







PEFT techniques 2: Soft prompts(PEFT技术其二——软提示)
With LoRA, the goal was to find an efficient way to update the weights of the model without having to train every single parameter again. There are also additive methods within PEFT that aim to improve model performance without changing the weights at all. In this video, you'll explore a second parameter efficient fine tuning method called prompt tuning.
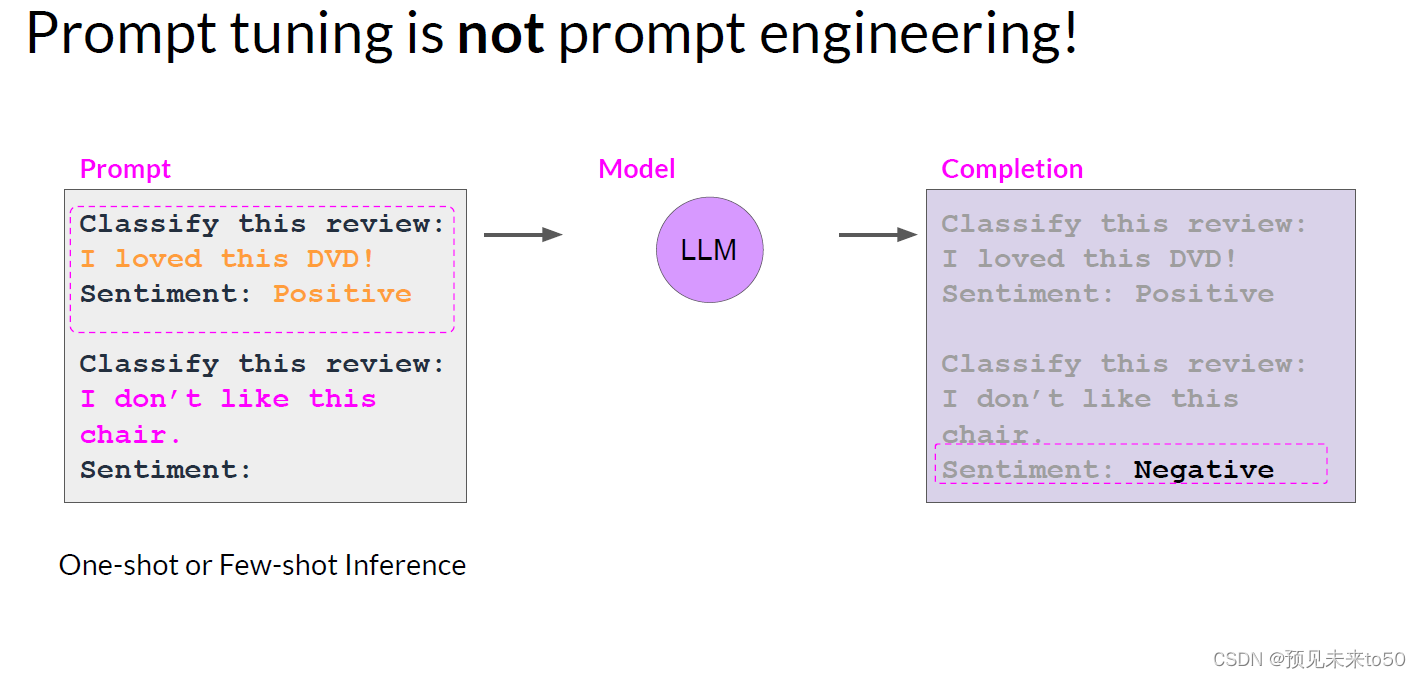
Now, prompt tuning sounds a bit like prompt engineering, but they are quite different from each other. With prompt engineering, you work on the language of your prompt to get the completion you want. This could be as simple as trying different words or phrases or more complex, like including examples for one or Few-shot Inference. The goal is to help the model understand the nature of the task you're asking it to carry out and to generate a better completion. However, there are some limitations to prompt engineering, as it can require a lot of manual effort to write and try different prompts. You're also limited by the length of the context window, and at the end of the day, you may still not achieve the performance you need for your task.
