,引入了EPT功能,extended page table,它会给MMU提供另外一个page table,里面保存的是GPA->HPA的mapping;通过此功能,VMM不需要再维护shadow page table以及维护它与Guest OS内page table的同步;但是,另外一层的page table,会增加tlb miss的开销,因为完成一次GVA->HPA的转化又多了一层page table。
注:shadow page table维护的是GPA->HPA的映射,这个映射是全局的,而不是进程级的,所以,VMM也不需要像之前一样维护多份页表了。
Performance Evaluation of Intel EPT Hardware Assist![]() https://www.vmware.com/pdf/Perf_ESX_Intel-EPT-eval.pdf上面的文档中,提供了Intel EPT技术的性能benchmark;引用其中的一段结论,其说明了TDP技术的收益,
https://www.vmware.com/pdf/Perf_ESX_Intel-EPT-eval.pdf上面的文档中,提供了Intel EPT技术的性能benchmark;引用其中的一段结论,其说明了TDP技术的收益,
Under shadow paging, in order to provide transparent MMU virtualization the VMM intercepted guest page table updates to keep the shadow page tables coherent with the guest page tables. This caused some overhead in the virtual execution of those applications for which the guest had to frequently update its page table structures.
With the introduction of EPT, the VMM can now rely on hardware to eliminate the need for shadow page tables. This removes much of the overhead otherwise incurred to keep the shadow page tables up-to-date
在需要频繁更新页表的benchmark中,EPT技术有很大的性能提升,

而在另外一个,MMU操作很少的测试中,EPT技术甚至比SPP还有性能下降,参考下图:

3.2 Intel EPT
EPT相关介个VMCS域:
- Guest-physical address (VMCS 00002400H),For a VM exit due to an EPT violation or an EPT misconfiguration, this field receives the guest-physical address that caused the EPT violation or EPT misconfiguration. For all other VM exits, the field is undefined.
-
EPT pointer(VMCS 0000201AH),
28.2.2 EPT Translation Mechanism
The EPT translation mechanism use only 47:0 bits of guest physical address. It uses a page-walk length of 4, meaning that at most 4 EPT paging-structure entries are accessed to translate a guest-physical address.
即EPT技术使用了GPA的48Bits,总共可以寻址256T的内存空间,这对于虚拟机来说足够了(现阶段的确如此),另外,EPT页表总共四层,其格式和寻址方式如下:
![]()
PTE的Bit7为1,则表示该PTE指向的是一块内存,可能是1G/2M/4K,取决于它所在的Level;如果为0,则代表指向的是Page Directory,即下一级页表;当PTE指向一块内存时,Bit (6:3)表示的其访问方式,0 = UC 1 = WC 4 = WT 5 = WP 6 = WB,关于Cache的类型,这里说的非常清楚:Intel-x86:The interaction between WC, WB and UC Memory - Stack Overflow

- UC, uncache, writes go directly to the physical address space and reads come directly from the physical address space.
- WC, write-combine, writes go down to "write combining buffer" where they're combined with previous writes and eventually evicted from the buffer (and sent to the physical address space later). Reads from WC come directly from the the physical address space.
- WB, write-back, writes go to caches and are evicted from the caches (and sent to the physical address space) later. WT, write-through writes go to both caches and the physical address space at the same time. WP, write-protect writes get discarded and don't reach the physical address space at all. For all of these, reads come from cache (and cause fetch from the physical address space into cache on "cache miss").
