







一、问题定义
存在单一资源R,有n个需求{1, 2, …, n},每个需求指定一个开始时间bi与一个结束时间ei,在时间区间[bi, ei]内该需求想要占用资源R,资源R一旦被占用则无法被其他需求利用。每个需求i带有一个权值vi,代表该需求被满足之后能够带来的价值或者贡献。如果两个需求的时间区间不重叠,那么它们是相容的。带权值的区间调度问题即,对上面所描述的情境,求出一组相容子集S使得S中的区间权值之和最大。
举个简单例子,某一款网络游戏近期举办了不少活动,玩家只要参加活动可以获得相应的奖励。每个活动都有对应的活动时间以及活动奖励,玩家在一个时间段之内只能参加一个活动,并且必须完整地参加一个活动才能获取奖励(即从活动开始到活动结束之间不能中断去参加其他活动)。假设现在有n个活动,部分活动的时间区间有重叠。某位精通算法的玩家希望通过计算确定合理的活动安排,使得自己获取的奖励最大化。
二、解决思路
继续以上面的游戏活动为背景。假设将活动按照它们的结束时间ei从早到晚进行排序。e1 <= e2 <= … <= en。排序之后我们会得到如下所示的活动顺序图。
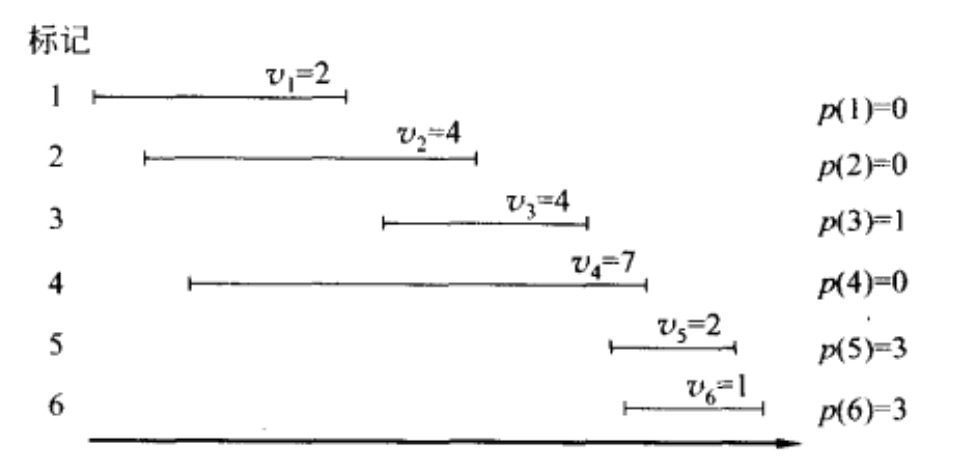
上图中的标记表示活动名称(活动1、活动2、…),vi表示参加活动i能够收获的奖励,vi的值越大表示奖励越多。下面定义图中展示的p(j)。对于某个活动j,p(j)表示排在活动j之前的所有活动里面离j最近并且相容的活动,如果没有相容的活动,则p(j) = 0。例如p(3),从图中可以看到,活动3前面只有活动2和活动1,而活动2跟活动3有区间重叠,不相容,只有活动1相容,因此p(3) = 1,代表活动3前面的所有活动中离它最近并且相容的活动是活动1。
我们要解决的问题是选择一组最优活动组合使得所有活动奖励之和最大。这里再定义一个概念,OPT(n),表示从n个活动{1, 2, …, n}中能够获取到的最大奖励。假设我们已经从{1, 2, …, n-1}中选取出一组最优活动组合,使得最大活动奖励为OPT(n-1)。现在要来考虑是否要参加活动n,这个时候有两种选择策略:
- 第一,参加活动n。要参加活动n的话必须去掉{1, 2, …, n-1}中所有跟n冲突的活动。也就是说,我们只能从活动{1, 2, …, p(n)}中选取要参加的活动组合,而活动{p(n)+1, p(n)+2, …, n-1}则全部不能选择,因为它们都跟活动n冲突了(回顾前面p(j)的定义)。那么这个时候选择参加活动n之后,我们会得到新的活动组合,这个组合的奖励之和会变成OPT(p(n)) + vn,即从活动{1, 2, …, p(n)}中能够获取的最大奖励再加上活动n的奖励。
- 第二,放弃活动n,这种情况下计算活动奖励就很简单了,选择参加的活动组合没有发生变化,故奖励仍是从{1, 2, …, n-1}中能够获取的最大奖励OPT(n-1)。
我们的目的是求取一个最优的活动组合使得奖励最大化,因此,只需要考虑上面两种选择哪一种的奖励更多即可,奖励越多的选择越优秀。如果OPT(p(n)) + vn的值更大,选择参加活动n,放弃跟n冲突的其他活动。如果OPT(n-1)更大,那么放弃活动n,继续保留原来选定的活动组合。于是我们很容易可以得到下面的递推公式:
OPT(j) = max(OPT(p(j)) + vj, OPT(j-1))得到上面的公式之后,我们可以发现,求解一个问题OPT(j),可以通过求解它的子问题OPT(j-1)来实现,于是我们做到了把求解一个问题变成求解它的子问题。于是我们可以得到下面这个递归算法:
OPT(j):
If j == 0 then
return 0
Else
return max(OPT(p(j)) + vj, OPT(j-1))
Endif三、优化改进
上面的递归算法是尾递归,可以使用迭代对其进行优化。使用一个数组(动态规划的专业名词叫做备忘录)来记录求解过的值,避免重复求解。改进之后可以得到下面这个迭代算法,时间复杂度为O(n)。
OPT[n] = {0}
For j = 1 to n:
OPT[j] = max(OPT(p(j)) + vj, OPT(j-1))
Endfor该算法已经可以帮助我们找到最大奖励了。但仅知道一个最大奖励并没有太大意义,我们更需要知道通过参加哪些活动来取得最大奖励。因此,我们在计算最大活动奖励的过程中,还需要记录一下选取了哪些活动。
我们定义一个记录数组S,继续回到我们前面讨论过的选择活动n的时候面临的两种选择。如果采取第一选择,即参加活动n,我们便记录S[n][0] = true,S[n][1] = p(n),代表我们在考虑活动n的时候选择了参加活动n,搭配上前面{1, 2, …, p(n)}中的最优组合。如果采取第二选择,即放弃活动n,那么我们记录S[n][0] = false,S[n][1] = n-1,代表我们放弃活动n,此时活动的选择情况还是与之前考虑活动n-1时候的情况一致。于是我们可以得到如下算法:
OPT[n] = {0}
初始化 S[n][2]
For j = 1 to n:
If OPT(p(j)) + vj >= OPT(j-1) then
OPT[j] = OPT(p(j)) + vj
S[j][0] = true
S[j][1] = p[j]
Else
OPT(j) = OPT(j-1)
S[j][0] = false
S[j][1] = n-1
Endif
Endfor通过上面算法便可以得到想要的活动组合的记录表了。然后反向搜索一下记录表便可得到最优的活动组合。
j = n
while j != 0:
If S[j][0] then
print j
Endif
j = S[j][1]
Endwhile四、代码示例
#include <iostream>
using namespace std;
const int MAX_REQ_NUM = 30;
struct Request {
int beginTime;
int endTime;
int value;
};
bool operator<(const Request& r1, const Request& r2) {
return r1.endTime < r2.endTime;
}
class DP {
public:
void setRequestNum(const int& requestNum) {
this->requestNum = requestNum;
}
void init() {
for (int i = 1; i <= requestNum; ++i) {
cin >> reqs[i].beginTime >> reqs[i].endTime >> reqs[i].value;
}
}
// 预备,根据结束时间对所有请求排序,初始化数组p
void prepare() {
sort(reqs + 1, reqs + requestNum + 1);
memset(p, 0, sizeof(p));
for (int i = 1; i <= requestNum; ++i) {
for (int j = i-1; j > 0; --j) {
if (reqs[j].endTime <= reqs[i].beginTime) {
p[i] = j;
break;
}
}
}
memset(record, 0, sizeof(record));
}
// 动态规划算法
void solve() {
optimal[0] = 0;
for (int i = 1; i <= requestNum; ++i) {
if (optimal[p[i]] + reqs[i].value >= optimal[i-1]) {
optimal[i] = optimal[p[i]] + reqs[i].value;
record[i][0] = 1;
record[i][1] = p[i];
} else {
optimal[i] = optimal[i-1];
record[i][0] = 0;
record[i][1] = i-1;
}
}
}
// 输出结果
void output() {
cout << "[MAX VALUE]: " << optimal[requestNum]
<< "\n[Activities]:\n";
for (int i = requestNum; i > 0; i = record[i][1]) {
if (record[i][0] == 1) {
cout << "activity-" << i << endl;
}
}
}
private:
Request reqs[MAX_REQ_NUM + 1];
int requestNum;
int p[MAX_REQ_NUM + 1];
int optimal[MAX_REQ_NUM + 1];
int record[MAX_REQ_NUM + 1][2];
};
int main() {
int requestNum;
DP dp;
cin >> requestNum;
dp.setRequestNum(requestNum);
dp.init();
dp.prepare();
dp.solve();
dp.output();
return 0;
}输入格式:
活动总数
活动1的开始时间、结束时间、贡献价值
活动2的开始时间、结束时间、贡献价值
...
活动n的开始时间、结束时间、贡献价值输入输出示例:
6
0 4 2
1 6 4
5 7 4
2 9 7
8 10 2
8 11 1
[MAX VALUE]: 8
[Activities]:
activity-5
activity-3
activity-1















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









