







YOLOv1的讲解
背景:首先介绍一下这篇文章的背景,我们都知道目标检测分为一阶段和二阶段,甚至一开始的R-CNN还是多阶段网络,但无论是二阶段还是多阶段都不是端到端的,训练起来较为复杂。本文正是一阶段网络,虽然准确率在当时并不是最好的,但作者所提出的看法还是值得深思。
思想

为了加快模型的计算速度,以及增强上下文的相关性。作者直接将整张图像作为模型的输入,此外作者把整张图像分成SxS个小区域(默认的做法S=7),小区域称作grid,每一个grid预测B个bounding box(默认B=2) 的坐标参数(分别为归一化后的中心点坐标x,y以及归一化后的矩形框的高h和宽w)、两个bounding box的置信度confidnce和每个grid对应的20个类别概率p(因为文章是在PASCAL VOC上做的实验,总的类别数为20,因此默认长度为20)。
通过上述介绍我们就可以知道我们模型的输出为:尺寸大小=S * S * (B * (4+1) +20),S取7,B取2,则尺寸=49 * 30 (注意这仅是对于输入图像数量为1的情况);另外输出数值的大小都会通过模型最后的Sigmoid函数约束到[0~1]之间(也可以暂时被称为归一化后的输出,后续测试过程中作图的时候会将部分数值进行相关的缩放,具体的操作,在后面部分我会详细说明)。
模型结构
在介绍完文章的输入输出外,想必大家的心理就会更加清晰一点。以下为文章采用的网络(借鉴了GoogleNet),同样的情况,此处我说明一下模型的输入与输出是什么,以及关键是怎么得到输出的。输入:整张图像RGB,输出:在由前端的卷积池化操作后得到7 * 7 * 1024尺寸大小的特征图,随后通过两个连续的全连接层(注意一下文章这里画的图是1x1的卷积层,但我们需要知道的一点是1x1的卷积层作用在通道方向上的效果与全连接层是一样的),因此再通过一个Sigmoid激活函数得到归一化后的输出49 * 30。

