







循环链表
循环链表是一种特殊的链表,其特点是,表中最后一个结点的指针域指向头结点,整个链表的首位结点相连形成一个环。
因此,从循环链表中的任何结点出发都可以找到其他结点
循环链表的操作运算和单链表的我操作基本相同,两者最大的差别在于:遍历链表时的终止条件不同。
在链表中,用指针域是否为空判断表尾的条件;而在循环链表中,则用指针域是否指向表头结点作为条件。
循环链表设置尾指针
有些时候,我们操作链表大多是在表头、表尾操作。若用头指针查找首结点a1的时间复杂度是O(1),而查找表尾an则时间复杂度为o(n)。
循环链表既然可以形成一个环,所以我们可以设置尾指针而不设置头指针的循环链表,这样无论查找首元结点还是尾结点时间复杂度都是O(1)。
双向链表
由于单链表的每个结点只有一个指示其直接后继的指针域,返回前驱结点很难,为了克服这种缺点,可以采用双向链表的存储结构。
双向链表的存储结构
线性表的双向链表存储结构
typedef struct DuLNode{
ElemType data;
struct DuLNode *prior,*next;
}DuLNode,*DuLinkList;双向循环链表的基本操作
12个基本操作:
//双向循环链表的基本操作(12个)
//1
Status InitList(DuLinkList *L)
{ /* 产生空的双向循环链表L */
*L=(DuLinkList)malloc(sizeof(DuLNode));
if(!L) exit(OVERFLOW);
(*L)->next=(*L)->prior=*L;
return OK;
}
//2
Status DestroyList(DuLinkList *L)
{ /* 操作结果:销毁双向循环链表L */
DuLinkList q,p =(*L)->next; // p指向第一个结点
while(p!=*L) // p没有到表头
{//依次释放链表结点空间
q=p->next;
free(p);
p=q;
}
free(*L);
*L=NULL;
return OK;
}
//3
Status ClearList(DuLinkList L)
{ /* 初始条件:L已存在。操作结果:将L重置为空表 */
DuLinkList q,p=L->next; // p指向第一个结点
while(p!=L) // p没到表头
{
q=p->next;
free(p);
p=q;
}
L->next=L->prior=L; // 结点的前驱和后继都指向自身,也就是判断为空的条件。
return OK;
}
//4
Status ListEmpty(DuLinkList L)
{ /* 初始条件:线性表L已存在。操作结果:若L为空表,则返回TRUE,否则返回FALSE */
if(L->next==L&&L->prior==L)
return TRUE;
else
return FALSE;
}
//5
int ListLength(DuLinkList L)
{ /* 初始条件:L已存在。操作结果:返回L中数据元素个数 */
int i=0;
DuLinkList p=L->next; // p指向第一个结点
while(p!=L) // p没到表头
{
i++;
p=p->next;
}
return i;
}
//6
Status GetElem(DuLinkList L,int i,ElemType *e)
{ /* 当第i个元素存在时,其值赋给e并返回OK,否则返回ERROR */
int j=1; // j为计数器
DuLinkList p=L->next; // p指向第一个结点
while(p!=L && j
next;
j++;
}
if(p==L||j>i) // 第i个元素不存在
return ERROR;
*e=p->data; // 取第i个元素
return OK;
}
//7
int LocateElem(DuLinkList L,ElemType e,Status(*compare)(ElemType,ElemType))
{ /* 初始条件:L已存在,compare()是数据元素判定函数 */
/* 操作结果:返回L中第1个与e满足关系compare()的数据元素的位序。 */
/* 若这样的数据元素不存在,则返回值为0 */
int i=0;
DuLinkList p =L->next; // p指向第1个元素
while(p!=L)
{
