







集成学习算法
1 集成学习介绍
集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
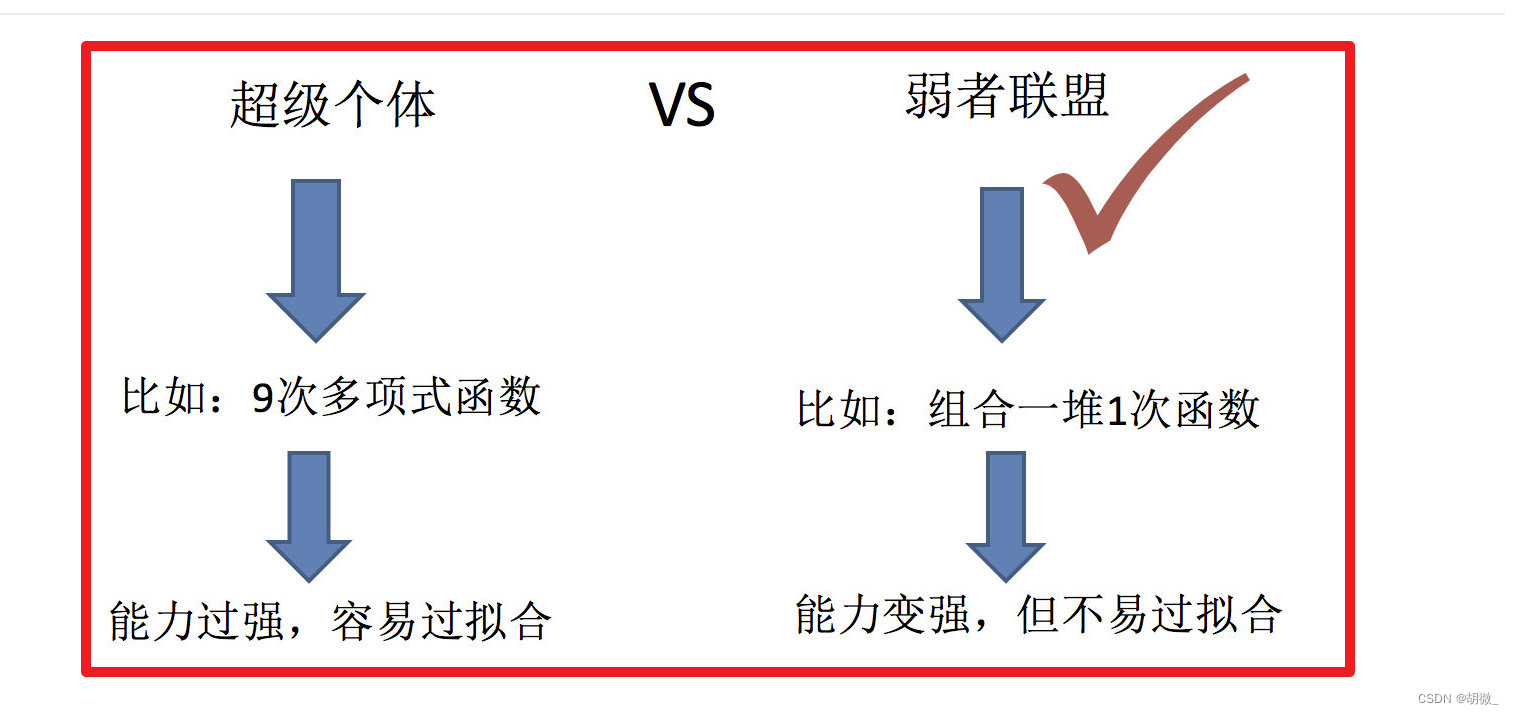
机器学习的两个核心任务
- 如何优化训练数据 —> 主要用于解决欠拟合问题
- 如何提升泛化性能 —> 主要用于解决过拟合问题
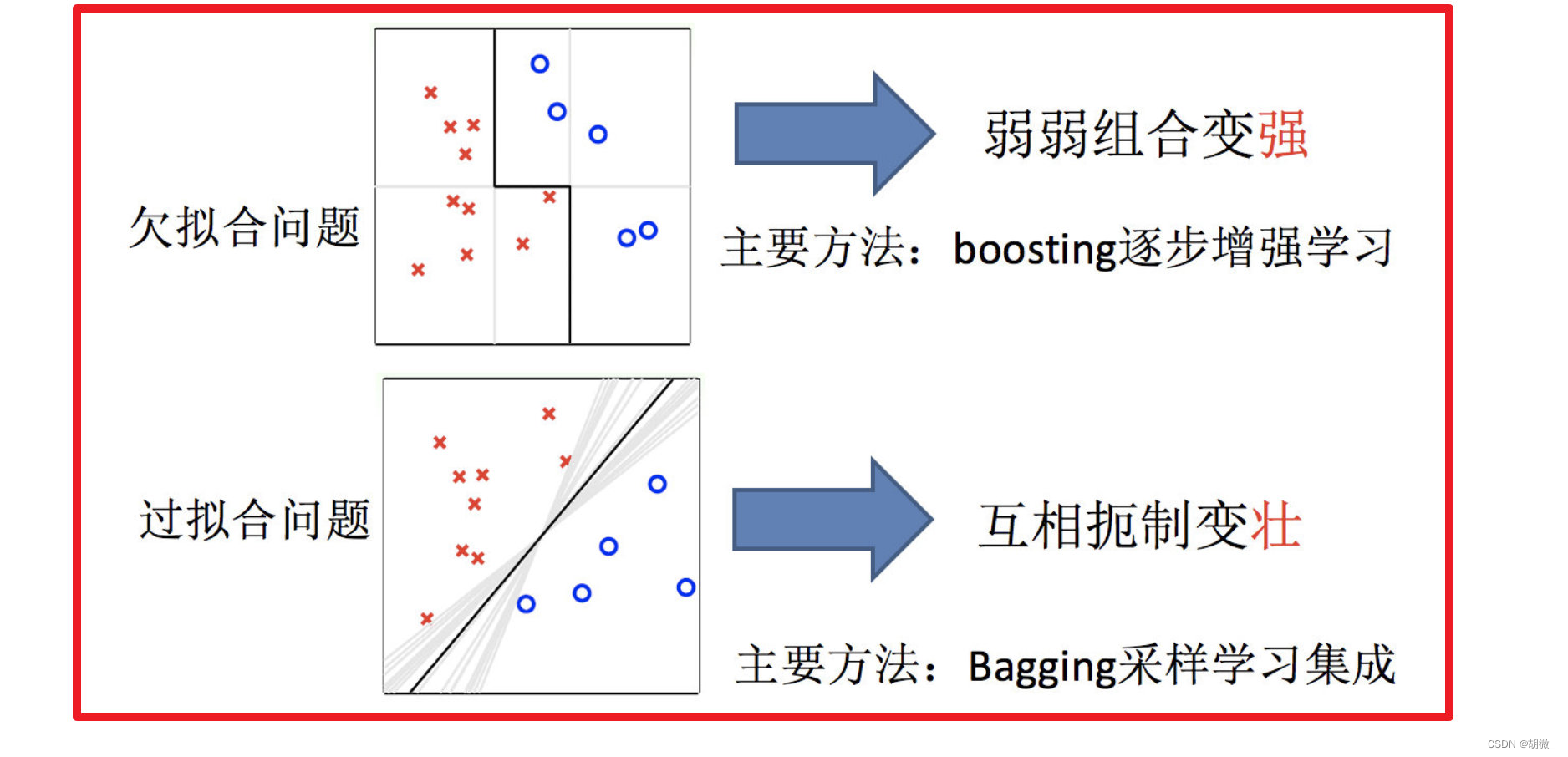
