







 本文详细介绍了循环链表的概念、特点,包括其结构、基本操作(如初始化、插入、删除和遍历),以及在实际开发中的应用场景和时间复杂度分析。同时讨论了循环链表的优缺点,为选择合适的数据结构提供指导。
本文详细介绍了循环链表的概念、特点,包括其结构、基本操作(如初始化、插入、删除和遍历),以及在实际开发中的应用场景和时间复杂度分析。同时讨论了循环链表的优缺点,为选择合适的数据结构提供指导。
1. 引言
循环链表的概念和特点
循环链表是一种链表的变体,它与普通链表最大的不同是:在循环链表中,最后一个节点的指针不是NULL,而是指向头节点,形成了一个环。这种特殊结构使得循环链表中的数据可以像环一样循环访问。
循环链表的特点如下:
- 可以循环使用存储空间,实现数据的重复利用。
- 可以很方便地遍历整个链表,因为从任意一个节点出发都能遍历到所有节点。
- 插入和删除操作比较容易,因为在任意一个节点处进行插入和删除操作都是类似的。
循环链表与普通链表的区别
循环链表和普通链表的最大区别在于最后一个节点的指针。在普通链表中,最后一个节点的指针指向NULL,表示链表的结尾;而在循环链表中,最后一个节点的指针指向头节点,形成了一个环。
这种环的结构使得循环链表可以像环一样循环访问其中的数据。也就是说,无论从哪个节点开始遍历,都可以遍历到所有节点。而在普通链表中,只能从头节点开始遍历,直到遍历到NULL为止。
此外,循环链表插入和删除节点的操作比较容易,因为在任意一个节点处进行插入和删除操作都是类似的。而在普通链表中,对于头节点和尾节点的插入和删除操作需要进行特殊处理。
综上所述,循环链表的环状结构使得它具有一些特殊的性质,例如可以循环访问其中的数据、插入和删除节点的操作比较容易等等。
2. 基本结构
定义循环链表的结构
循环链表的结构可以通过定义一个节点结构体来实现。每个节点包含两个主要成员:数据和指向下一个节点的指针。
以下是一个示例的循环链表节点结构的定义:
struct Node {
int data; // 节点中存储的数据
Node* next; // 指向下一个节点的指针
};
在循环链表中,需要注意的一点是最后一个节点的指针不是NULL,而是指向头节点,形成了一个环。因此,在创建循环链表时,需要特别处理最后一个节点的指针,使其指向头节点。
另外,为了方便操作循环链表,还可以定义一个指向头节点的指针,以便快速访问和操作循环链表的各个节点。
Node* head = nullptr; // 指向循环链表头节点的指针
描述循环链表的节点和指针关系
循环链表的节点和指针关系可以用mermaid语言来绘制图示。以下是一个简单的例子,由三个节点组成,节点分别为A、B和C。
在这个例子中,每个节点用一个方框表示,方框内包含一个数据字段。节点之间用箭头表示指针关系,箭头从指向前驱节点的指针指向后继节点。
需要注意的是,最后一个节点的指针指向头节点,以形成循环。
3.基本操作
1. 初始化循环链表
初始化一个循环链表需要定义一个头节点,并将其指向自身,以形成一个空的循环链表。在C++中,可以使用如下代码进行初始化:
Node* head = new Node();
head->next = head;
2. 在头部插入元素
在循环链表的头部插入元素,需要把新的节点插入到头节点和第一个节点之间,并修改头节点的指针指向新的节点。具体操作如下:
Node* newNode = new Node();
newNode->data = val;
newNode->next = head->next;
head->next = newNode;
3. 在尾部插入元素
向循环链表的尾部插入元素,需要找到最后一个节点,并将其指针指向新的节点。具体操作如下:
// 找到最后一个节点
Node* last = head;
while (last->next != head) {
last = last->next;
}
// 创建新的节点
Node* newNode = new Node();
newNode->data = val;
newNode->next = head;
// 将最后一个节点的指针指向新的节点
last->next = newNode;
需要注意的是,在循环链表中,最后一个节点的指针不是NULL,而是指向头节点。
4. 删除指定位置的元素
在循环链表中删除指定位置的元素,需要找到要删除的节点的前驱节点,并将其指针指向要删除节点的后继节点。具体操作如下:
// 找到要删除的节点的前驱节点
Node* prev = head;