3.3 TDP如何工作
TDP依赖EPT等硬件提供的机制,通过增加一个新的page table来完成GPA到HPA的转化,那么,对于所有的Guest OS里的任务来说,ept页表都是一样的;所以,在切换cr3时,kvm不需要做任何拦截处理,参考代码:
vmx_vcpu_setup()
-> vmcs_write32(CPU_BASED_VM_EXEC_CONTROL, vmx_exec_control(vmx));
-> vmx_exec_control()
---
u32 exec_control = vmcs_config.cpu_based_exec_ctrl;
if (!enable_ept)
exec_control |= CPU_BASED_CR3_STORE_EXITING |
CPU_BASED_CR3_LOAD_EXITING |
CPU_BASED_INVLPG_EXITING;
---kvm直接disable了cr3-store/load-exit。
handle_ept_violation()/handle_ept_violation()
---
gpa = vmcs_read64(GUEST_PHYSICAL_ADDRESS);
return kvm_mmu_page_fault(vcpu, gpa, error_code, NULL, 0);
---
kvm_mmu_page_fault()
-> vcpu->arch.mmu->page_fault()
-> tdp_page_fault()
-> try_async_pf()
---
slot = kvm_vcpu_gfn_to_memslot(vcpu, gfn);
*pfn = __gfn_to_pfn_memslot(slot, gfn, false, &async, write, writable);
---
// The addr returned here is hva
addr = __gfn_to_hva_many(slot, gfn, NULL, write_fault);
return hva_to_pfn(addr, atomic, async, write_fault, writable);
-> hva_to_pfn_slow()
-> get_user_pages_unlocked()
---
---
-> __direct_map()
__direct_map()使用的参数是gpa
__direct_map()
---
// ept page table的遍历过程是在for_each_shadow_entry中完成的
for_each_shadow_entry(vcpu, gpa, it) {
base_gfn = gfn & ~(KVM_PAGES_PER_HPAGE(it.level) - 1);
if (it.level == level)
break;
if (!is_shadow_present_pte(*it.sptep)) {
sp = kvm_mmu_get_page(vcpu, base_gfn, it.addr,
it.level - 1, true, ACC_ALL);
link_shadow_page(vcpu, it.sptep, sp);
}
}
ret = mmu_set_spte(vcpu, it.sptep, ACC_ALL,
write, level, base_gfn, pfn, prefault,
map_writable);
---
4 Huge Page
KVM Memory的虚拟化支持大页,包括tlb hugepage和transparent hugepage;参考代码:
- tlb hugepage,参考代码:
tdp_page_fault() -> mapping_level() -> host_mapping_level() --- page_size = kvm_host_page_size(kvm, gfn); for (i = PT_PAGE_TABLE_LEVEL; i <= PT_MAX_HUGEPAGE_LEVEL; ++i) { if (page_size >= KVM_HPAGE_SIZE(i)) ret = i; else break; } --- kvm_host_page_size() -> vma_kernel_pagesize() --- if (vma->vm_ops && vma->vm_ops->pagesize) return vma->vm_ops->pagesize(vma); hugetlb_vm_op_pagesize() ^^^^^^^^^^^^^^^^^^^^^^^^ return PAGE_SIZE; --- - THP,参考代码:
tdp_page_fault() -> transparent_hugepage_adjust() --- if (!is_error_noslot_pfn(pfn) && !kvm_is_reserved_pfn(pfn) && level == PT_PAGE_TABLE_LEVEL && PageTransCompoundMap(pfn_to_page(pfn)) && !mmu_gfn_lpage_is_disallowed(vcpu, gfn, PT_DIRECTORY_LEVEL)) { ... *levelp = level = PT_DIRECTORY_LEVEL; mask = KVM_PAGES_PER_HPAGE(level) - 1; if (pfn & mask) { kvm_release_pfn_clean(pfn); pfn &= ~mask; kvm_get_pfn(pfn); *pfnp = pfn; } } ---
另外,shadow page table所在的位置不允许有huge page,kvm使用kvm_arch_memory_slot.lpageinfo保存相关信息;
kvm_mmu_get_page()
-> account_shadowed()
-> kvm_mmu_gfn_disallow_lpage()
---
for (i = PT_DIRECTORY_LEVEL; i <= PT_MAX_HUGEPAGE_LEVEL; ++i) {
linfo = lpage_info_slot(gfn, slot, i);
linfo->disallow_lpage += count;
}
---
5 Dirty log
Dirty log用于实现Live-Migration的基础技术,参考连接: KVM Live Migration![]() https://www.linux-kvm.org/images/5/5a/KvmForum2007%24Kvm_Live_Migration_Forum_2007.pdf
https://www.linux-kvm.org/images/5/5a/KvmForum2007%24Kvm_Live_Migration_Forum_2007.pdf
qemu/kvm dirty pages tracking in migrationdirty page tracking![]() https://terenceli.github.io/%E6%8A%80%E6%9C%AF/2018/08/11/dirty-pages-tracking-in-migration
https://terenceli.github.io/%E6%8A%80%E6%9C%AF/2018/08/11/dirty-pages-tracking-in-migration
Live Migrating QEMU-KVM Virtual Machines | Red Hat DeveloperLive migrating virtual machines is an interesting ongoing topic for virtualization: guests keep getting bigger (more vCPUs, more RAM), and demands on the uptimehttps://developers.redhat.com/blog/2015/03/24/live-migrating-qemu-kvm-virtual-machines#stages_in_live_migration__continued_Diryt log用于追踪那么memory是脏的,在热迁移的过程中,内存的迁移过程如下:
- First transfer all memory pages (first iteration)
- For every next iteration i, transfer all dirty pages of iteration i - 1
- Stop when some low watermark or condition reached
- Stop guest, transfer remaining dirty RAM,
dirty log有两种实现方式,
第一种是,纯软件的write-protect,比如:
kvm_mmu_slot_apply_flags()
-> kvm_mmu_slot_remove_write_access()
-> slot_handle_all_level(kvm, memslot, slot_rmap_write_protect, false)
-> slot_rmap_write_protect()
-> spte_write_protect()
tdp_page_fault()
-> fast_page_fault()
-> fast_pf_fix_direct_spte()
---
if (is_writable_pte(new_spte) && !is_writable_pte(old_spte)) {
gfn = kvm_mmu_page_get_gfn(sp, sptep - sp->spt);
kvm_vcpu_mark_page_dirty(vcpu, gfn);
}
---另一种是,基于PML,即Page Modify Log,参考Intel手册,28.2.5 Page-Modification Logging,其具体的工作方式如下:
When accessed and dirty flags for EPT are enabled, software can track writes to guest-physical addresses using a feature called page-modification logging.