只要单分类器的表现不太差,集成学习的结果总是要好于单分类器的
2 Bagging介绍
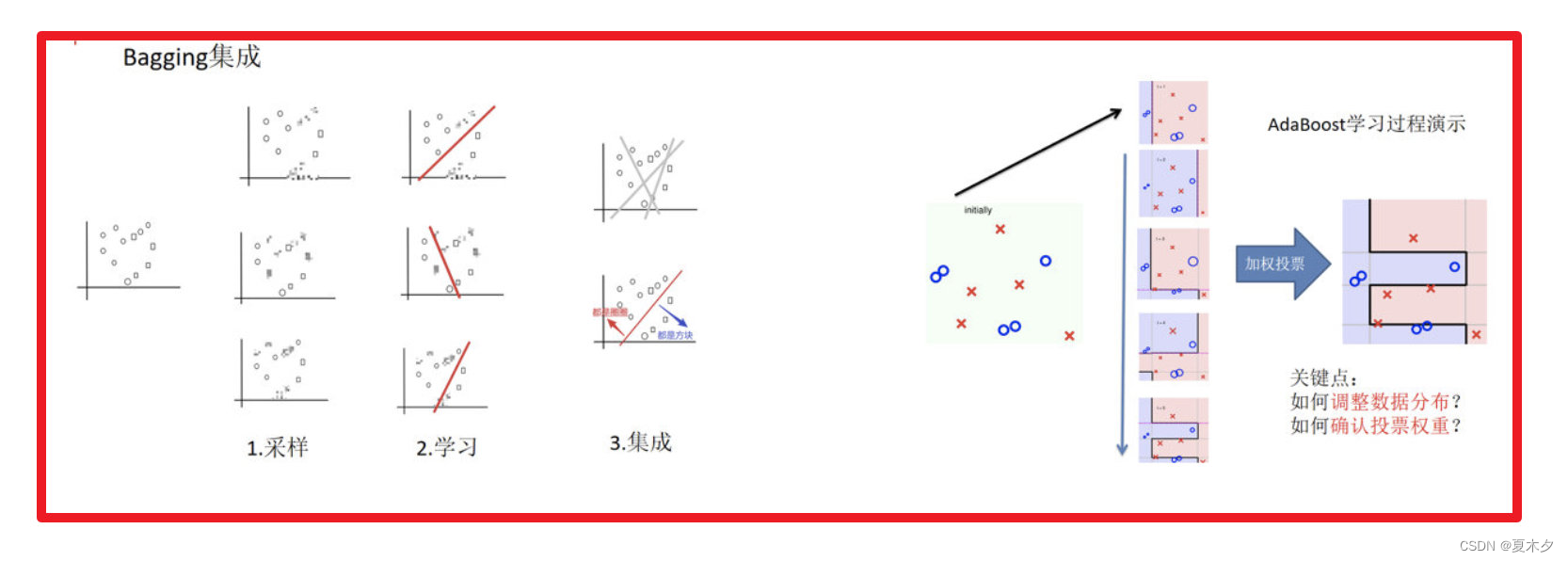
2.1 Bagging 集成原理
目标:把下面的圈和方块进行分类
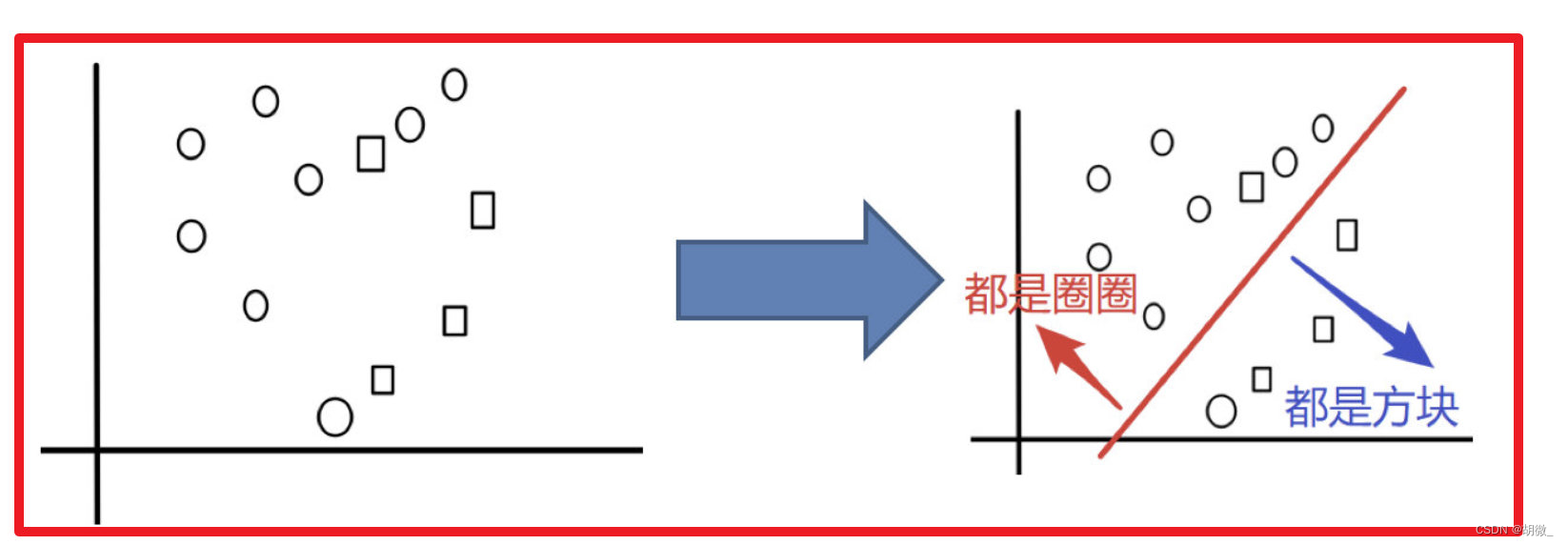
实现过程:
(1)采样不同数据集
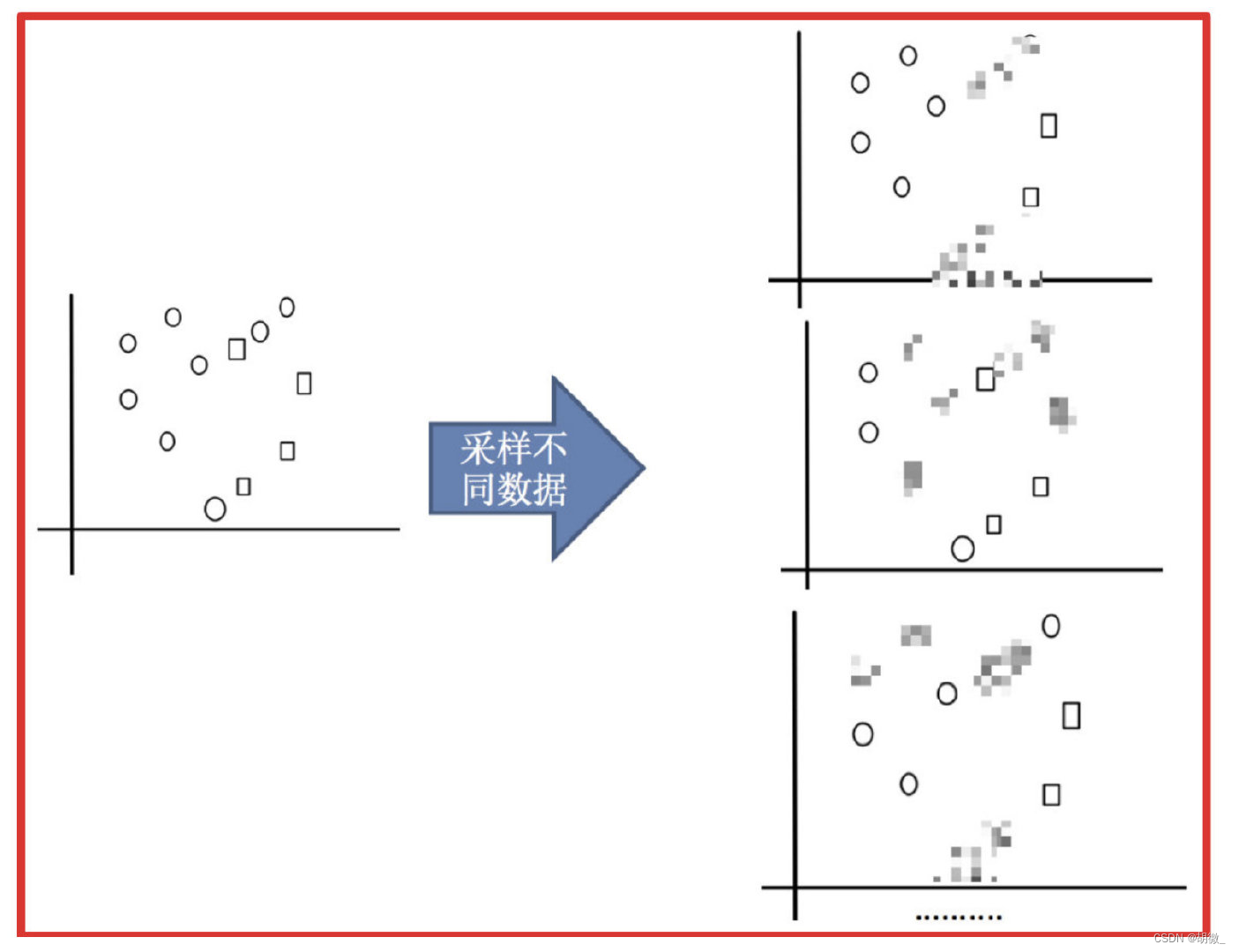
(2)训练分类器