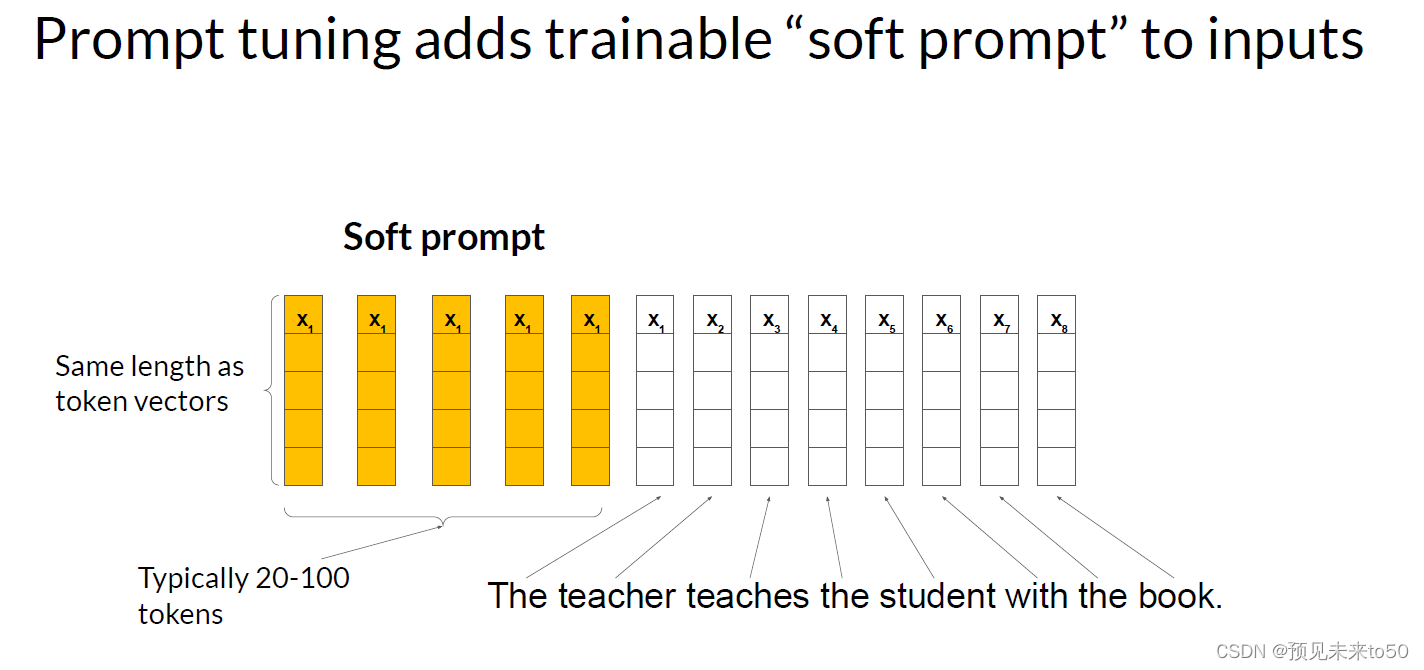
With prompt tuning, you add additional trainable tokens to your prompt and leave it up to the supervised learning process to determine their optimal values. The set of trainable tokens is called a soft prompt, and it gets prepended to embedding vectors that represent your input text. The soft prompt vectors have the same length as the embedding vectors of the language tokens. And including somewhere between 20 and 100 virtual tokens can be sufficient for good performance. The tokens that represent natural language are hard in the sense that they each correspond to a fixed location in the embedding vector space. However, the soft prompts are not fixed discrete words of natural language. Instead, you can think of them as virtual tokens that can take on any value within the continuous multidimensional embedding space. And through supervised learning, the model learns the values for these virtual tokens that maximize performance for a given task.