Before allowing a guest-physical access, the processor may determine that it first needs to set an accessed or dirty flag for EPT (see Section 28.2.4). When this happens, the processor examines the PML index. If the PML index is not in the range 0–511, there is a page-modification log-full event and a VM exit occurs. In this case, the accessed or dirty flag is not set, and the guest-physical access that triggered the event does not occur.
If instead the PML index is in the range 0–511, the processor proceeds to update accessed or dirty flags for EPT as described in Section 28.2.4. If the processor updated a dirty flag for EPT (changing it from 0 to 1), it then operates as follows:
The guest-physical address of the access is written to the page-modification log. Specifically, the guest-physical address is written to physical address determined by adding 8 times the PML index to the PML address.
Bits 11:0 of the value written are always 0 (the guest-physical address written is thus 4-KByte aligned).The PML index is decremented by 1 (this may cause the value to transition from 0 to FFFFH).
参考代码,
vmx_handle_exit()
---
/*
* Flush logged GPAs PML buffer, this will make dirty_bitmap more
* updated. Another good is, in kvm_vm_ioctl_get_dirty_log, before
* querying dirty_bitmap, we only need to kick all vcpus out of guest
* mode as if vcpus is in root mode, the PML buffer must has been
* flushed already.
*/
if (enable_pml)
vmx_flush_pml_buffer(vcpu);
---
vmx_flush_pml_buffer()
---
pml_idx = vmcs_read16(GUEST_PML_INDEX);
/* Do nothing if PML buffer is empty */
if (pml_idx == (PML_ENTITY_NUM - 1))
return;
/* PML index always points to next available PML buffer entity */
if (pml_idx >= PML_ENTITY_NUM)
pml_idx = 0;
else
pml_idx++;
pml_buf = page_address(vmx->pml_pg);
for (; pml_idx < PML_ENTITY_NUM; pml_idx++) {
u64 gpa;
gpa = pml_buf[pml_idx];
WARN_ON(gpa & (PAGE_SIZE - 1));
kvm_vcpu_mark_page_dirty(vcpu, gpa >> PAGE_SHIFT);
}
---有趣的是,PML似乎只支持4K aligned的page,在Intel VMX开启dirty log时,对所有的large page都做了write-protect,
vmx_slot_enable_log_dirty()
-> kvm_mmu_slot_largepage_remove_write_access()
-> slot_handle_level_range()
-> slot_handle_level(kvm, memslot, fn, PT_PAGE_TABLE_LEVEL + 1,
PT_MAX_HUGEPAGE_LEVEL, lock_flush_tlb);
6 MMIO
6.1 概述
MMIO,即memory map IO,对应的是PIO,即通过IN/OUT指令访问IO port的programed IO;参考/proc/iomem,
....
76000000-8fffffff : Reserved
80000000-8fffffff : PCI MMCONFIG 0000 [bus 00-ff]
...
9d800000-aaffffff : PCI Bus 0000:17
9e000000-a32fffff : PCI Bus 0000:18
9e000000-a32fffff : PCI Bus 0000:19
9e000000-a32fffff : PCI Bus 0000:1a
9e000000-9effffff : 0000:1a:00.3
9e000000-9effffff : i40e
9f000000-9fffffff : 0000:1a:00.2
9f000000-9fffffff : i40e
a0000000-a0ffffff : 0000:1a:00.1
a0000000-a0ffffff : i40e
a1000000-a1ffffff : 0000:1a:00.0
a1000000-a1ffffff : i40e
...
ab000000-b87fffff : PCI Bus 0000:3a
ab000000-ab0fffff : PCI Bus 0000:3b
ab000000-ab01ffff : 0000:3b:00.0
ab020000-ab02ffff : 0000:3b:00.0
ab020000-ab02ffff : nvme
ab030000-ab033fff : 0000:3b:00.0
ab030000-ab033fff : nvme
ab100000-ab100fff : 0000:3a:05.4
...
fec18000-fec183ff : IOAPIC 4
fec20000-fec203ff : IOAPIC 5
fec28000-fec283ff : IOAPIC 6
....
fee00000-feefffff : pnp 00:01
fee00000-feefffff : pnp 00:03
fee00000-fee00fff : Local APIC
....
