







机器学习-回归
个人理解,回归模型的输出是连续的数值,类似于数学中的曲线拟合。
目前我所知道的回归模型以线性模型为主,按照正则项范数的不同分为岭回归(L2范数)和LASSO回归(L1范数)
回归模型,除了十分简单的任务外,基本都需要靠正则来约束模型参数,因为面对复杂问题,其参数会非常多,而这个时候模型在经过训练数据后会变得很复杂,特别容易过拟合,特别是线性模型(好像线性模型就是线性回归这里讲的比较多,非线性模型在神经网络这块?),面对测试数据,复杂模型泛化能力就比较差了,所以正则化是必要的。
正则化都是奥卡姆剃刀,简化模型,告诉模型说你不要啥事都考虑,简单点,预测的时候简单点!
L2范数正则相对温柔一点,把参数在一个球里缩放,不至于强制变为0,一些相关性比较强的因素的系数就会大一些,另一些不那么相关的因素的系数就收缩得小一些。它的原理是假设参数空间服从正态分布。
L1范数正则相对干脆一些,对影响不大的因素,直接让其变为0。这样模型参数规模就一下降了下来,变得简单许多,虽然在训练集上误差会更大,但泛化性能却更好。它的原理是假设参数空间服从拉格朗日分布。
可以看到,这两个正则都是为参数赋予了一定的先验分布,属于了有着全局视角的外挂了。
假设模型
模型分类
回归模型按因变量数量个数,可以分为一元回归模型,二元回归模型,多元回归模型。
按照最高次数,回归模型可分为线性回归模型,二次回归模型,多次回归模型。
以上都是我个人总结,不代表教科书观点。
回归分析的主要算法包括(来自网络):
- 线性回归(Linear Regression)
- 逻辑回归(Logistic regressions)
- 多项式回归(Polynomial Regression)
- 逐步回归(Step Regression)
- 岭回归(Ridge Regression)
- 套索回归(Lasso Regression)
- 弹性网回归(ElasticNet)
线性模型
线性模型是最常用的回归模型,不仅是因为线性模型最简单,而且因为线性模型蕴含着很多重要的数学思想,这些思想一直用到了现在(概率论,度量学)。另外通过一定组合,线性模型也能构造出强大的非线性模型(比如神经网络,其实每个神经元就是一个线性模型)。
线性模型简单形式如下:
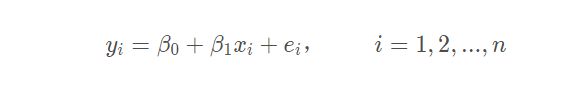
完整形式:

可以看出,线性回归的模型可以说就是线性函数家族。
模型误差
回归模型的误差以真值和预测值之间的欧式距离和来计算。
该定义方式首先符合人的直观,距离越近,预测得越好,其次,可通过严格推导,欧式距离最小等价于正太分布下最大后验估计。
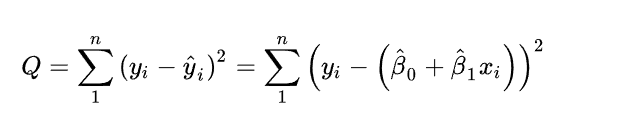
这里需要提问,为什么我们不要求点一定在拟合的线上?
原因是,做不到呀,哪有那么理想的数据或者模型。其实是可以做到的,在我们的脑海中!我们脑海中想象有这么一个理想模型,完美拟合真值,但实际模型却和实际数据有偏差,因为实际数据包含噪声。于是这里的Loss其实就是理想模型下实际数据的噪声大小,但噪声服从正态分布时,欧式距离最小对应于后验概率最大的情况,这是我们最有把握的模型。
模型的训练
模型训练分为两步,一个是寻找下降的方向,一个是寻找按这个方向走多大一步。
在这一节中,课程主要用了批处理梯度下降法确定下降方向,这种方法可以综合利用所有数据,但缺点是数据量太大时效果会很低。
走多长就是学习率的问题,分为固定学习率和自适应学习率。
参考
线性回归模型的原理、公式推导、Python实现和应用 - 知乎 (zhihu.com)
(1条消息) 线性回归模型详解(Linear Regression)_taoKingRead的博客-CSDN博客_线性回归模型
d的博客-CSDN博客_线性回归模型](https://blog.csdn.net/iqdutao/article/details/109402570)














 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