for (int i = 0; i < pos - 1; i++) {
prev = prev->next;
}
// 删除节点
Node* temp = prev->next;
prev->next = temp->next;
delete temp;
需要注意的是,如果要删除的是最后一个节点,需要特殊处理其指针指向头节点。
5. 遍历循环链表
遍历循环链表可以使用循环来实现,从头节点开始,依次遍历每个节点,并输出其中的数据。具体操作如下:
Node* p = head->next;
while (p != head) {
cout << p->data << " ";
p = p->next;
}
需要注意的是,由于循环链表的最后一个节点指向头节点,因此在遍历时应该以头节点为判断条
4. 循环链表的实现
使用动态内存分配来实现循环链表,可以在每次插入新节点时使用 new 运算符来分配内存。以下是一个使用动态内存分配实现循环链表的示例代码:
#include <iostream>
struct Node {
int data;
Node* next;
};
void insertAtHead(Node*& head, int val) {
Node* newNode = new Node();
newNode->data = val;
if (head == nullptr) {
newNode->next = newNode;
head = newNode;
} else {
newNode->next = head->next;
head->next = newNode;
}
}
void insertAtTail(Node*& head, int val) {
Node* newNode = new Node();
newNode->data = val;
if (head == nullptr) {
newNode->next = newNode;
head = newNode;
} else {
Node* last = head;
while (last->next != head) {
last = last->next;
}
newNode->next = head;
last->next = newNode;
}
}
void deleteAtPosition(Node*& head, int pos) {
if (head == nullptr) {
return;
}
Node* prev = head;
for (int i = 0; i < pos - 1; i++) {
prev = prev->next;
}
Node* temp = prev->next;
prev->next = temp->next;
delete temp;
}
void traverse(Node* head) {
if (head == nullptr) {
return;
}
Node* p = head->next;
while (p != head) {
std::cout << p->data << " ";
p = p->next;
}
std::cout << std::endl;
}
int main() {
Node* head = nullptr;
insertAtHead(head, 3); // 往头部插入元素
insertAtHead(head, 2);
insertAtHead(head, 1);
traverse(head); // 输出链表元素:1 2 3
insertAtTail(head, 4); // 往尾部插入元素
insertAtTail(head, 5);
traverse(head); // 输出链表元素:1 2 3 4 5
deleteAtPosition(head, 2); // 删除第二个位置元素
traverse(head); // 输出链表元素:1 2 4 5
return 0;
}
执行结果
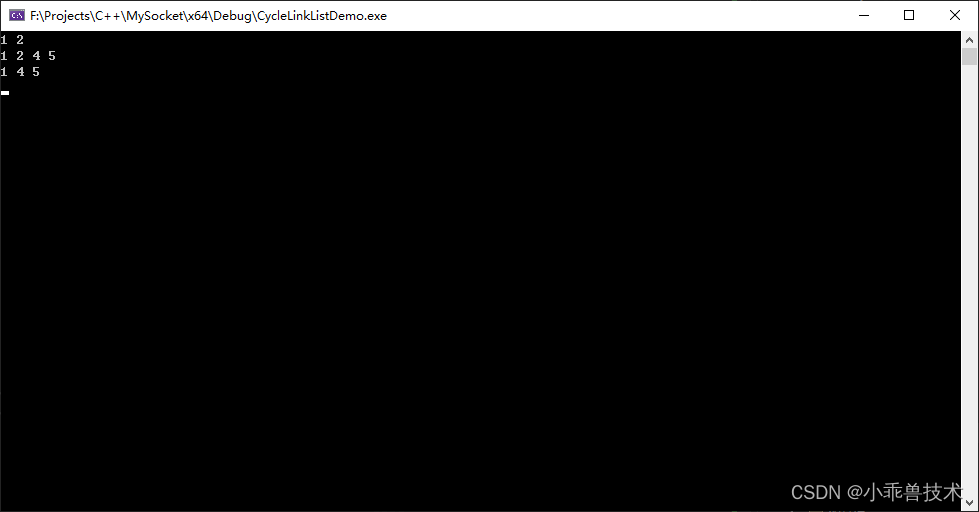
在这个示例中,Node 结构体表示循环链表的节点,其中 data 字段存储节点的值,next 字段指向下一个节点。insertAtHead 函数用于在头部插入元素,insertAtTail 函数用于在尾部插入元素,deleteAtPosition 函数用于删除指定位置的元素,traverse 函数用于遍历循环链表并输出元素。在 main 函数中演示了如何使用这些操作来创建循环链表,并进行插入、删除和遍历操作。
5. 应用场景与实际案例