100000000-207fffffff : System RAM
b82600000-b832013d0 : Kernel code
b832013d1-b83a134bf : Kernel data
b83fd6000-b845fffff : Kernel bss
d0000000000-d0fffffffff : PCI Bus 0000:00
参考以上,其包含以下集中地址空间:
- System RAM,系统内存,对应的是4G - 130G,其中包含了内核的code、data和bss;
- Local APIC,对应的是系统寄存器,具体可以参考 Intel® 64 and IA-32 Architectures Developer's Manual: Vol. 3A Table 10-1 Local APIC Register Address Map
- PCI Bus及其对应设备,这就是通过BAR设置给外设的地址空间;
- PCI MMCONFIG,PCI Configuration Space对应的空间,256M
software通过MMIO,访问CPU系统资源或者外设的寄存器。
6.2 Trap MMIO
QEMU并不会为MMIO的GPA建立memory slot,参考代码:
void memory_region_init_io(MemoryRegion *mr,
Object *owner,
const MemoryRegionOps *ops,
void *opaque,
const char *name,
uint64_t size)
{
memory_region_init(mr, owner, name, size);
mr->ops = ops;
mr->opaque = opaque;
mr->terminates = true;
mr->ram_addr = ~(ram_addr_t)0;
}
void memory_region_init_ram(MemoryRegion *mr,
Object *owner,
const char *name,
uint64_t size)
{
memory_region_init(mr, owner, name, size);
mr->ram = true;
mr->terminates = true;
mr->destructor = memory_region_destructor_ram;
mr->ram_addr = qemu_ram_alloc(size, mr);
}
kvm_init()
-> memory_listener_register()
-> listener_add_address_space()
-> listener->region_add()
kvm_region_add()
-> kvm_set_phys_mem()
kvm_set_phys_mem()
---
if (!memory_region_is_ram(mr)) {
if (writeable || !kvm_readonly_mem_allowed) {
return;
} else if (!mr->romd_mode) {
/* If the memory device is not in romd_mode, then we actually want
* to remove the kvm memory slot so all accesses will trap. */
add = false;
}
}
...
if (!add) {
return;
}
mem = kvm_alloc_slot(s);
mem->memory_size = size;
mem->start_addr = start_addr;
mem->ram = ram;
mem->flags = kvm_mem_flags(s, log_dirty, readonly_flag);
err = kvm_set_user_memory_region(s, mem);
---在kvm内核态,对于没有memory slot的gfn的处理如下:
如果memsslot中不包含对应的gfn,则slot为空
__gfn_to_memslot()
---
unsigned long addr = __gfn_to_hva_many(slot, gfn, NULL, write_fault); // return KVM_HVA_ERR_BAD if slot is NULL
...
if (kvm_is_error_hva(addr)) {
if (writable)
*writable = false;
return KVM_PFN_NOSLOT;
}
---
在设置spte时,对于pfn是KVM_PFN_NOSLOT的情况,有特殊处理:
set_spte()
---
if (set_mmio_spte(vcpu, sptep, gfn, pfn, pte_access))
return 0;
---
set_mmio_spte()
---
if (unlikely(is_noslot_pfn(pfn))) {
mark_mmio_spte(vcpu, sptep, gfn, access);
return true;
}
---
mark_mmio_spte()
---
...
u64 gpa = gfn << PAGE_SHIFT;
access &= shadow_mmio_access_mask;
mask |= shadow_mmio_value | access;
...
mmu_spte_set(sptep, mask);
---
spte被设置进了特殊的值对于MMIO对应的gfn,其对应的spte会被设置为特殊的值,主要有两种情况:
- 对于非EPT场景,
kvm_set_mmio_spte_mask() --- int maxphyaddr = boot_cpu_data.x86_phys_bits; /* * Set the reserved bits and the present bit of an paging-structure * entry to generate page fault with PFER.RSV = 1. */ /* * Mask the uppermost physical address bit, which would be reserved as * long as the supported physical address width is less than 52. */ mask = 1ull << 51; /* Set the present bit. */ mask |= 1ull; /* * If reserved bit is not supported, clear the present bit to disable * mmio page fault. */ if (IS_ENABLED(CONFIG_X86_64) && maxphyaddr == 52) mask &= ~1ull; kvm_mmu_set_mmio_spte_mask(mask, mask, ACC_WRITE_MASK | ACC_USER_MASK); --- kvm_handle_page_fault() -> kvm_mmu_page_fault() --- if (unlikely(error_code & PFERR_RSVD_MASK)) { r = handle_mmio_page_fault(vcpu, cr2, direct); if (r == RET_PF_EMULATE) goto emulate; } --- - 对于EPT场景,
static void ept_set_mmio_spte_mask(void) { /* * EPT Misconfigurations can be generated if the value of bits 2:0 * of an EPT paging-structure entry is 110b (write/execute). */ kvm_mmu_set_mmio_spte_mask(VMX_EPT_RWX_MASK, VMX_EPT_MISCONFIG_WX_VALUE, 0); } handle_ept_misconfig() -> kvm_mmu_page_fault(vcpu, gpa, PFERR_RSVD_MASK, NULL, 0);
6.3 MMIO emulator
在trap mmio的操作之后,需要kvm x86 emulator介入。
既然QEMU + KVM的指令的执行都是native的,为什么还需要emulator ?
