









关于对Faster-RCNN的个人理解
背景

在这之前已有加快版的Fast-RCNN,但是由于候选区域仍然是特别的多的(大约有2000个),这就会导致在后续的类别预测以及box修正这个地方计算量特别大,预测速度很慢,并且很难学习这么多个样本。因此,本文的目的还是想要去加速网络的预测速度。
思想
先回顾一下Fast-RCNN的算法流程,首先是将整幅图像作为网络的输入,随后将SS算法得到的2000个候选区域映射到特征图上,得到对应的特征向量,接着再预测这2000个候选区域的类别概率以及box的修正参数。从上述的表述中,我们可以感觉到Fast还是很慢的,因为需要一次处理2000个候选框。基于该问题,Faster提出了新的解决方案,决定利用专门的模块用于推理出我们希望的候选框,数量是十分少的,并且在预初的定位上是准确的,而不是像之的SS算法,一次性输出2000个候选区域,增加了计算法复杂度的同时,还增大了模型训练和预测的难度。
模型结构

以上便是算法的整个流程图,如图所示,首先将整张图像送入到CNN中提取信息,得到相应的特征图。假如得到的特征图尺寸为13 * 13 ,紧接着会先将其送入到RPN模块推算候选区域(与Fast得到候选区域的方式是不同的)。至于RPN具体的做法则是:思想则是将上述得到的特征图当成是YOLO系列中的grid一样,每一个grid预测9个anchor(anchor具有三个宽高比以及三个面积:宽高比=(1:2,1:1,2:1),面积=(
12
8
2
128^2
1282,
25
6
2
256^2
2562,
51
2
2
512^2
5122),因此每个grid产生9个anchor)。于是分别使用两个卷积层得到每个anchor是否有目标的类别概率(2个:有目标的概率,背景概率)以及每个anchor的box修正参数(四个:中心点缩放比,宽高缩放比)。
对于是否为背景的类别预测器:输入为13 * 13,接着使用out_channel=18,k=3,s=1,p=1的卷积核得到196 * 18 的输出(代表196个grid对应的9个anchor是否为背景的概率),注意最后每一个anchor对应的两个概率需要经过Softmax函数(使得概率和为1)。
对于候选区域预测器:输入为13 * 13,同样使用out_channel=36,k=3,s=1,p=1的卷积核得到196 * 36 的输出(代表196个grid对应的9个anchor对应生成候选区域的位置参数)。
在通过RPN得到相应的候选区域后,然后再将这些候选区域送入到ROI模块中缩放尺寸,最后预测这些候选区域的类别概率以及每一个候选区域对应的预测bounding box的修正参数(与Fast是相同的,这里不再赘述)。

训练阶段
对于模型训练部分,由于该算法存在两个预测部分,因此需要分开谈。首先对于RPN中预测了候选区域的背景概率以及候选区域位置参数,我将其定为L1损失。而在后续关于对候选区域的类别预测以及box修正参数,将其定为L2损失。
- 以下为L1损失公式:
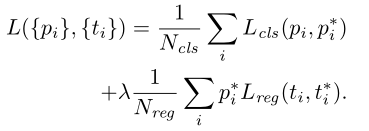
N c l s N_cls Ncls:代表参与损失计算的所有正负样本的总个数,在Faster中与Fast不同的是,并不是将所有的anchor都用于损失的计算。具体的做法则是:先从所有的anchor中随机选取256个anchor,参与正负样本的判定以及类别损失计算,因此 N c l s N_cls Ncls=256。
关于正样本的判定:首先将所有的anchor与GT计算IOU,如果计算结果超过设定的阈值(默认为0.7),则标为正样本,或者是在第一个条件前提下,将与GT计算IOU最大的anchor也标为正样本。【注意一下这里,其实我有点没太搞懂一个问题,那就是按照以上两个条件,如果一个anchor同时满足多个GT之间IOU的条件,那该怎么办呢,并且假如按照第一个IOU>0.7的条件已经为每一个GT找到了相应的anchor,那么是否还需要计算第二个条件呢,文章并没有给出详细的解释。这里给出我的想法:首先我们会计算每一个anchor与所有的GT之间的IOU,特殊情况:如果一个anchor与多个GT都超过了0.7,则只匹配最大的IOU的GT,这样我们就可以使得一个anchor只会对应一个GT,接着会出现两个情况:1、如果每一个GT在第一个条件下都找到了自己的anchor,则不需要再判断第二个条件,2、如果有一个GT在第一个条件下并没有匹配到anchor,则在已经匹配到GT剩余的anchor中计算IOU,然后选取最大的anchor,并将其标为正样本】
关于负样本的判定:除去正样本以外,如果一个anchor与所有的GT计算IOU,结果都小于设定的阈值(默认为0.3),则标为负样本。仅参与类别损失。其余剩下的anchor我们忽略不计。并且值得注意的是:正样本与负样本比例为1:1,如果正样本的个数不足128个,则使用负样本进行填充,使得总样本个数保持为256个。
p i ′ p_i^{'} pi′:代表真实标签概率,不为背景则第一个概率值为1,为背景则第二个概率值为1。
N r e g N_{reg} Nreg:代表输入特征图的尺寸,此处应该为13 * 13=196个。
p i ∗ p_i^{*} pi∗:代表被标定为正样本的anchor,正样本为1,负样本为0。
t i t_i ti, t i ∗ t_i^* ti∗:分别代表预测的候选区域参数,以及真实GT对应anchor的真实标签参数。以下为两者的计算公式,基本上与Fast计算box是一样的,只不过都被缩放到了【0~1】。
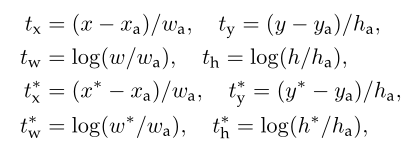
- 以下为L2公式:
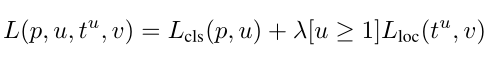
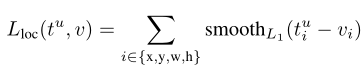
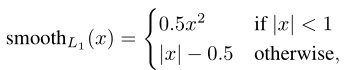
与Fast是一样的,在这不再赘述。只不过我们需要注意的一个点:输入的候选区域的数量是不同的,在Fast中是直接2000个,而在Faster中则是先有RPN阶段得到的候选区域,然后将得到的候选区域再映射到之前的输出特征图上,通过Pooling层拉伸到相同尺寸,再预测每个候选区域的类别概率以及box位置参数。那么需要注意的是:此时的正负样本的判定方式是按照预测的位置参数得到的候选区域与GT重新计算IOU判定的,与Fast一样,进而计算相关损失。最大的改进其实就是这里,需要计算的候选区域的数量变少了。
测试阶段
与之前类似,都是运用NMS算法,去除重叠框,不再赘述。
总结
如理解存在纰漏,敬请指正,谢谢!















 7123
7123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









