







**flink run源码走向流程,参数传递
**因为一些原因开始研究天池大赛,比赛运行的是./runBenchmark.sh query1.sql 1 SF=1。根据这个开始。运行这个脚本,他是从flink分支中的CliFrontend的main方法中开始运行的。

**第一行是EnvironmentInformation.logEnvironmentInfo(LOG, "Command Line Client", args);这个方法首先确认log是否能写入,然后在rev中存储了flink code review的日期,version中存储了版本(1.9-tpcds-master),jvmversion中存储了jvm的version,options中存储了jvm需要的环境和系统参数,javaHome是jdk的具体位置。maxHeapMegabytes是jvm最大堆内存,输出这些参数的日志后,判断是否用到hadoop,并输出相应日志。
**然后是configurationDirectory的具体内容。final String configurationDirectory = getConfigurationDirectoryFromEnv();configurationDirectory中存储了config文件的具体位置。
** final Configuration configuration = GlobalConfiguration.loadConfiguration(configurationDirectory);先把configurationDirectory存成file类,再找出flink-conf.yaml把一下几个配置导入configuration中,并且把plugin相关一起导入。

**然后是customCommandLines,其中存入了三样东西。

**cli是用于执行程序的简单命令行前端的实例化。主要存了以上说的几个参数,和并行度。

**然后install安装流程范围的安全配置,log输出安装成功失败原因。
**Parseparameters提取出args的第一个参数,根据不同参数运行不同方法,这里运行的是run方法。并且传入其他的args参数。
**run方法中,commandOptions中存放了run之后能跟的一些参数,commandLineOptions中新增了更多的参数列表。commandLine中存储了customCommandLines的参数。

**runoptions主要存入了以下参数:

**然后是buildprogram,program中存储了整个项目中的一些参数。

**运行runprogram,检索现有的Flink群集。保存在client中,

**然后是executeprogram,client.run,libraries中存了jar包和具体位置。第二个就是libraries的内容。
**然后就是调用了主线程,main方法转到了flink-community那里。是queryBenchmark的main方法。Parser中存了剩下的args,然后用params数组装好,执行run方法。
**run方法中,先检查并打印出剩下的所有的args,并且把要执行的query文件识别存在queries中。然后创建tEnv环境,Environmentsetting保存了要使用的planner executor 内置的目录和数据库名称 和stream和batch的布尔值 。
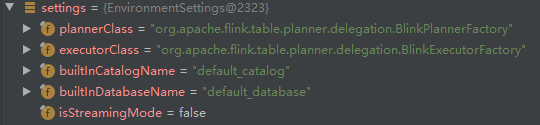
**根据这个setting创建tableenvironment。执行create方法。首先创建一个catalogmanager。并且把defaultcatalog和defaultdatabase存进去。然后创建一个functioncatalog,存着catalog manager和user function。然后是executor。

**然后把这些全部存在planner中

**setuptables方法中,sqltype(tpcds),sourcetype(CSV),datalocation,tablenames,schema(table列名),builder。根据builder registertable
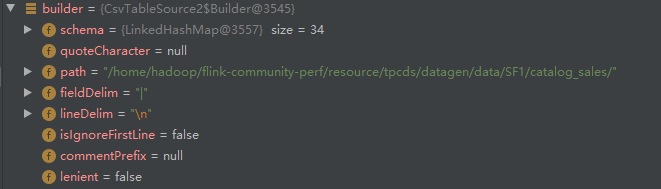
**Registertable调用registertableinternal,传入tablename和刚刚builder出来的tablesource。接下来过程大致和我之前写的register&createtable方法流程一致。他没有内置的catalog和database,要通过registertableinternal方法注册table
** fieldName2DataTypes存储了table中列的具体内容,当analyzetable为true的时候,其
中还会遇到sqlquery,也是之前讲过的
**然后是tablestats,调用StatisticGenerator.generateTableStats方法,首先getplanner得planner

**然后是tableName表名称,sourcetable,schema,allfieldname,selectedField,quoting,


**然后进入getColumnStatsSelects方法,columnStatsSelects中保存了列名和类型名和具体数据,statsSql就是flink图表中的那么一串话,
**然后table=sqlQuery ,result中存储数据,createtable,collectsink并registertablesink,然后就execute,进入translate方法转换成合适的类型,(耗时非常长)然后又是execute,
**然后就回到了QueryBenchmark中,tablestatsmap中存了整张表中所有的数据

**然后打印出整张表的一些数据,并且把table数据和table的列数据写进catalog中。如此循环写入所有的表。
**然后根据写入的sql表名,runquery,在benchmark中存储sql文件名和具体内容,执行run方法→runinternal→sqlquery→collect→collectsink→collectConfiguredSink→registerTableSink→execute→execute。Res中存放了100条查询数据,并输出。
















 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