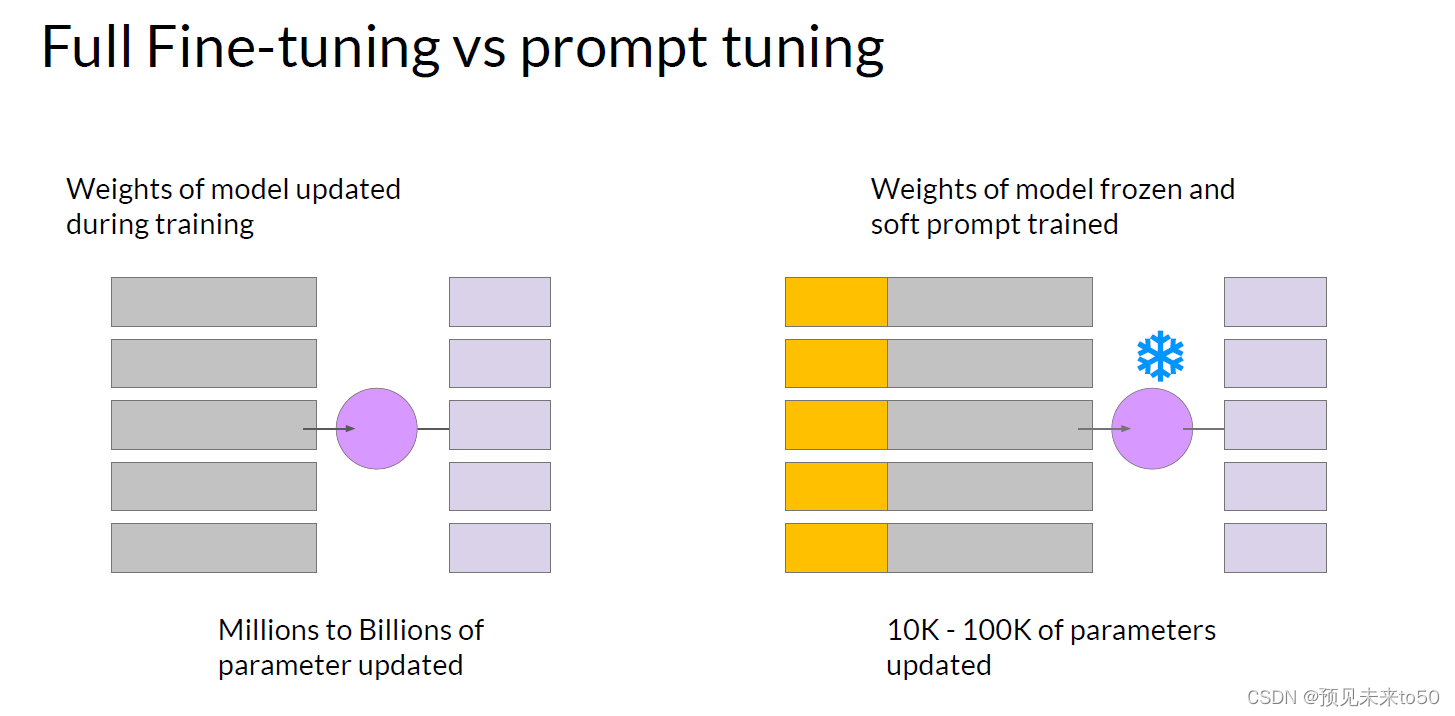
In full fine tuning, the training data set consists of input prompts and output completions or labels. The weights of the large language model are updated during supervised learning. In contrast with prompt tuning, the weights of the large language model are frozen and the underlying model does not get updated. Instead, the embedding vectors of the soft prompt gets updated over time to optimize the model's completion of the prompt. Prompt tuning is a very parameter efficient strategy because only a few parameters are being trained. In contrast with the millions to billions of parameters in full fine tuning, similar to what you saw with LoRA. You can train a different set of soft prompts for each task and then easily swap them out at inference time. You can train a set of soft prompts for one task and a different set for another. To use them for inference, you prepend your input prompt with the learned tokens to switch to another task, you simply change the soft prompt. Soft prompts are very small on disk, so this kind of fine tuning is extremely efficient and flexible. You'll notice the same LLM is used for all tasks, all you have to do is switch out the soft prompts at inference time.