参考文档,kvm: the Linux Virtual Machine Monitor![]() http://course.ece.cmu.edu/~ece845/sp13/docs/kvm-paper.pdf
http://course.ece.cmu.edu/~ece845/sp13/docs/kvm-paper.pdf
文中提到两点:
- 实现shadow page table,需要write-protect页表的page;当guest OS尝试写页表时,会触发page fault并vm exit,这时,kvm需要根据指令内容更新shadow page;解析指令内容,就需要使用x86 emulator;引用原文内容:"When a write to a guest page table is trapped, we need to emulate the access using an x86 instruction interpreter so that we know precisely the effect on both guest memory and the shadow page table"
- 实现memory IO,即mmio,引用原文内容:Trapping mmio, on the other hand, is quite complex, as the same instructions are used for regular memory accesses and mmio:
- The kvm mmu does not create a shadow page table translation when an mmio page is accessed
- Instead, the x86 emulator executes the faulting instruction, yielding the direction, size, address, and value of the transfer.
对于MMIO模拟来说,在trap了MMIO访问之后,kvm需要根据被trap的指令码,解析出操作类型、地址、值等;例如,一个读取MMIO的操作,kvm需要解析出MMIO操作地址,然后再去模拟对应的side-effect。
参考代码:
emulator_read_write()
---
rc = emulator_read_write_onepage(addr, val, bytes, exception,
vcpu, ops);
if (rc != X86EMUL_CONTINUE)
return rc;
if (!vcpu->mmio_nr_fragments)
return rc;
gpa = vcpu->mmio_fragments[0].gpa;
vcpu->mmio_needed = 1;
vcpu->mmio_cur_fragment = 0;
vcpu->run->mmio.len = min(8u, vcpu->mmio_fragments[0].len);
vcpu->run->mmio.is_write = vcpu->mmio_is_write = ops->write;
vcpu->run->exit_reason = KVM_EXIT_MMIO;
vcpu->run->mmio.phys_addr = gpa;
return ops->read_write_exit_mmio(vcpu, gpa, val, bytes);
---
此处的vcpu->run被映射到了qemu用户态进程,后者可以直接访问
x86_emulate_instruction()
---
...
r = x86_emulate_insn(ctxt);
...
} else if (vcpu->mmio_needed) {
if (!vcpu->mmio_is_write)
writeback = false;
r = EMULATE_USER_EXIT;
vcpu->arch.complete_userspace_io = complete_emulated_mmio;
}
---
EMULATOR_UESR_EXIT会导致qemu退回到用户态
