







最近有做工程的朋友,让写一个爬虫获取某城市的历史天气数据。要求不高,主要是希望能代替人工搜索数据,代码总是比较方便。而我作为一个初学者正在练习爬虫的学习。所以代码并不是很漂亮,但是思路还是比较清晰规范的。顺便练习了正则对数据的提取,字符串的切片,pandas的dataframe基本使用。
爬取数据请遵守爬虫协议,遵守法律,仅用于学习交流,数据不要商业用途。
//先看爬取的网页//
http://tianqi.2345.com/wea_history/57516.htm
这个网页看起来很简洁,但是数据用普通的BeautifulSoup模块,获取不到。然后就是常用的network方法,试试能不能找到js数据。
可以看到用解析,find方法的话,层层叠叠,超级麻烦,主要解析后我也没找到数据。然后就是寻找js文件数据。

胡乱试了一下,还真的找到了。这个思路就是跟着网上冠状病毒数据爬取方法思路,我随便试试的。看来要多看代码,多重复别人的项目,才能有思路啊。
接下来模仿别人的做法,寻找js 文件的请求方法,提取数据。看了一下请求方式,是GET,于是设置请求头参数,按照请求地址去爬取。
最后数据,出来了,格式不是标准的json,无法jsonloads,直接获取数据。停留了好几天,最后百度加正则方法,虽然我的正则完全是停留在概念阶段。就当学习啦,各种试探,可以看到我的代码里面有很多注释,就是尝试过的各种正则。所以这次难点,并不是爬虫的写法,而是我的正则是尝试了几十次,终于学会了一点用法。
但取出来的数据还是带有很多标点,空格。怎么办,又歇了几天,干脆split(空格),把字符串转为列表,用手指头一个一个数序号,才比较工整地取出了数据。最后切片方法,去掉了标点符号。
以下是所有代码
import requests
import json
import pandas as pd
import re
from bs4 import BeautifulSoup
headers = {}
headers['user-agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' #http头大小写不敏感
headers['accept'] = '*/*'
headers['Connection'] = 'keep-alive'
headers['Pragma'] = 'no-cache'
url = "http://tianqi.2345.com/t/wea_history/js/201910/57516_201910.js" # 57516 代表重庆
res = requests.get(url)
a=res.text
data=json.dumps(a, indent=2,ensure_ascii=False)
#print(data[17:])
b=a.split('[')
#print(a)
#print(b[1])
c=b[1].replace('"','')
#d=c.split(',')
#e=str(d).split("{")
#print(e)
f=re.findall(r'\{(.*?)\}', str(c))
#g=re.findall(r'\{(.*?)\}', str(f))
#print(f[:])
tianqi=[]
for i in f[:-1]:
i={i.replace("'",'')}
xx= re.sub("[A-Za-z\!\%\[\]\,\。]", " ", str(i))
yy=xx.split(' ')
#print(yy)
tianqi.append([data[24:26], yy[3][1:], yy[10][1:-1], yy[17][1:-1], yy[24][1:], yy[34][1:],yy[41][1:], yy[45][1:],yy[53][1:]])
#print(tianqi)
print('日期 最高气温 最低气温 天气 风向风力 空气质量指数')
print(tianqi)
weather=pd.DataFrame(tianqi)
weather.columns=['城市',"日期","最高气温","最低气温","天气","风向",'风力','空气质量指数','空气质量']
weather.to_csv(str(data[24:26])+'.csv',encoding="utf_8_sig")
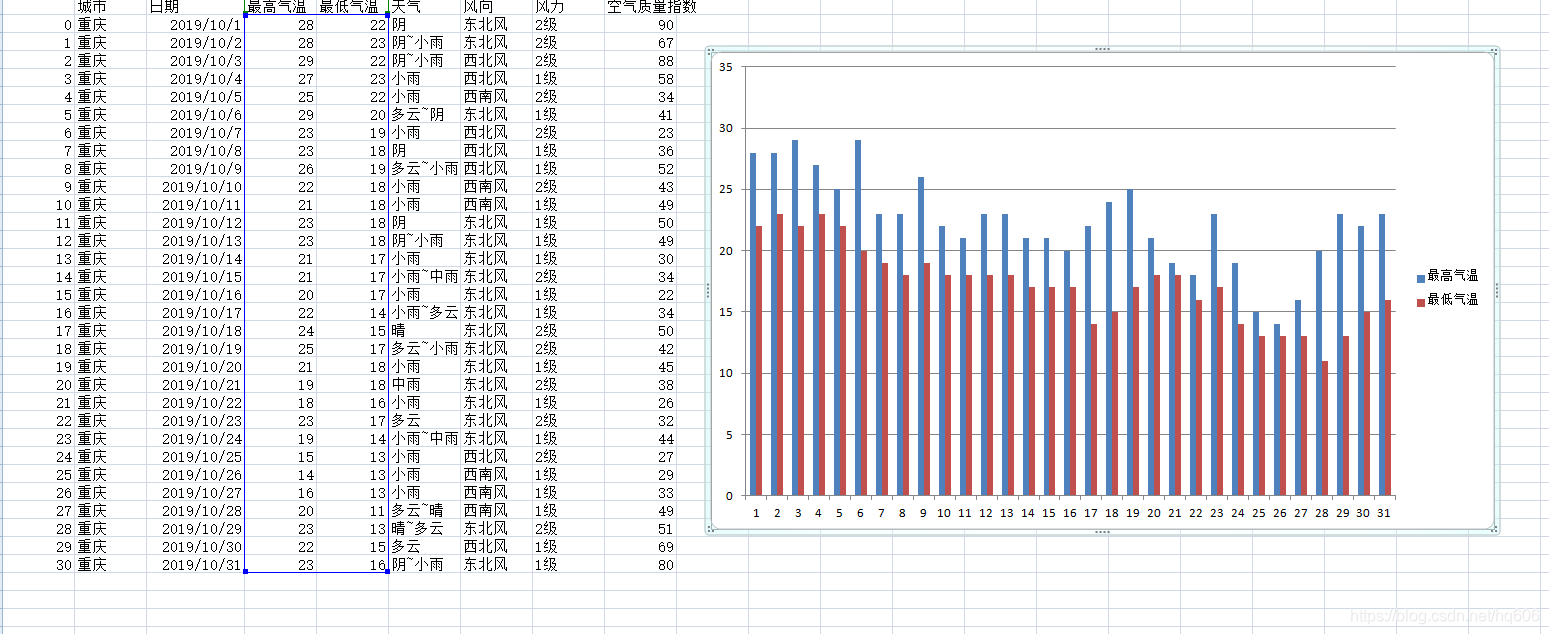
最后把数据传入pd.DataFrame,保存到csv文件。进行可视化绘图分析,以下就是结果了。这是我第一次爬取并处理json数据,总体不是很复杂,主要是练习了思路。这个小项目还算思路完整。值得总结。尤其正则方法的使用,实践证明是非常有效的。
第一次自己写的爬虫,用了十几天,出来结果,还是有点小激动的。特写一篇记录一下。小白可以参考。
想爬取其他城市和其他时间的,修改 http://tianqi.2345.com/t/wea_history/js/201910/57516_201910.js
这一句里面,201910/57516_201910,参数即可,比如,打开网页http://tianqi.2345.com/wea_history/57516.htm,这里57516代表重庆,201910代表2019年10月的所有天气。
(各地的城市编码在这里:http://tianqi.2345.com/js/citySelectData2.js)一般不会爬取那么多城市吧,挑几个你需要的城市放入程序。可以把我的爬虫做成函数,然后把城市代码做成参数,把城市编码放入列表,循环传参,拼接URL,一次把几个城市都爬取到。需要注意的是,weather.to_csv,的写入模式需要改成df.to_csv(文件名,mode=’a+’, )利用’a+’,追加写入,避免各个城市数据被覆盖。
最近有热心的同学发现一个问题,就是201602,201601,2015之前的数据爬取会报错,现在我来修复一下,前面爬取的原理没有问题,所以顺着原理,我找了一下js文件,发现之前的文件地址格式有所不同,大家改一下即可 比如 2016年1月的js地址要改成 http://tianqi.2345.com/t/wea_history/js/57516_20161.js
再就是 2015年以前的数据,没有空气质量那一项目,代码tianqi.append还有weather.columns那里要去掉最后两项,才能输出到csv文件
















 923
923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











