







 本文深入分析了Linux内核3.10.0版本中list.h文件中的哈希表实现,介绍了哈希表的基本概念、哈希函数构造及冲突处理方法,并详细解析了内核中哈希表的初始化、结点操作(添加、删除)、链表移动等关键代码。
本文深入分析了Linux内核3.10.0版本中list.h文件中的哈希表实现,介绍了哈希表的基本概念、哈希函数构造及冲突处理方法,并详细解析了内核中哈希表的初始化、结点操作(添加、删除)、链表移动等关键代码。
一、背景
本篇文章将先从对哈希表的基本介绍开始,然后分析linux内核(3.10.0版)中的list.h文件中的哈希表。
二、简述哈希表
根据设定的哈希函数H(key)和处理冲突的方法将一组关键字映像到一个有限的连续的地址集上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为哈希表。
上面这一段是从一本教材中摘抄出来的对哈希表的一段描述。
大家对数组的概念想必都不陌生,众所周知,数组通过数组号就可以找到对应的存储的数据。但数组的缺点也很明显,不便于增删数据。
大家对双向链表的概念也一定不陌生,双向链表比起数组,增删方便,但是查找数据就需要遍历整个链表,很费时费力。
如果可以有一个链表,既增添方便,也可以直接进行数据的访问而不必不断比较那就太好了。哈希表就是有类似这样的能力。
当然,我这样的说法并不严谨。但便于理解。
三、哈希函数的构造
可以想象,如果一个索引号对应着不止一个数据,那这时候就会有矛盾产生。到底对应着哪个数据呢?我们有必要构造哈希函数来使一组关键字的哈希地址均匀分布在整个地址区间中,从而减少冲突。
常用构造哈希函数的方法有:(1)直接定址法 (2)数字分析法 (3)平方取中法 (4)折叠法 (5)除留余数法 (6)随机数法
具体的可以查阅相关资料。
四、处理冲突的方法
常用的处理冲突的方法有:(1)开放定址法 (2)再哈希法 (3)链地址法 (4)建立一个公共溢出区
具体的可以查阅相关资料。
五、list.h文件的哈希表的构造与实现分析
在linux kernel 3.10.0版本中,list.h位于include/linux目录下。
我们先来看一看list.h中哈希表的构造:
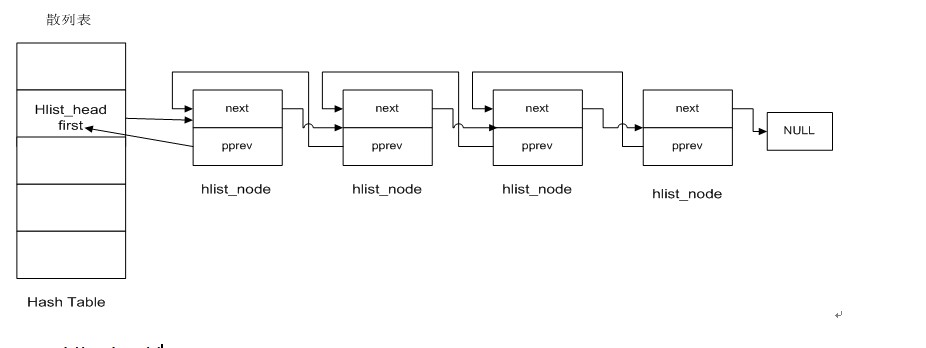
可以看到,linux内核处理冲突的方法是链地址法。思想是:将所有关键字为同义词的结点链接在同一个链表中。若选定的哈希表长度为m,则可将哈希表定义为一个由m个头指针组成的指针数组。就如上图所示。
在linux内核中定义哈希表头结点与结点的代码位于types.h文件中。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 452
452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