i++;
if(compare(p->data,e)) // 符合条件的数据元素
return i;
p=p->next;
}
return 0;
}
//8
Status PriorElem(DuLinkList L,ElemType cur_e,ElemType *pre_e)
{ /* 操作结果:若cur_e是L的数据元素,且不是第一个,则用pre_e返回它的前驱, */
/* 否则操作失败,pre_e无定义 */
DuLinkList p=L->next->next; // p指向第2个结点
//和单链表的不同:在单链表中除了有个指向当前结点的指针还有指向其前驱的指针,而双向循环链表则不需要。
while(p!=L) // p没到表头
{
if(p->data==cur_e)
{
*pre_e=p->prior->data; //利用双向链表的存储特点
return TRUE;
}
p=p->next;
}
return FALSE;
}
//9
Status NextElem(DuLinkList L,ElemType cur_e,ElemType *next_e)
{ /* 操作结果:若cur_e是L的数据元素,且不是最后一个,则用next_e返回它的后继, */
/* 否则操作失败,next_e无定义 */
DuLinkList p=L->next->next; // p指向第2个元素
while(p!=L) // p没到表头
{
if(p->prior->data==cur_e)
{
*next_e=p->data;
return TRUE;
}
p=p->next;
}
return FALSE;
}
//10,插入操作
Status ListInsert(DuLinkList L,int i,ElemType e)
{ /* 在带头结点的双链循环线性表L中第i个位置之前插入元素e,i的合法值为1≤i≤表长+1 */
DuLinkList p,s;
int j=0;
p =L;
if(i<1 || j>ListLength(L)+1)//i的不合法值,大于表长加1
return ERROR;
while(j
next;
j++;
}
s=(DuLinkList)malloc(sizeof(DuLNode));
if(!s)
exit(OVERFLOW);
// 在第i-1个结点后插入
s->data=e;
s->prior=p;
s->next=p->next;
p->next->prior=s;
p->next=s;
return OK;
}
//11
Status ListDelete(DuLinkList L,int i,ElemType *e)
{ /* 删除带头结点的双链循环线性表L的第i个元素,i的合法值为1≤i≤表长*/
DuLinkList p;
int j=1;
p =L->next;
if(i<1 || i>ListLength(L))
return ERROR;
while(j
next;
j++;
}
//删除结点
*e=p->data;
p->prior->next=p->next;
p->next->prior=p->prior;
free(p);
return OK;
}
//12
void ListTraverse(DuLinkList L,void(*visit)(ElemType))
{ /* 由双链循环线性表L的头结点出发,正序对每个数据元素调用函数visit() */
DuLinkList p=L->next; /* p指向头结点 */
while(p!=L)
{
visit(p->data);
p=p->next;
}
printf("\n");
}
1,测试代码可以参考单链表的代码,只需修改成员变量即可。
2,测试结果图:
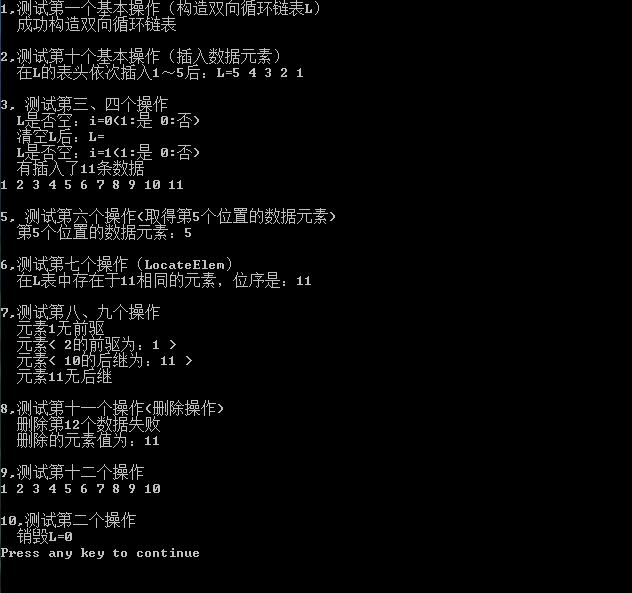
3,总结:
双向循环链表的插入和删除操作:
插入操作的自然语言描述:
1)令s的前驱指针指向p结点;
2)令s的后继指针指向q结点的直接后继
3)令p结点直接后继的前驱指针指向s
4)令p结点的直接后继指针指向p
删除操作的自然语言描述:
1)令p结点的前驱结点的后继指针指向p的后继结点
2)令p的后继结点的求前驱指针指向p的前驱结点
3)释放结点p















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