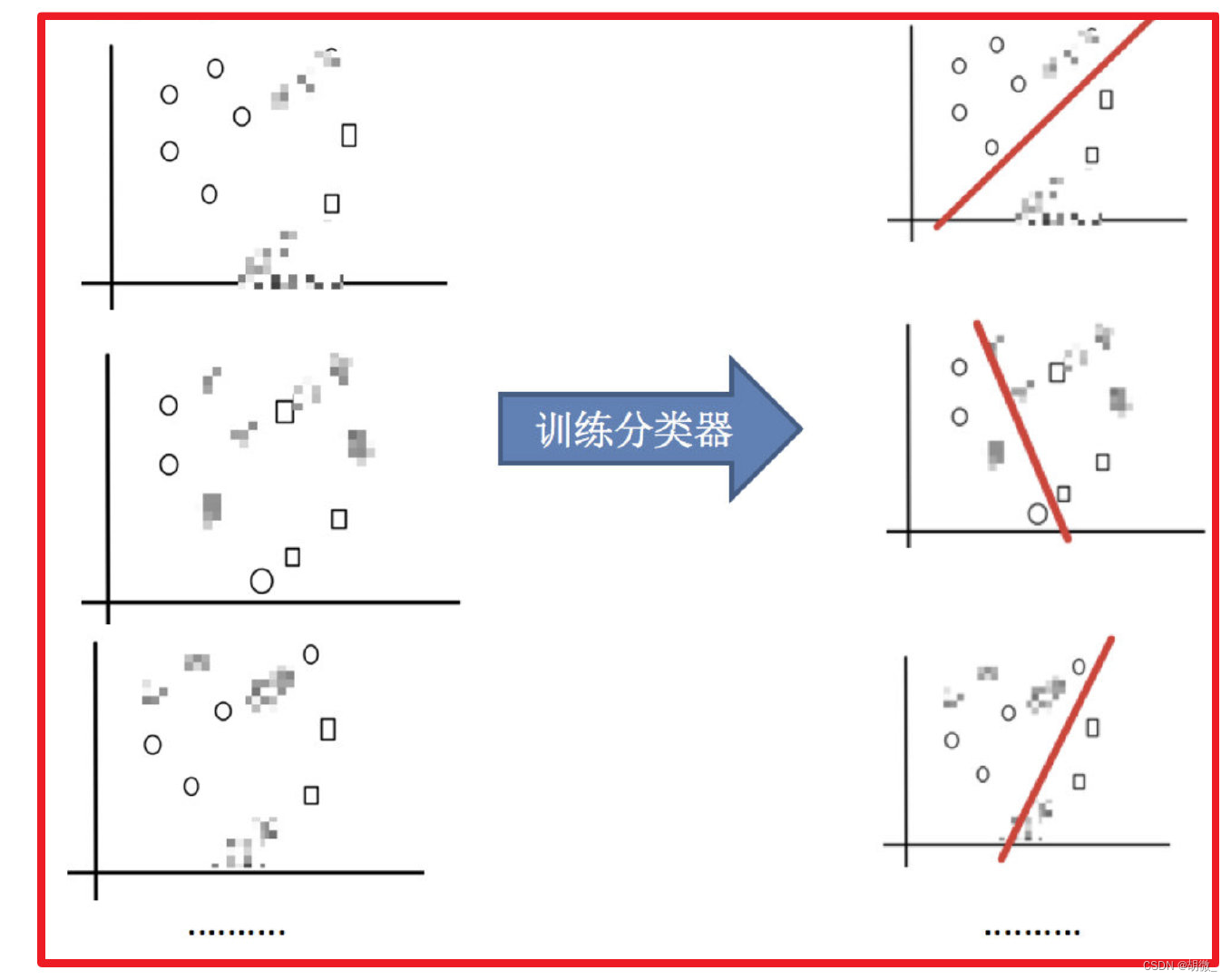
(3)平权投票,获取最终结果
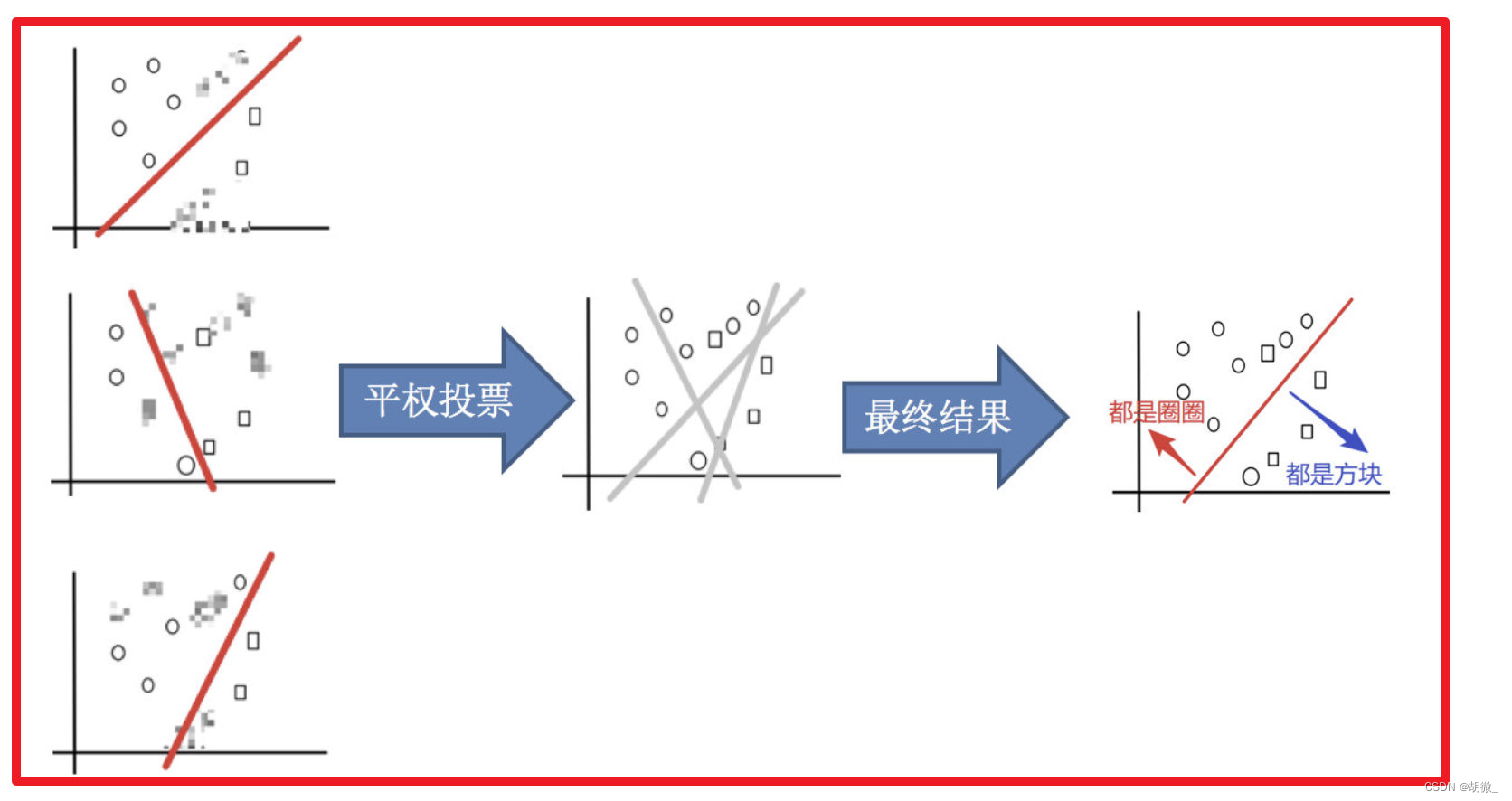
主要实现过程小结:
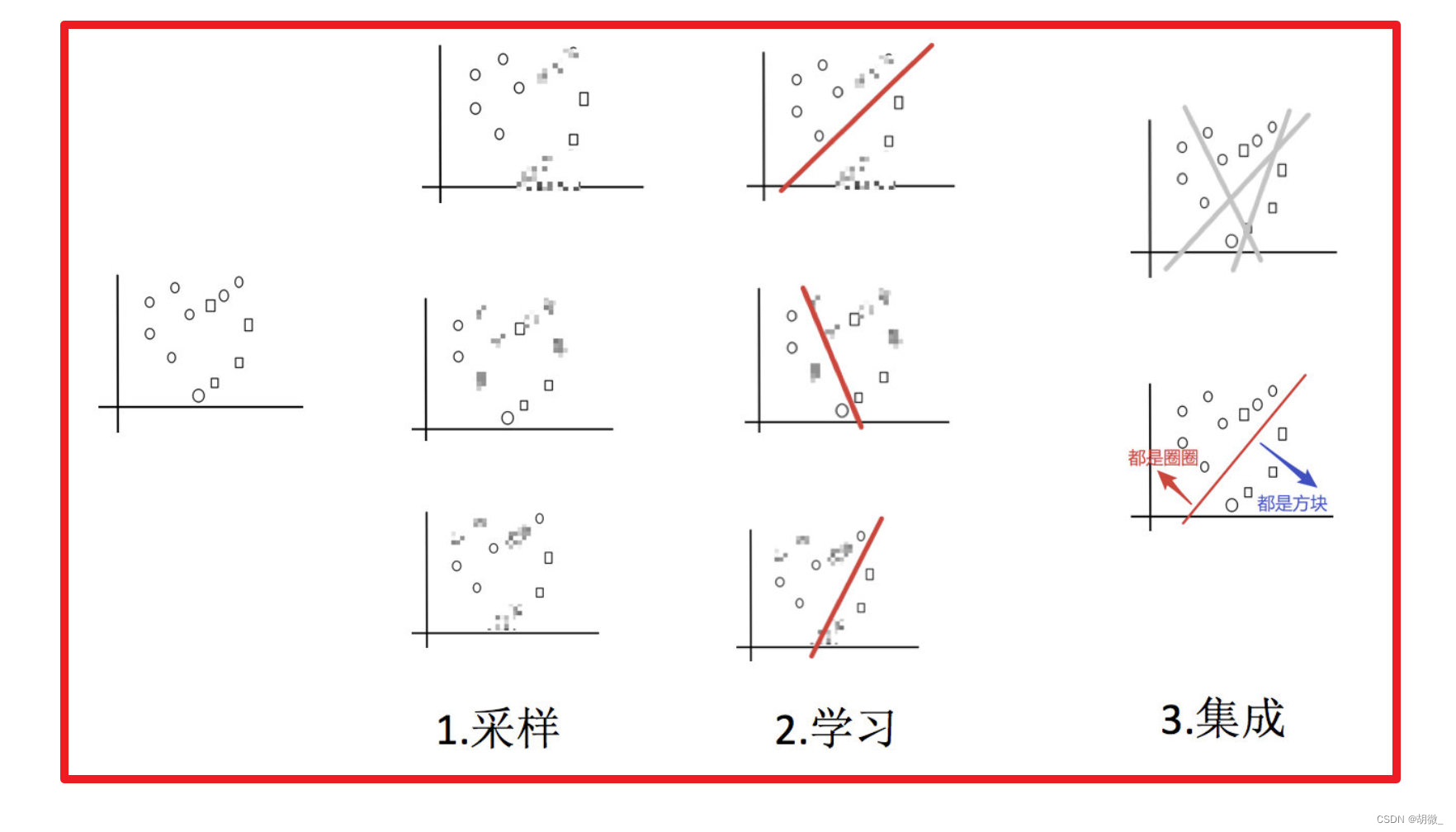
2.2 随机森林
随机森林是 Bagging 的一个特例
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
