







1.存在一个样本数据集,作为样本数据集,该样本集的每一条数据都存在标签也就是说每条样本集的类别已知。输入一个没有标签的新数据集,将新数据的特征和样本集的数据特征进行比较,然后提取与新数据最相似的样本数据的标签作为新数据的标签。一般来说,选择样本集中前K个出现次数最多的标签作为新数据的标签。
2.一般步骤:收集数据(文本/其他程序收集)–>准备数据(归一化,格式化数据,是数据使用于距离计算)–>分析数据(散点图分布,可以探究数据是否存意义)–>训练算法(K-NN算法中无需此步骤)–>测试算法(计算错误率,错误率为1毫无意义,0最为完美,力求分类器获得最低错误率)–>使用算法进行预测
3.K-NN算法的优点:精度高,对异常数据不敏感,无数据输入要求。缺点:计算复杂度高、空间复杂度高。适用数据范围:数值型和标称型。
4.数据准备预处理
+++++++++++++++++++++++++++++++++++
f1 f2 f3 labels
40920 8.326976 0.953952 largeDoses
14488 7.153469 1.673904 smallDoses
26052 1.441871 0.805124 didntLike
:
:
:
61364 7.516754 1.269164 didntLike
69673 14.239195 0.261333 didntLike
15669 0.000000 1.250185 smallDoses
28488 10.528555 1.304844 largeDoses
6487 3.540265 0.822483 smallDoses
37708 2.991551 0.833920 didntLike
++++++++++++++++++++++++++++++++
转换为:(以下表标称转为数值,后面数值的归一化去除不同特征的数值相对偏大或偏小的影响)
f1 f2 f3 labels
40920 8.326976 0.953952 3
14488 7.153469 1.673904 2
:
:
:
50242 3.723498 0.831917 1
63275 8.385879 1.669485 1
5569 4.875435 0.728658 2
51052 4.680098 0.625224 1
+++++++++++++++++++++++++++++++++
5.使用散点图进行数据特征与类别分析
import matplotlib
import matplotlib.pyplot as plt
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datinglabels)##大小,90*array(datinglabels)##颜色)
plt.show()
##########################################################
#matplotlib.pyplot.scatter(x, y, s=20, c=None, marker='o', cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, verts=None, edgecolors=None, hold=None, data=None, **kwargs)
#x, y : array_like, shape (n, )
Input data
s : scalar or array_like, shape (n, ), optional,default: 20
size in points^2.
c : color or sequence of color, optional, default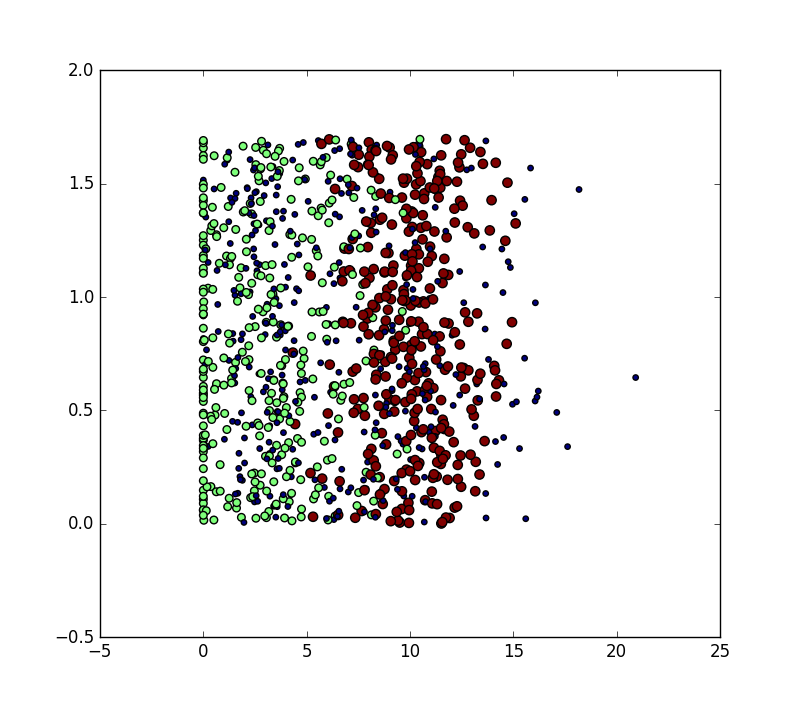
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def datingClassTest():
hoRatio = 0.50 #hold out 10%
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
group,labels=createDataSet()
patten = classify0([0,0],group,labels,3)
print patten
datingDataMat,datinglabels=file2matrix('C:\Users\Administrator\Desktop\MLiA_SourceCode\machinelearninginaction\Ch02\datingTestSet2.txt')
print datingDataMat
import matplotlib
import matplotlib.pyplot as plt
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datinglabels),90*array(datinglabels))
print datingDataMat.min(0)
print datingDataMat.m
# plt.show()














 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