循环链表在实际开发中有许多应用场景,特别适用于需要循环遍历或循环操作的情况。以下是一些常见的应用场景和实际案例:
-
缓存管理:在计算机系统中,缓存是一种常见的性能优化技术。通过将最近使用的数据存储在高速缓存中,可以显著提高数据访问速度。环形链表常被用作缓存的数据结构,以便实现最新数据的存储和访问。
-
数据处理:在实时数据处理和流式处理中,环形链表可以用来存储连续的数据流。例如,在实时监测系统中,需要对连续的传感器数据进行处理和分析。使用环形链表,可以方便地保存最近的一段时间内的数据,以便后续处理和分析。
-
音频处理:在音频处理领域,环形缓冲区常被用于实时音频信号的采样和处理。通过将音频数据存储在环形链表中,可以实现音频数据的循环存储,并且方便进行实时信号处理,如音频特效、混音等。
-
消息队列:消息队列是一种常见的通信模式,用于在分布式系统中传递消息。环形链表可以用来实现消息队列的缓冲区,确保消息按照顺序被消费,同时避免队列长度无限增长的问题。
-
循环赛制和任务分配:在体育竞技或任务分配中,往往需要构建一个循环的比赛或任务安排。使用环形链表可以方便地管理参与者或任务之间的关系,并实现循环的安排和分配。
循环链表在这些场景中的优势和使用方法如下:
-
循环遍历:由于循环链表的最后一个节点指向头节点,因此可以轻松实现循环遍历,不需要额外的判断条件。在音乐播放器的播放列表中,可以实现循环顺序播放歌曲。
-
动态操作:循环链表可以方便地插入和删除节点。在音乐播放器的播放列表中,可以在任意位置插入新的歌曲或删除已经播放的歌曲。
-
空间效率:循环链表可以节省内存空间,因为它不需要额外的指针来表示末尾节点。在约瑟夫环问题中,使用循环链表可以有效地模拟人们围成圆圈的结构。
-
灵活性:循环链表可以适应动态变化的需求。在音乐播放器的播放列表中,可以根据用户的操作随时调整播放顺序或删除歌曲。
6. 时间复杂度分析
循环链表的各种操作的时间复杂度如下:
-
插入操作:
- 在头部插入节点:O(1)
- 在尾部插入节点:O(n),需要遍历到最后一个节点
-
删除操作:
- 删除指定位置的节点:O(n),需要遍历到指定位置的前一个节点
-
遍历操作:
- 遍历整个链表:O(n),需要遍历到最后一个节点
对比循环链表与普通链表的性能差异:
-
插入和删除操作:循环链表在头部插入和删除节点的时间复杂度都是O(1),而在尾部插入和删除节点的时间复杂度都是O(n)。相比之下,普通链表在头部插入和删除节点的时间复杂度也是O(1),但在尾部插入和删除节点的时间复杂度为O(1),因为普通链表可以直接访问到尾节点。
-
遍历操作:循环链表和普通链表的遍历操作时间复杂度都是O(n),需要遍历整个链表。没有明显的性能差异。
因此,循环链表在头部插入和删除节点的操作上具有优势,时间复杂度为O(1),但在尾部插入和删除节点的操作上劣于普通链表,时间复杂度为O(n)。在遍历操作上,两者没有明显的性能差异。选择使用循环链表还是普通链表,取决于具体的应用需求和操作频率。
7. 优缺点与总结
循环链表的优点和适用情况:
-
循环遍历:循环链表可以轻松实现循环遍历,不需要额外的判断条件,适用于需要循环操作或循环访问的场景。
-
动态操作:循环链表可以方便地插入和删除节点,适用于需要频繁进行插入和删除操作的场景。
-
空间效率:循环链表可以节省内存空间,因为它不需要额外的指针来表示末尾节点,适用于对内存占用有限制的场景。
-
灵活性:循环链表可以适应动态变化的需求,可以根据需要随时调整链表结构,适用于需要灵活性的场景。
循环链表的缺点和局限性:
-
尾部操作低效:在循环链表中,尾部插入和删除节点的操作时间复杂度较高,为O(n),相比普通链表劣势明显。
-
难以确定链表长度:由于循环链表没有明确的结束标志,难以准确获取链表的长度,可能需要额外的计数器来维护。
-
需要特殊处理空链表:循环链表中,空链表的表示需要特殊处理,可能需要使用一个特殊节点来表示空链表。
建议选择合适的数据结构:
-
如果需要频繁在头部进行插入和删除操作,并且对尾部操作要求不高,可以选择循环链表。
-
如果需要频繁在尾部进行插入和删除操作,或者对获取链表长度有较高需求,可以选择普通链表。
-
如果对空间效率有限制,且需要循环遍历、动态操作和灵活性,可以考虑使用循环链表。
总之,在选择合适的数据结构时,需要根据具体应用场景的需求权衡各种因素,包括操作频率、时间复杂度、空间效率和灵活性等,以便找到最适合的数据结构。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