之后qemu就会根据vcpu->run->exit_reason的值进行后续模拟操作;具体过程,这里将在学习IO模拟时详解。
7 Balloon
7.1 概述
文中提到
The consolidation ratio is a measure of the virtual hardware that has been placed on physical hardware [14]. A higher consolidation ratio typically indicates greater efficiency. Memory overcommitment raises the consolidation ratio, increases operational efficiency, and lowers total cost of operating virtual machines.
内存超售可以提高硬件资源利用率,降低成本;而balloon就是实现内存超售的一种手段。
Virtual memory ballooning is a computer memory reclamation technique used by a hypervisor to allow the physical host system to retrieve unused memory from certain guest virtual machines (VMs) and share it with others. Memory ballooning allows the total amount of RAM required by guest VMs to exceed the amount of physical RAM available on the host. When the host system runs low on physical RAM resources, memory ballooning allocates it selectively to VMs
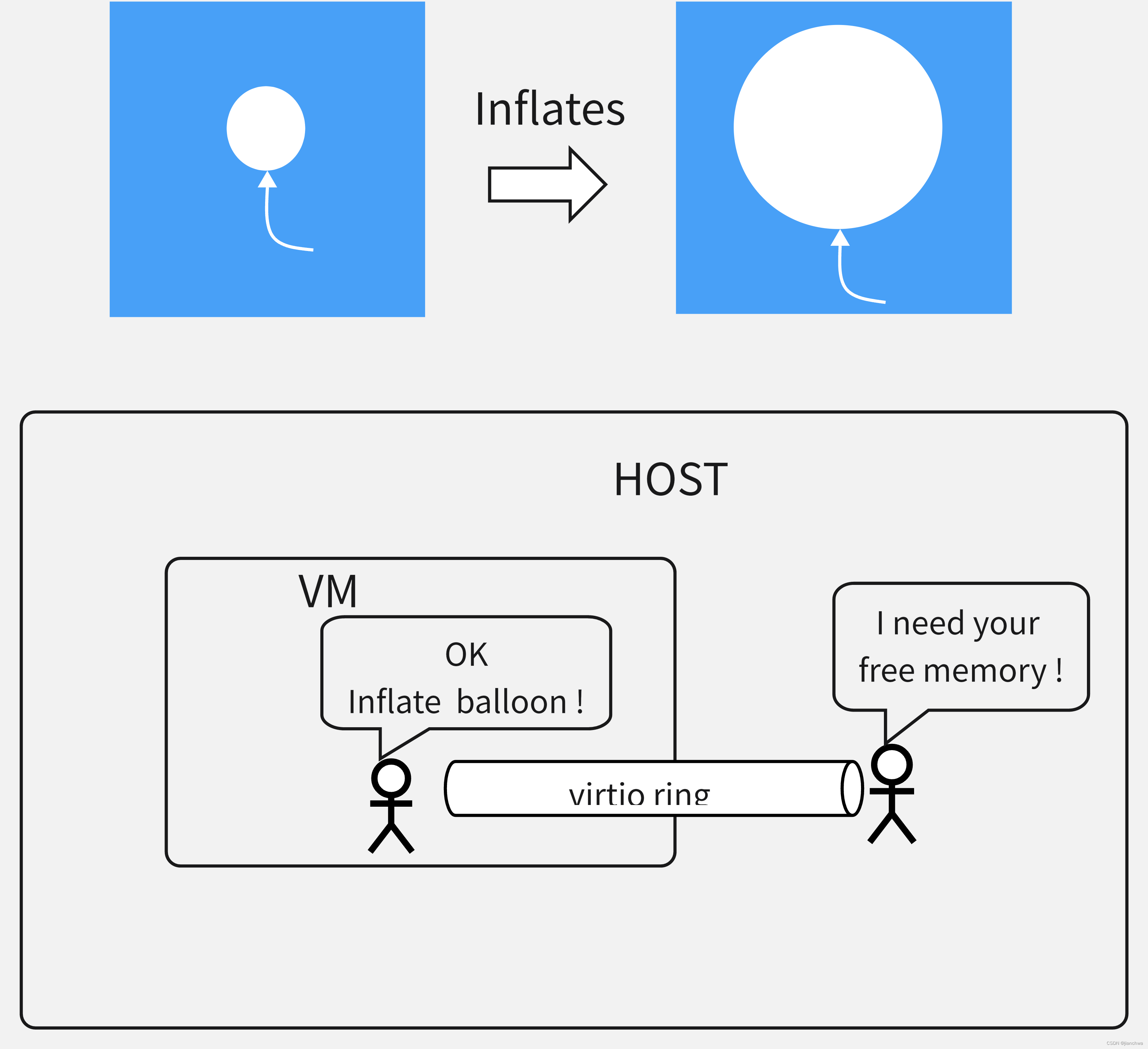
关于balloon有两点说明:
- 如上图中,蓝色填充部分是虚拟机的实际占用的物理内存,气球的大小是其中的空洞;把气球吹大的过程,实际上是把虚拟机占用物理内存返还给Host的过程;
- balloon是一种半虚拟化机制,它被安装在Guest OS中;在KVM中,它通过virtio与Host交互;
接下来,我们看下Ballon实现的基本原理。
7.2 Inflate & Denflate
在balloon的virtio-pci驱动中,它的config,有两个非常重要的
struct virtio_balloon_config {
/* Number of pages host wants Guest to give up. */
__le32 num_pages;
/* Number of pages we've actually got in balloon. */
__le32 actual;
...
}num_pages相当于是balloon的输入,来自Host;actual是balloon给Host的输出。
当Qemu修改配置之后,virtio-pci的config_changed回调会被触发,virtballoon_changed()会唤醒update_balloon_size_work(),参考代码:
update_balloon_size_func()
---
diff = towards_target(vb);
if (diff > 0)
diff -= fill_balloon(vb, diff);
else if (diff < 0)
diff += leak_balloon(vb, -diff);
update_balloon_size(vb);
if (diff)
queue_work(system_freezable_wq, work);
---
towards_target()
---
virtio_cread(vb->vdev, struct virtio_balloon_config, num_pages,
&num_pages);
...