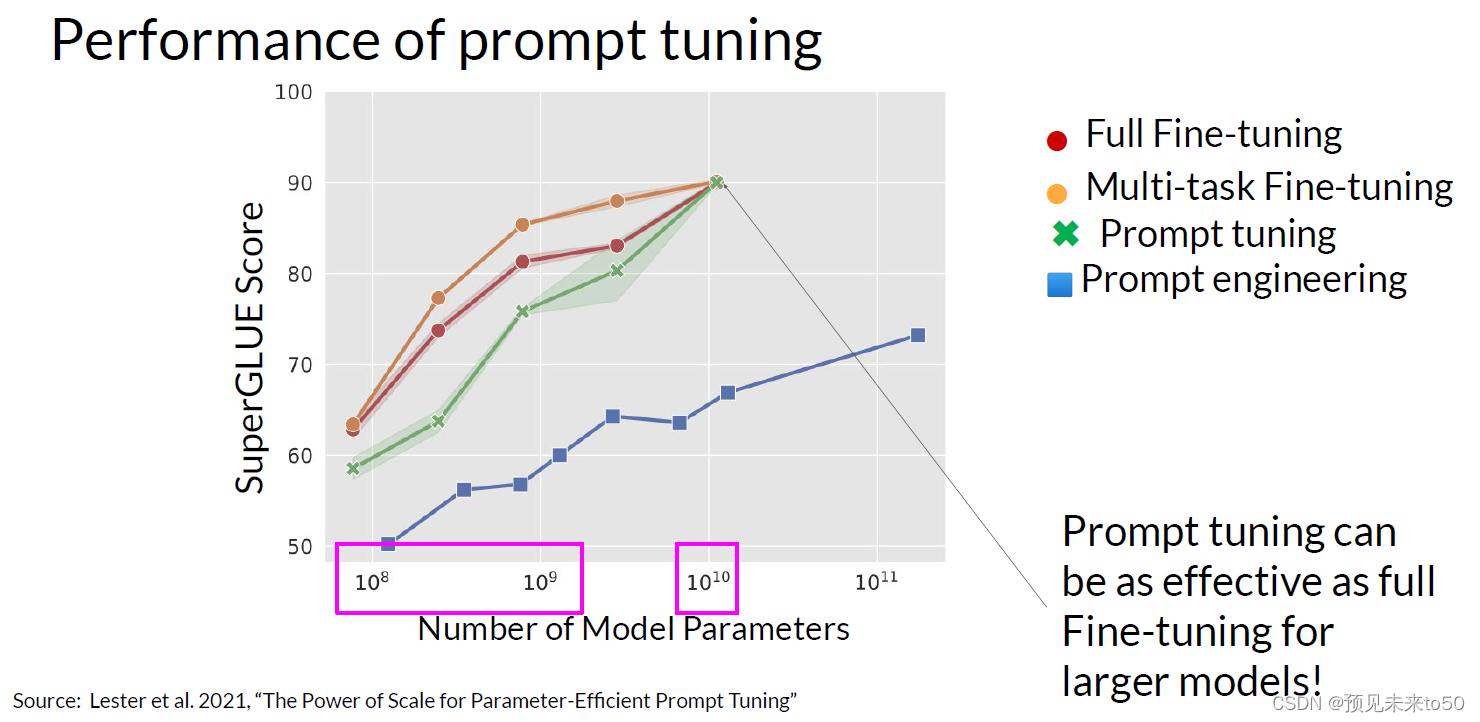
So how well does prompt tuning perform? In the original paper, Exploring the Method by Brian Lester and collaborators at Google. The authors compared prompt tuning to several other methods for a range of model sizes. In this figure from the paper, you can see the Model size on the X axis and the SuperGLUE score on the Y axis. This is the evaluation benchmark you learned about earlier this week that grades model performance on a number of different language tasks. The red line shows the scores for models that were created through full fine tuning on a single task. While the orange line shows the score for models created using multitask fine tuning. The green line shows the performance of prompt tuning and finally, the blue line shows scores for prompt engineering only. As you can see, prompt tuning doesn't perform as well as full fine tuning for smaller LLMs. However, as the model size increases, so does the performance of prompt tuning. And once models have around 10 billion parameters, prompt tuning can be as effective as full fine tuning and offers a significant boost in performance over prompt engineering alone.