训练阶段
相信介绍到这的时候,大家最起码对模型的输入输出是什么已经有了大致的了解。下面将是本文的重点:作者如何训练模型。既然牵扯到如何训练模型,那么就必须要弄懂文中所运用的损失函数。
总的损失函数分为五个部分,我会依次讲解,并详细说明其中的每一个变量是什么意思。
- 含目标(object)的正样本的中心点损失(暂定为L1)
以下为L1的损失公式:
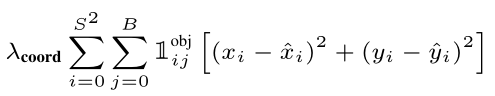
首先S=7,B=2,其中变量的含义分别为:
1 i j o b j 1_{i j}^{obj} 1ijobj:含有目标(object)的bounding box,训练的时候,会依据模型输出的每一个预测的bounding box的相关信息与真实的bounding box计算IOU,将计算得到的IOU最大的bounding box标为正样本,即认为是含有目标的bounding box,此时 1 i j o b j 1_{i j}^{obj} 1ijobj=1,否则为0。这里还需要介绍的一个重要的点,相信这也是大家十分关注的地方,那就是之前不是说了模型输出的中心点的坐标( x i x_i xi, y i y_i yi)都是归一化后的吗,如果是归一化,那么它与真实bounding box的中心点坐标( x − i {\mathop{x}\limits^{-}}_i x−i, y − i {\mathop{y}\limits^{-}}_i y−i)是如何计算差值的呢(这是因为这里的真实的中心点坐标是归一化后的,具体的做法是将原真实box的中心点坐标先减去当前所处的grid的左上角坐标,随后再除以grid 的尺寸大小)。同理当我们想要将归一化后的中心点恢复到原数值,只需要反过来计算就可以。
至于 λ c o o r d λ_{coord} λcoord的介绍放在后面部分一起说明原因。 - 含目标(object)的正样本的宽高损失(暂定为L2)
以下为L2的损失公式:
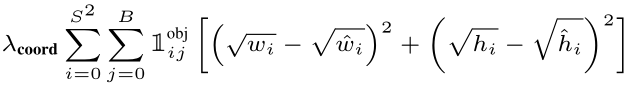
1 i j o b j 1_{i j}^{obj} 1ijobj:此处的含义与L1一样。
w i \sqrt{{w_i}} wi、 w − i \sqrt{{\mathop{w}\limits^{-}}_i} w−i、 h i \sqrt{{h_i}} hi、 h − i \sqrt{{\mathop{h}\limits^{-}}_i} h−i:分别指的是归一化后的预测bounding box与真实bounding box的宽和高,归一化的公式为原box的高和宽除以图像的高和宽。此外,我们肯定会问:为什么这里作者需要给变量加上根号呢。那是因为对于不同尺寸的bounding box中心点偏移相同的距离对IOU的影响力是不同的。因此正如公式L1中表示的那样,在 x i x_i xi- x − i {\mathop{x}\limits^{-}}_i x−i两次具有相同大小的时候,如果我们的L2采用 w i w_i wi - w − i {\mathop{w}\limits^{-}}_i w−i的方式计算差值,就意味我们将两种不同尺寸对IOU造成的影响力当成一样的看待了。因此为了体现出这种由于不同尺寸大小对IOU带来的影响,需要对差值公式就行修改。鉴于大尺寸有更大的影响力,所以采用 w i \sqrt{{w_i}} wi - w − i \sqrt{{\mathop{w}\limits^{-}}_i} w−i的形式,来拉开大尺寸差值于小尺寸差值之间的差距。(注意是不同尺寸差值之间的差距大小)。此处如还是不怎么理解,就试着带入一些具体数值,看看是否拉开了两者之间原本的差距。(当然如果不会举例带入,就在下方留言,我会给出具体解释)。
λ c o o r d λ_{coord} λcoord:与L1中一样。 - 有目标(object)的置信度损失(暂定为L3)
以下为L3的公式:
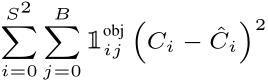
C i C_i Ci:预测的每一个bounding box对应的置信度,已经被缩放到[0~1]范围内。
C − i {\mathop{C}\limits^{-}}_i C−i:真实bounding box对应的置信度,此处我们需要详细介绍什么是置信度,以及它是怎么计算的。在文中,作者将置信度定义为预测box中有目标的概率Pr(object)乘以当前预测的bounding box与真实的bounding box计算得到的IOU。即作者是将 C − i {\mathop{C}\limits^{-}}_i C−i定义为实际训练过程中的真实置信度,那么值得注意的是这个值是不断变化的,至于作者为什么要这么设计,我也没太搞懂,不过在其他很多的复现项目中,大多的工作是将 C − i {\mathop{C}\limits^{-}}_i C−i设为1去2计算损失。 - 无目标(bject)的置信度损失(暂定为L4)
以下为L4的公式:
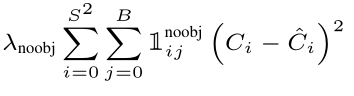
1 i j n o o b j 1_{i j}^{noobj} 1ijnoobj:无目标的bounding box,与L1中的 1 i j c o o r d 1_{i j}^{coord} 1ijcoord的含义相反,如果没有目标 1 i j n o o b j 1_{i j}^{noobj} 1ijnoobj=1,否则为0。
λ n o o b j λ_{noobj} λnoobj:与 λ c o o r d λ_{coord} λcoord一样分别为L4,L1,L2的损失权重(默认 λ c o o r d λ_{coord} λcoord=5, λ n o o b j λ_{noobj} λnoobj=0.5),那么为什么需要加上权重损失呢。主要的原因是在于:在训练的时候由于图像中所包含的真实bounding box 的数量是十分少的,而我们都知道每一个真实的bounding box只对应一个预测的bounding box,这便会导致训练的时候出现正样本数量不足的情况,进而影响模型的训练效果。因而加上损失权重,加大正样本的损失占比,不至于导致训练失衡。 - 每个grid对应的类别损失(暂定为L5)
以下为L5的公式:
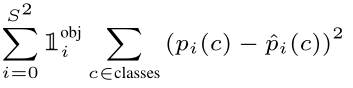
1 i o b j 1_i^{obj} 1iobj:指的是含有目标的grid,判定的方法为若真实bounding box的中心点坐标落在该grid’当中,则 1 i o b j 1_i^{obj} 1iobj=1,否则为0。
p i ( c ) p_i(c) pi(c)、 p − i ( c ) {\mathop{p}\limits^{-}}_i(c) p−i(c):分别指的是预测的每一个grid的类别概率值和真实的类别概率(默认为1)。
以下便是总损失函数,以及整个训练过程,接下来我会介绍测试阶段的算法流程。

测试阶段

上图表示为整个测试阶段的流程。现在我们知道一张图像经过该模型将会输出49 * 30 尺寸大小的特征信息,含义指的就是:49个grid,其中每一个grid包含两个bounding box 的信息(中心点坐标x,y,高h,宽w,置信度confidence【是直接预测出来的,并不是计算IOU得到的】)以及20个类别概率。得到模型的输出之后,将置信度confidence与类别概率相乘,得到类别置信度class-confidence,也就是我们常说的得分score。然后我们会先设定一个得分阈值,将小于阈值的bounding box过滤掉,最后同非极大值抑制NMS方法去除冗余重叠的bounding box。NMS这一部分不是文章的重点,具体做法大致先挑选出最高得分的bounding box然后与其他剩余的bounding box计算IOU,如果在计算过程中,某一个bounding box的IOU大于设定好的阈值就将该bounding box去除,将当前得分最高的bounding box保留至另一个预测框集合中,并将其从当前框集合去除,随后对剩余的框集合重复上述的操作,最终得到我们想要的bounding box。到了这里,本文算法流程的介绍也快结束了,此时可能还会有一个疑惑,那就是文章中的grid说负责某一个目标的检测是怎么体现的呢。其实对于这个问题,主要还是回到关于每一个grid中对应的两个bounding box 的中心点坐标预测的问题,因为我们要知道无论是训练还是测试过程中这两个bounding box的中心点坐标都没有超过该grid,也就形成了每个grid对固定位置是否含有目标的检测效果。
总结
该文章是十分不错的,如果中间的理解存在一些纰漏,希望大家指正,一起进步,谢谢!,后续我也会对YOLOv2进行讲解,如果感兴趣的话,多多支持。















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