随机森林 = Bagging + 决策树
2.2.1 随机森林的构造
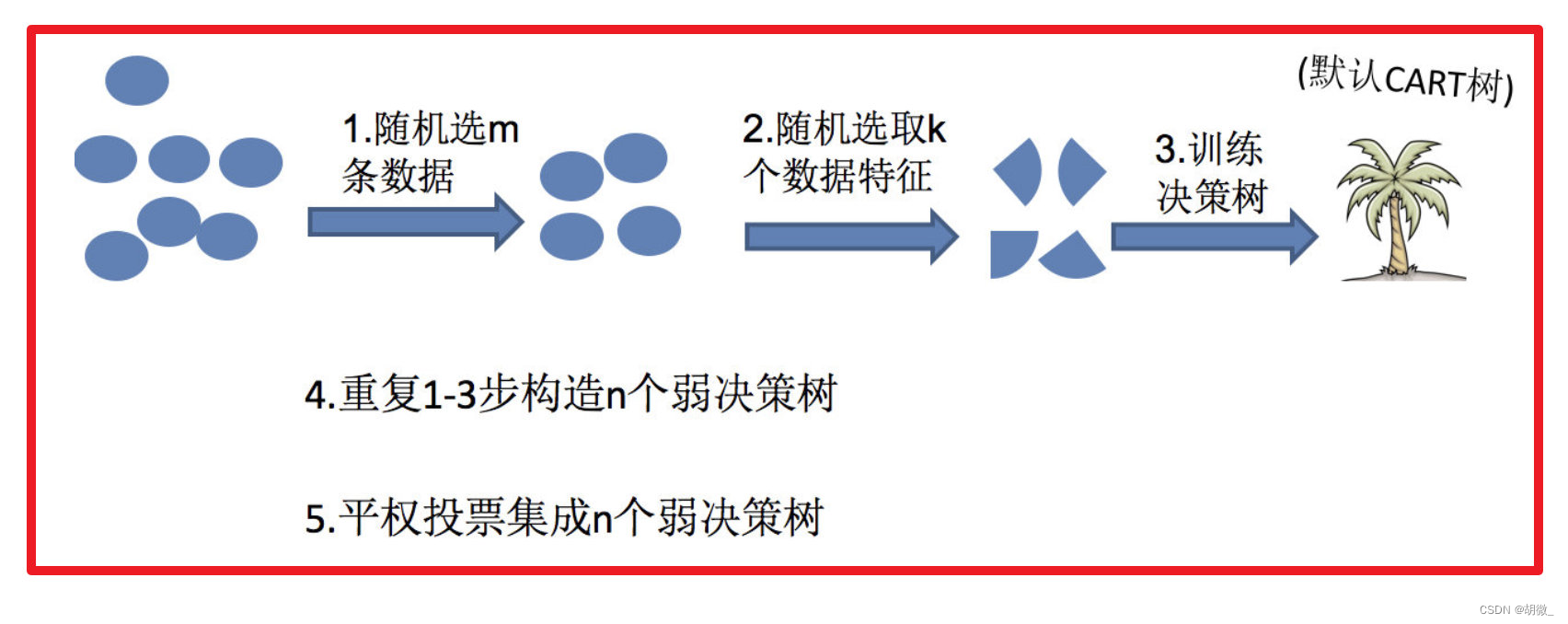
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个树的结果是False, 那么最终投票结果就是True
随机森林够造过程中的关键步骤(M表示特征数目):
- 一次随机选出一个样本,有放回的抽样,重复N次(有可能出现重复的样本)
- 随机去选出m个特征, m << M,建立决策树
思考:
- 为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的- 为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
2.2.2 包外估计
在随机森林构造过程中,如果进行有放回的抽样,我们会发现,总是有一部分样本我们选不到。
- 这部分数据,占整体数据的比重有多大呢?
- 这部分数据有什么用呢?