target = num_pages;
return target - vb->num_pages;
---
update_balloon_size_fun()会被反复调用,直到满足Host端的num_pages的要求
接下来我们看下inflate是如何实现的,对应的是fill_balloon()的场景,参考代码:
fill_balloon()
---
//从Guest OS中直接申请内存
for (num_pfns = 0; num_pfns < num;
num_pfns += VIRTIO_BALLOON_PAGES_PER_PAGE) {
struct page *page = balloon_page_alloc();
//GFP_HIGHUSER_MOVABLE | __GFP_NOMEMALLOC | __GFP_NORETRY
if (!page) {
/* Sleep for at least 1/5 of a second before retry. */
msleep(200);
break;
}
balloon_page_push(&pages, page);
}
mutex_lock(&vb->balloon_lock);
vb->num_pfns = 0;
//将内存的GPA信息告知virtio-pci的后端,也就是QEMU
while ((page = balloon_page_pop(&pages))) {
set_page_pfns(vb, vb->pfns + vb->num_pfns, page);
vb->num_pages += VIRTIO_BALLOON_PAGES_PER_PAGE;
vb->num_pfns += VIRTIO_BALLOON_PAGES_PER_PAGE;
}
...
if (vb->num_pfns != 0)
tell_host(vb, vb->inflate_vq);
mutex_unlock(&vb->balloon_lock);
---所谓吹气球的过程,就是从Guest OS中申请一定量的内存,使用的flag是
GFP_HIGHUSER_MOVABLE | __GFP_NOMEMALLOC | __GFP_NORETRY
也就是说,inflate balloon是允许回收的,只不过只会尝试一次。
QEMU的virtio balloon的后端的处理代码:
virtio_balloon_handle_output()
---
while (virtqueue_pop(vq, &elem)) {
while (iov_to_buf(elem.out_sg, elem.out_num, offset, &pfn, 4) == 4) {
pa = (ram_addr_t)ldl_p(&pfn) << VIRTIO_BALLOON_PFN_SHIFT;
offset += 4;
// 通过memory region从GPA获取HVA !!!
section = memory_region_find(get_system_memory(), pa, 1);
if (!int128_nz(section.size) || !memory_region_is_ram(section.mr))
continue;
addr = section.offset_within_region;
balloon_page(memory_region_get_ram_ptr(section.mr) + addr, !!(vq == s->dvq));
memory_region_unref(section.mr);
}
---
balloon_page()
---
if (!kvm_enabled() || kvm_has_sync_mmu())
qemu_madvise(addr, TARGET_PAGE_SIZE,
deflate ? QEMU_MADV_WILLNEED : QEMU_MADV_DONTNEED);
---
QEMU_MADV_DONTNEED其实就是MADV_DONTNEED,它会解除对应地址的mapping,如果匿名内存,那么对应的物理内存也会被释放,参考代码:
madvise_dontneed_single_vma()
-> zap_page_range()
-> unmap_single_vma()
-> unmap_page_range()
-> zap_p4d_range()
-> zap_pud_range()
-> zap_pmd_range()
-> zap_pte_range()
zap_pte_range()
---
do {
pte_t ptent = *pte;
...
if (pte_present(ptent)) {
struct page *page;
page = _vm_normal_page(vma, addr, ptent, true);
...
ptent = ptep_get_and_clear_full(mm, addr, pte,
tlb->fullmm);
...
// Decrease page_mapcount
page_remove_rmap(page, false);
if (unlikely(__tlb_remove_page(tlb, page))) {
force_flush = 1;
addr += PAGE_SIZE;
break;
}
continue;
}
...
} while (pte++, addr += PAGE_SIZE, addr != end);
if (force_flush) {
force_flush = 0;
tlb_flush_mmu_free(tlb);
if (addr != end)
goto again;
}
---
__tlb_remove_page()
-> __tlb_remove_page_size()
---
batch = tlb->active;
/*
* Add the page and check if we are full. If so
* force a flush.
*/
batch->pages[batch->nr++] = page;
if (batch->nr == batch->max) {
if (!tlb_next_batch(tlb))
return true;
batch = tlb->active;
}
return false;
---
tlb_flush_mmu_free()
-> release_pages()
7.3 Guest OOM
起初,Balloon驱动增加了OOM Notifier,其注释如下:
The balancing of memory by use of the virtio balloon should not cause the termination of processes while there are pages in the balloon. If virtio balloon manages to release some memory, it will make the system return and retry the allocation that forced the OOM killer to run.
为什么不用vmscan shrinker呢?当有内存回收操作时,说明Guest OS已经因为内存问题承压了。
参考对应的commit,
virtio_balloon: replace oom notifier with shrinker
The OOM notifier is getting deprecated to use for the reasons:
- As a callout from the oom context, it is too subtle and easy to
generate bugs and corner cases which are hard to track;
- It is called too late (after the reclaiming has been performed).
Drivers with large amuont of reclaimable memory is expected to
release them at an early stage of memory pressure;
- The notifier callback isn't aware of oom contrains;
Link: https://lkml.org/lkml/2018/7/12/314
This patch replaces the virtio-balloon oom notifier with a shrinker
to release balloon pages on memory pressure. The balloon pages are
given back to mm adaptively by returning the number of pages that the
reclaimer is asking for (i.e. sc->nr_to_scan).