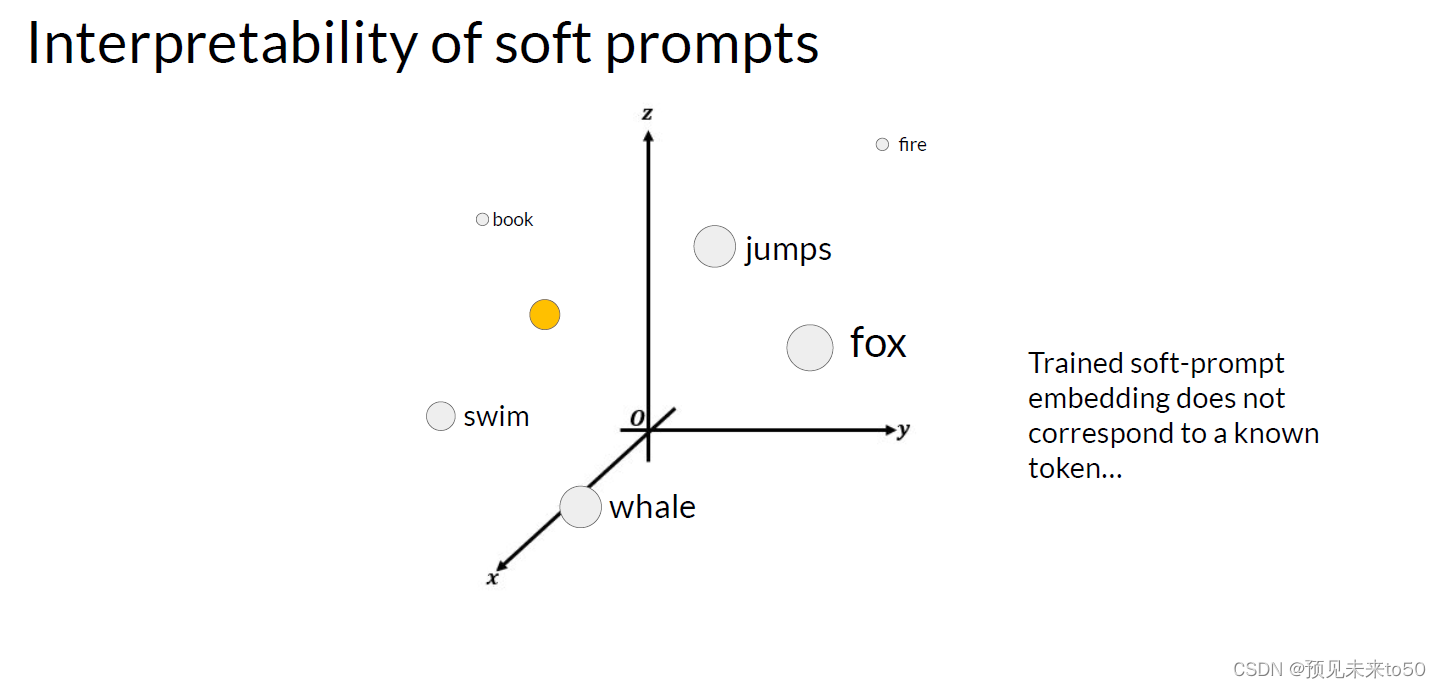
One potential issue to consider is the interpretability of learned virtual tokens. Remember, because the soft prompt tokens can take any value within the continuous embedding vector space. The trained tokens don't correspond to any known token, word, or phrase in the vocabulary of the LLM. However, an analysis of the nearest neighbor tokens to the soft prompt location shows that they form tight semantic clusters. In other words, the words closest to the soft prompt tokens have similar meanings. The words identified usually have some meaning related to the task, suggesting that the prompts are learning word like representations.

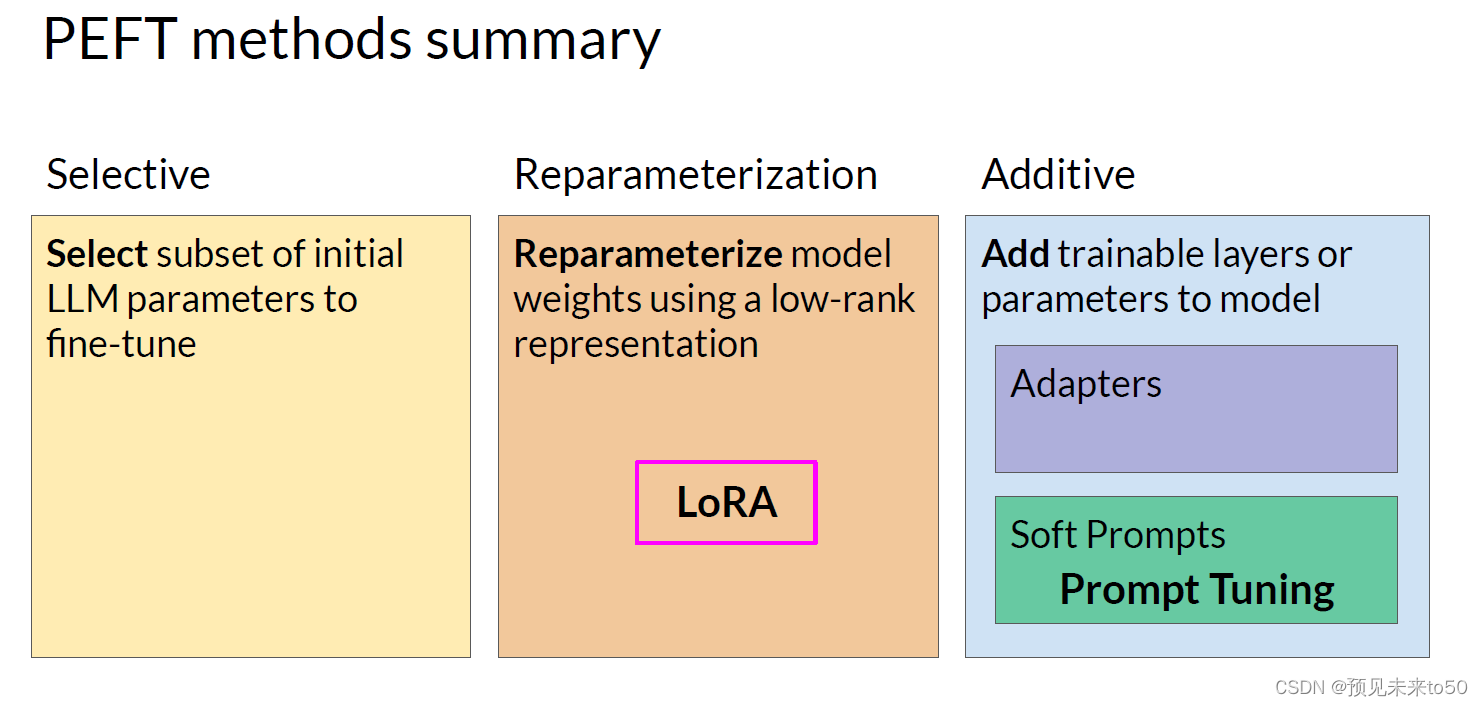
You explored two PEFT methods in this lesson LoRA, which uses rank decomposition matrices to update the model parameters in an efficient way. And Prompt Tuning, where trainable tokens are added to your prompt and the model weights are left untouched. Both methods enable you to fine tune models with the potential for improved performance on your tasks while using much less compute than full fine tuning methods. LoRA is broadly used in practice because of the comparable performance to full fine tuning for many tasks and data sets, and you'll get to try it out for yourself in this week's lab.
So congratulations on making it to the end of week 2. Let's recap what you've seen earlier this week, Mike walked you through how to adapt a foundation model through a process called instruction fine-tuning. Along the way, you saw some of the prompt templates and data sets that were used to train the FLAN-T5 model. You also saw how to use evaluation metrics and benchmarks such as ROUGE and HELM to measure success during model finetuning. In practice instruction finetuning has proven very effective and useful across a wide range of natural language use cases and tasks. With just a few hundred examples, you can fine tune a model to your specific task, which is truly amazing. Next, you saw how parameter efficient fine tuning, or PEFT, can reduce the amount of compute required to finetune a model. You learned about two methods you can use for this LoRA and Prompt Tuning. By the way you can also combine LoRA with the quantization techniques you learned about in week 1 to further reduce your memory footprint. This is known as QLoRA in practice, PEFT is used heavily to minimize compute and memory resources. And ultimately reducing the cost of fine tuning, allowing you to make the most of your compute budget and speed up your development process.