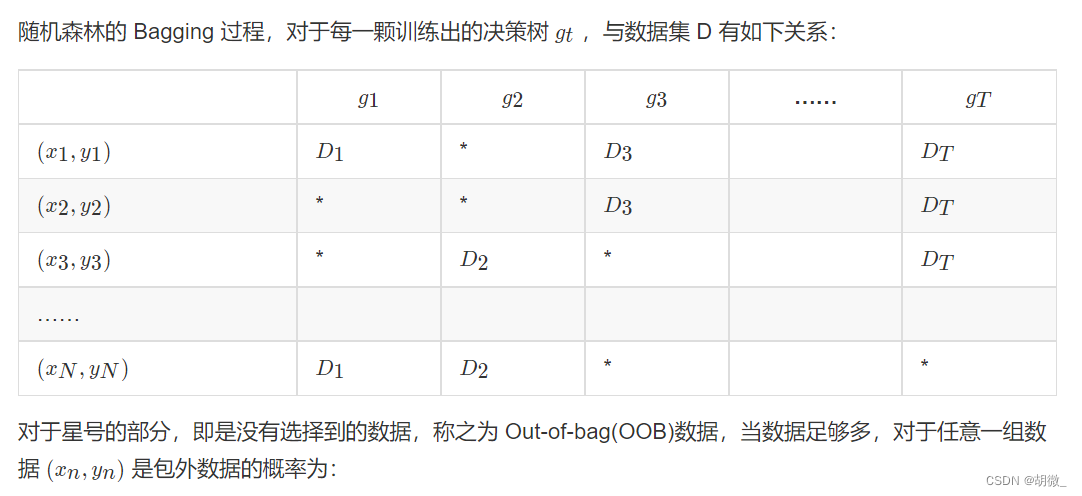

由于基分类器是构建在训练样本的自助抽样集上的,只有约 63.2% 原样本集出现在中,而剩余的 36.8% 的数据作为包外数据,可以用于基分类器的验证集。
经验证,包外估计是对集成分类器泛化误差的无偏估计
无偏估计:就是认为所有样本出现的概率一样
有偏估计:就是偏重那些出现次数多的样本,认为样本的概率是不一样的
包外估计的用途
- 当基学习器是决策树时,可使用包外样本来辅助剪枝 ,或用于估计决策树中各结点的后验概率以辅助对零训练样本结点的处理;
- 当基学习器是神经网络时,可使用包外样本来辅助早期停止以减小过拟合 。
2.2.3 随机森林api介绍
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
-
n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200- 在利用最大投票数或平均值来预测之前,你想要建立子树的数量。
-
Criterion:string,可选(default =“gini”)- 分割特征的测量方法
-
max_depth:integer或None,可选(默认=无)- 树的最大深度 5,8,15,25,30
-
max_features="auto”,每个决策树的最大特征数量- If “auto”, then max_features=sqrt(n_features).
- If “sqrt”, then max_features=sqrt(n_features)(same as “auto”).
- If “log2”, then max_features=log2(n_features).
- If None, then max_features=n_features.
-
bootstrap:boolean,optional(default = True)- 是否在构建树时使用放回抽样
-
min_samples_split内部节点再划分所需最小样本数- 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分,默认是2。