Currently the max possible value of sc->nr_to_scan passed to the balloon
shrinker is SHRINK_BATCH, which is 128. This is smaller than the
limitation that only VIRTIO_BALLOON_ARRAY_PFNS_MAX (256) pages can be
returned via one invocation of leak_balloon. But this patch still
considers the case that SHRINK_BATCH or shrinker->batch could be changed
to a value larger than VIRTIO_BALLOON_ARRAY_PFNS_MAX, which will need to
do multiple invocations of leak_balloon.
Historically, the feature VIRTIO_BALLOON_F_DEFLATE_ON_OOM has been used
to release balloon pages on OOM. We continue to use this feature bit for
the shrinker, so the shrinker is only registered when this feature bit
has been negotiated with host.
Signed-off-by: Wei Wang <wei.w.wang@intel.com>
Cc: Michael S. Tsirkin <mst@redhat.com>
Cc: Michal Hocko <mhocko@kernel.org>
Cc: Andrew Morton <akpm@linux-foundation.org>
Cc: Tetsuo Handa <penguin-kernel@I-love.SAKURA.ne.jp>
Signed-off-by: Michael S. Tsirkin <mst@redhat.com>
相关代码参考:
virtio_balloon_shrinker_scan
---
pages_to_free = sc->nr_to_scan * VIRTIO_BALLOON_PAGES_PER_PAGE;
/*
* One invocation of leak_balloon can deflate at most
* VIRTIO_BALLOON_ARRAY_PFNS_MAX balloon pages, so we call it
* multiple times to deflate pages till reaching pages_to_free.
*/
while (vb->num_pages && pages_to_free) {
pages_to_free -= pages_freed;
pages_freed += leak_balloon(vb, pages_to_free);
}
update_balloon_size(vb);
return pages_freed / VIRTIO_BALLOON_PAGES_PER_PAGE;
---
leak_balloon()
---
for (vb->num_pfns = 0; vb->num_pfns < num;
vb->num_pfns += VIRTIO_BALLOON_PAGES_PER_PAGE) {
page = balloon_page_dequeue(vb_dev_info);
if (!page)
break;
set_page_pfns(vb, vb->pfns + vb->num_pfns, page);
list_add(&page->lru, &pages);
vb->num_pages -= VIRTIO_BALLOON_PAGES_PER_PAGE;
}
num_freed_pages = vb->num_pfns;
if (vb->num_pfns != 0)
tell_host(vb, vb->deflate_vq);
release_pages_balloon(vb, &pages);
---
MISCS
Rmap
RMAP,用于追踪某个gfn上映射的多个spte;
可以对比Linux的某个系统库,会被多个任务共享,其page cache也会被映射到多个任务的地址空间内
信息的保存方式可以参考函数:
mmu_set_spte()
-> rmap_add()
-> pte_list_add()
---
if (!rmap_head->val) {
rmap_head->val = (unsigned long)spte;
} else if (!(rmap_head->val & 1)) {
desc = mmu_alloc_pte_list_desc(vcpu);
desc->sptes[0] = (u64 *)rmap_head->val;
desc->sptes[1] = spte;
rmap_head->val = (unsigned long)desc | 1;
++count;
} else {
desc = (struct pte_list_desc *)(rmap_head->val & ~1ul);
while (desc->sptes[PTE_LIST_EXT-1] && desc->more) {
desc = desc->more;
count += PTE_LIST_EXT;
}
if (desc->sptes[PTE_LIST_EXT-1]) {
desc->more = mmu_alloc_pte_list_desc(vcpu);
desc = desc->more;
}
for (i = 0; desc->sptes[i]; ++i)
++count;
desc->sptes[i] = spte;
}
---
参考文档
Xen and the Art of Virtualization![]() https://www.cl.cam.ac.uk/research/srg/netos/papers/2003-xensosp.pdfEfficient Memory Virtualization
https://www.cl.cam.ac.uk/research/srg/netos/papers/2003-xensosp.pdfEfficient Memory Virtualization![]() https://research.cs.wisc.edu/multifacet/theses/jayneel_gandhi_phd.pdfE6998 ‐ Virtual Machines Lecture 3 Memory Virtualization
https://research.cs.wisc.edu/multifacet/theses/jayneel_gandhi_phd.pdfE6998 ‐ Virtual Machines Lecture 3 Memory Virtualization![]() https://www.cs.columbia.edu/~nieh/teaching/e6998_s08/lectures/lecture3.pdfSelective Hardware/Software Memory Virtualization
https://www.cs.columbia.edu/~nieh/teaching/e6998_s08/lectures/lecture3.pdfSelective Hardware/Software Memory Virtualization![]() https://www.cse.iitb.ac.in/~puru/courses/spring19/cs695/downloads/hw-sw-mem.pdf
https://www.cse.iitb.ac.in/~puru/courses/spring19/cs695/downloads/hw-sw-mem.pdf














 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