使用LoRA的目标是找到一种高效的方法来更新模型的权重,而不必重新训练每一个参数。在PEFT中也有附加方法旨在不改变权重的情况下提高模型性能。在这个视频中,你将探索第二种参数高效的微调方法,称为提示调优。
现在,提示调优听起来有点像提示工程,但它们彼此之间有很大的不同。通过提示工程,你会处理你的提示语言以获得你想要的完成。这可能像尝试不同的单词或短语那样简单,或者更复杂,比如包括一个或几个示例进行少量推理。目标是帮助模型理解你要它执行的任务的性质,并生成更好的完成。然而,提示工程有一些限制,因为它可能需要大量的手动工作来编写和尝试不同的提示。你还受到上下文窗口长度的限制,而且最终你可能仍然无法为你的任务获得所需的性能。
通过提示调优,你会在提示中添加额外的可训练标记,并将其最佳值的决定交给监督学习过程。这组可训练标记被称为软提示,并且会被添加到表示你的输入文本的嵌入向量前面。软提示向量与语言标记的嵌入向量具有相同的长度。包括大约20到100个虚拟标记就足以获得良好的性能。代表自然语言的标记是硬的,因为它们每个都在嵌入向量空间中对应一个固定的位置。然而,软提示不是自然语言的固定离散词。相反,你可以将它们视为可以在连续多维嵌入空间中取任何值的虚拟标记。通过监督学习,模型为这些虚拟标记学习特定任务的性能最大化的值。
在完全微调中,训练数据集由输入提示和输出完成或标签组成。在监督学习过程中会更新大型语言模型的权重。与提示调优相比,大型语言模型的权重被冻结,底层模型不会得到更新。相反,软提示的嵌入向量会随着时间更新,以优化模型对提示的完成。提示调优是一种非常参数高效的策略,因为只有少数几个参数被训练。与完全微调中的数百万到数十亿个参数相比,类似于你在使用LoRA时看到的情况。你可以为每个任务训练一组不同的软提示,然后在推理时轻松地切换它们。你可以为一个任务训练一组软提示,另一个任务则训练另一组。要在推理时使用它们,只需在你的输入提示前加上学习的标记,要切换到另一个任务,只需更改软提示。软提示在磁盘上非常小,所以这种微调非常高效和灵活。你会注意到同一个LLM用于所有任务,你所要做的就是在推理时切换软提示。
那么提示调优的表现如何呢?在原始论文《Exploring the Method》中,作者Brian Lester及其在谷歌的合著者比较了几种不同模型大小的其他方法。在论文的这张图中,你可以看到X轴上的模型大小和Y轴上的SuperGLUE得分。这是你本周早些时候了解到的评估基准,它根据许多不同的语言任务对模型性能进行评分。红线显示了通过在单个任务上完全微调创建的模型的得分。橙色线显示了使用多任务微调创建的模型的得分。绿线显示了提示调优的性能,最后,蓝线显示了仅使用提示工程的得分。如你所见,对于较小的LLMs,提示调优的表现不如完全微调。然而,随着模型大小的增加,提示调优的性能也会提高。一旦模型拥有大约100亿个参数,提示调优可以像完全微调一样有效,并且比单独使用提示工程提供显著的性能提升。
一个需要考虑的潜在问题是学习虚拟标记的可解释性。记住,因为软提示标记可以在连续嵌入向量空间中取任何值。训练后的标记不对应于LLM词汇表中的任何已知标记、单词或短语。然而,对软提示位置附近的最近邻标记的分析表明,它们形成了紧密的语义聚类。换句话说,最接近软提示标记的词语具有相似的含义。识别出的词语通常与任务有关的某种意义,表明提示正在学习类似词的表示。
在这节课中,你探索了两种PEFT方法:LoRA,它使用秩分解矩阵以高效的方式更新模型参数。和提示调优,其中将可训练标记添加到你的提示中,而模型权重保持不变。这两种方法都使你能够微调模型,在计算量远低于完全微调方法的情况下有潜在的性能提升。由于LoRA在许多任务和数据集上与完全微调的性能相当,因此在实践中被广泛使用,你将在本周的实验室中亲自尝试它。
祝贺你完成了第2周的学习。让我们回顾一下你本周早些时候看到的内容,Mike带你了解了如何通过一种称为指令微调的过程来适应基础模型。在此过程中,你看到了一些用于训练FLAN-T5模型的提示模板和数据集。你还了解了如何使用评估指标和基准(如ROUGE和HELM)在模型微调过程中衡量成功。在实践中,指令微调已被证明在广泛的自然语言用例和任务中非常有效和实用。只需几百个例子,你就可以将模型微调到你的特定任务,这真是令人惊奇。接下来,你了解了参数高效的微调或PEFT如何减少微调模型所需的计算量。你学到了两种可以使用的方法:LoRA和提示调优。顺便说一下,你还可以将LoRA与你在第1周学到的量化技术结合起来,进一步减少内存占用。这在实践中被称为QLoRA,PEFT被广泛用于最大限度地减少计算和内存资源。并最终降低微调的成本,让你充分利用你的计算预算并加速你的开发过程。















 4071
4071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