- 如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
-
min_samples_leaf叶子节点的最小样本数-
这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝, 默认是1。
-
叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。
-
-
min_impurity_split: 节点划分最小不纯度- 这个值限制了决策树的增长,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。
继续使用 机器学习算法(4)—— 决策树算法 一文中“泰坦尼克号乘客生存预测” 案例
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
estimator = RandomForestClassifier()
# 定义超参数的选择列表
param = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5, 8, 15, 25, 30]}
# 使用GridSearchCV进行网格搜索
estimator = GridSearchCV(estimator,param_grid=param,cv=2)
estimator.fit(x_train,y_train)
score = estimator.score(x_test,y_test)
注意:
- 随机森林的建立过程
- 树的深度、树的个数等需要进行超参数调优
2.2.4 随机森林案例
2.3 Bagging 小结
Bagging + 决策树/线性回归/逻辑回归/深度学习… = bagging集成学习方法
经过上面方式组成的集成学习方法:
- 均可在原有算法上提高约2%左右的泛化正确率
- 简单, 方便, 通用
3 Boosting
3.1 Boosting 集成原理
随着学习的积累从弱到强
简而言之:每新加入一个弱学习器,整体能力就会得到提升
代表算法:Adaboost,GBDT,XGBoost,LightGBM
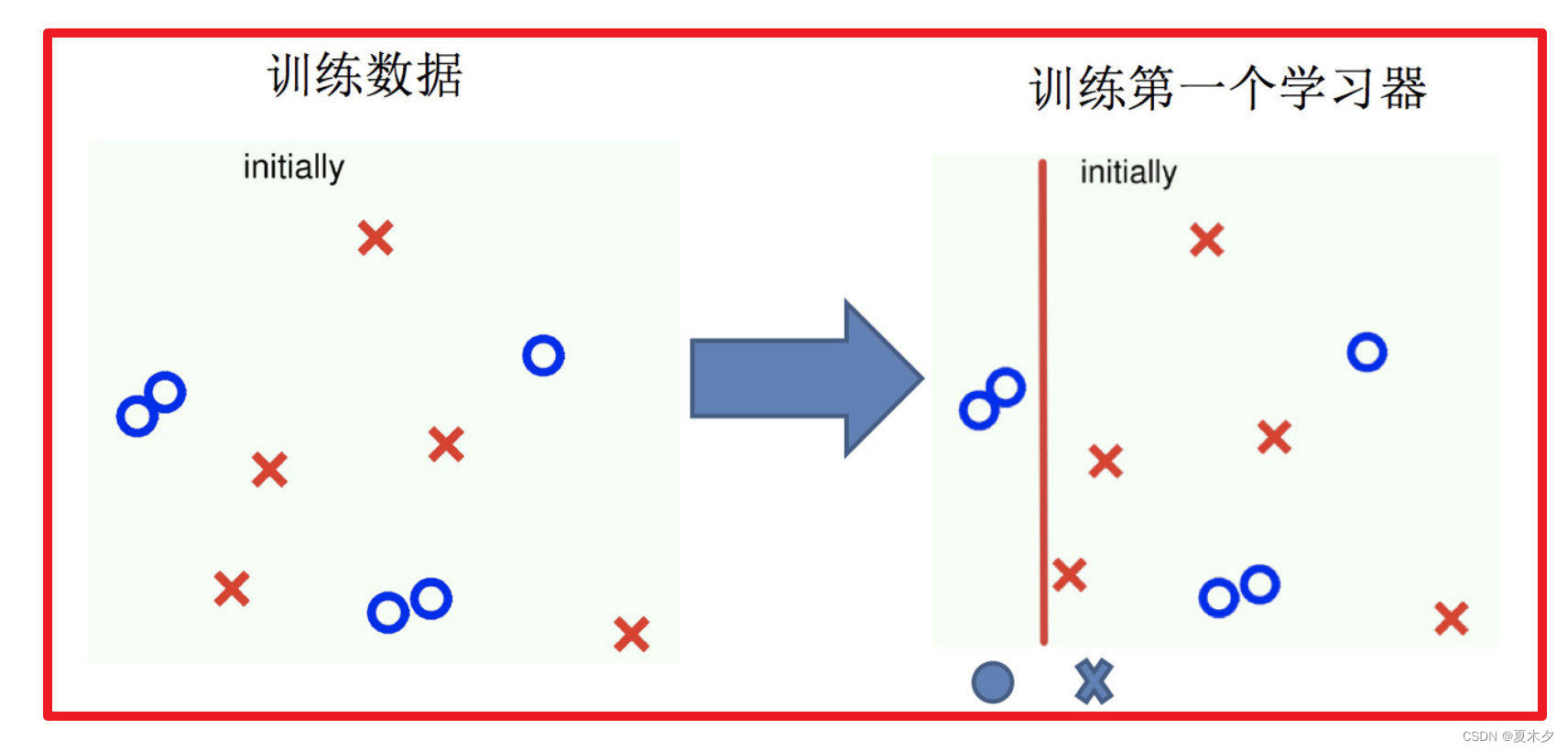
实现过程:
- 训练第一个学习器
- 调整数据分布
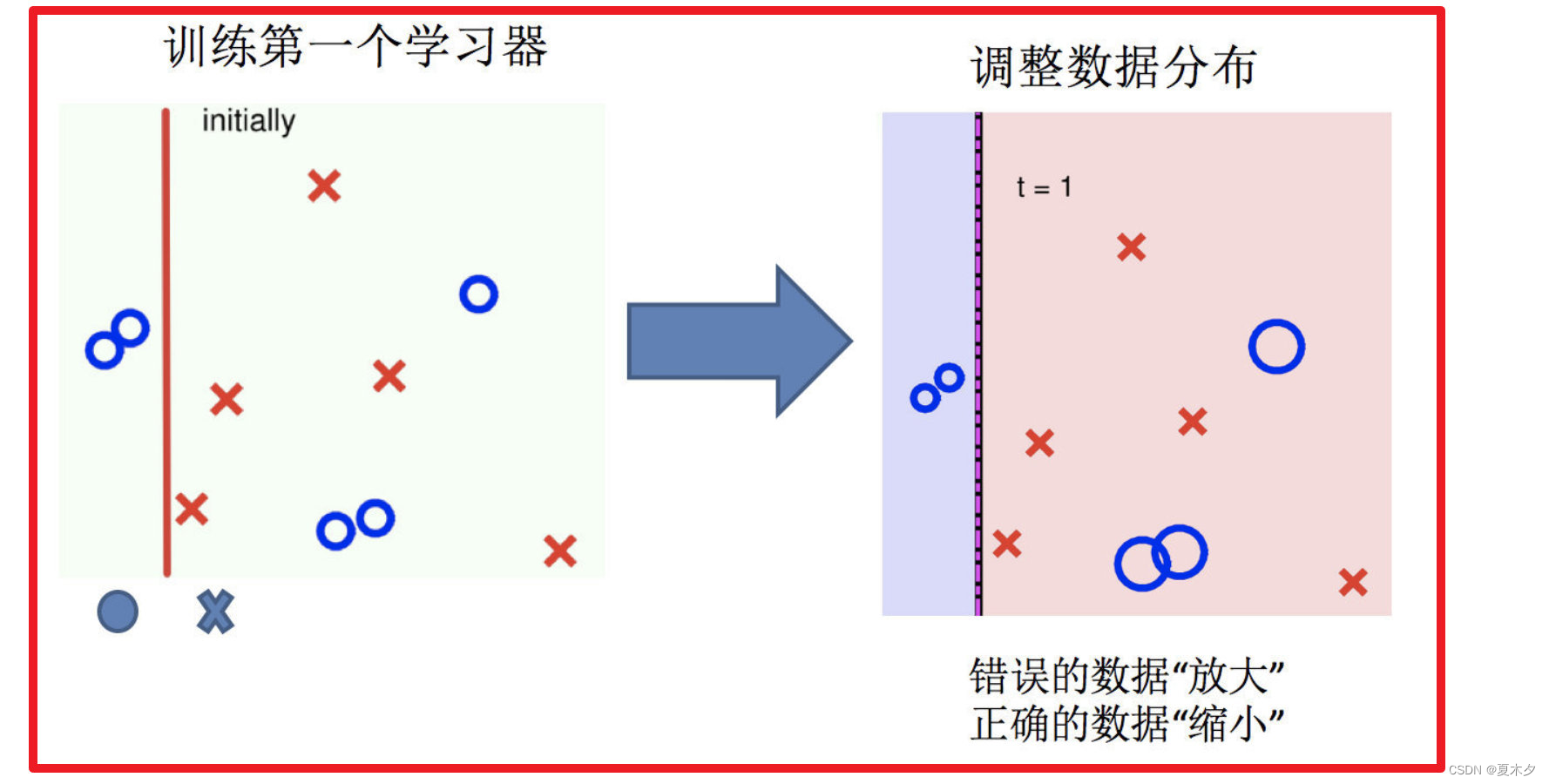
3. 训练第二个学习器
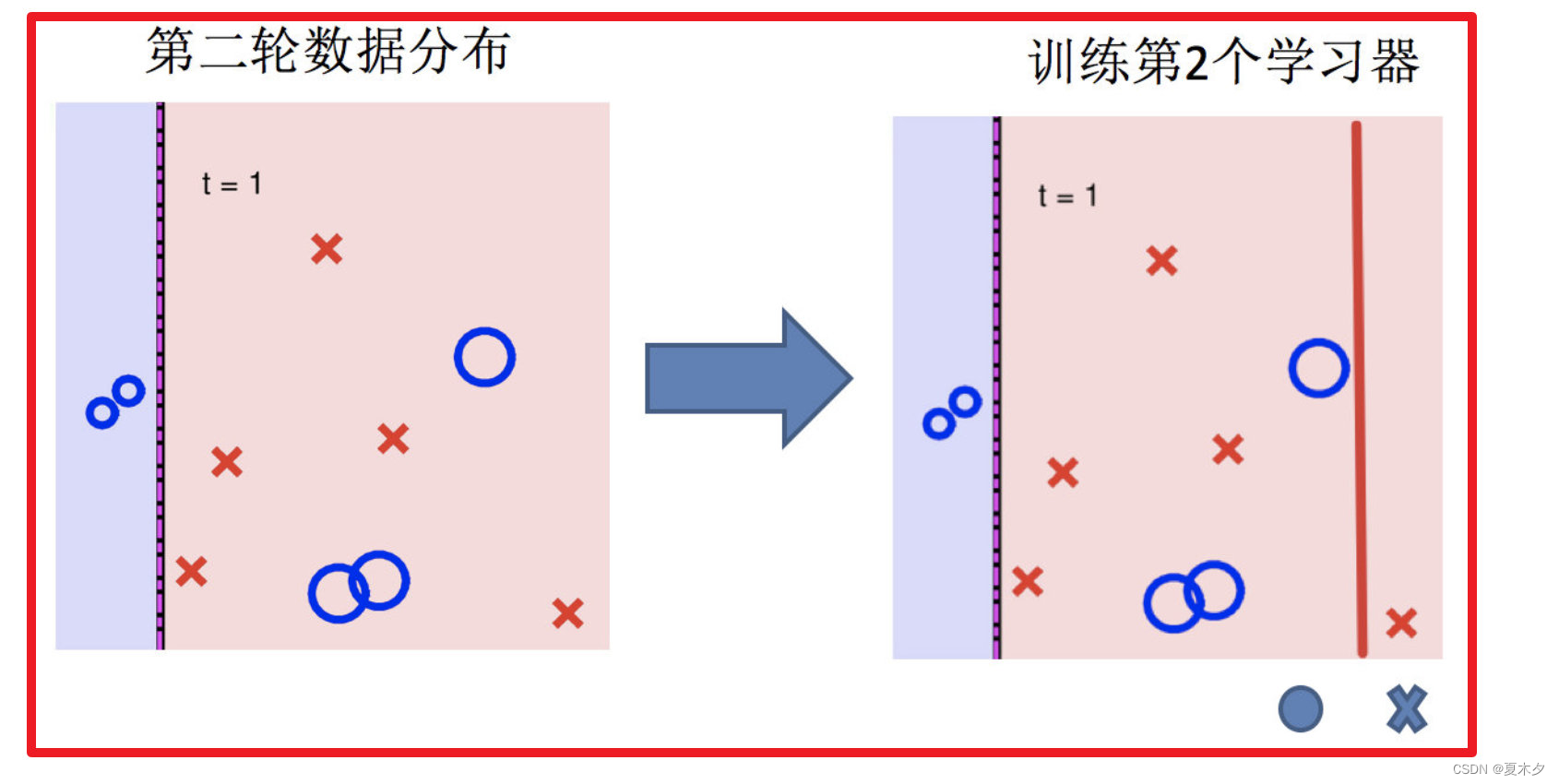
4. 再次调整数据分布

5. 依次训练学习器,调整数据分布
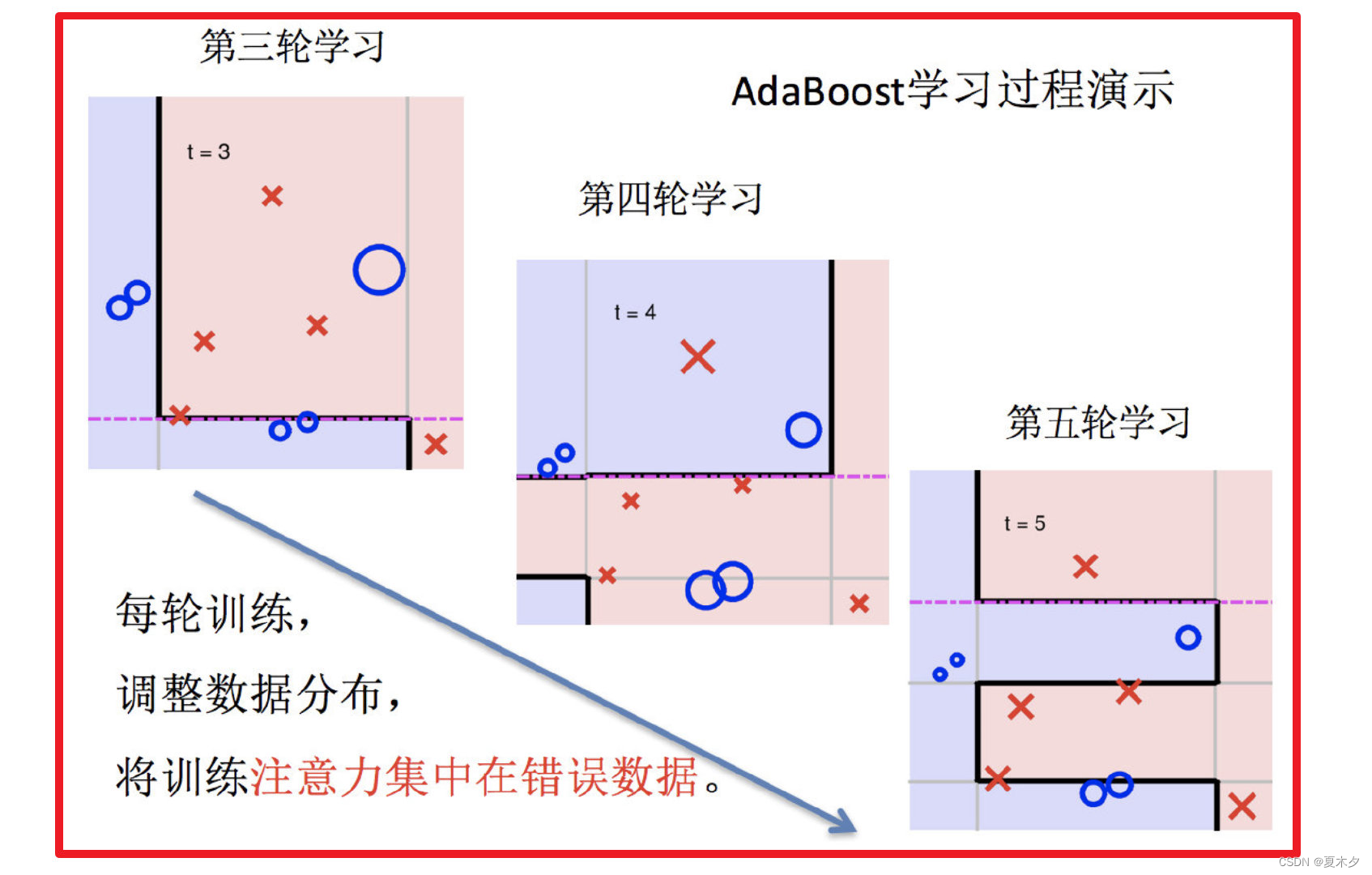
3.2 与 Bagging 的区别
区别一:数据方面
- Bagging:对数据进行采样训练;
- Boosting:根据前一轮学习结果调整数据的重要性。
区别二:投票方面
- Bagging:所有学习器平权投票;
- Boosting:对学习器进行加权投票(正确率高的话给的权重更大)
区别三:学习顺序
- Bagging的学习是并行的,每个学习器没有依赖关系;
- Boosting学习是串行,学习有先后顺序。
区别四:主要作用
- Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差)
- Boosting主要用于提高训练精度 (解决欠拟合,也可以说降低偏差)
3.3 AdaBoost
from sklearn.ensemble import AdaBoostClassifier
3.4 GBDT
GBDT 的全称是 Gradient Boosting Decision Tree,梯度提升树,在传统机器学习算法中,GBDT算的上TOP3的算法。
首先,GBDT使用的决策树是CART回归树,无论是处理回归问题还是二分类以及多分类,GBDT使用的决策树通通都是都是CART回归树。
为什么不用CART分类树呢?
因为GBDT每次迭代要拟合的是梯度值,是连续值所以要用回归树。















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









