







8、在Eclipse中当前目录指的是项目目录而不是包目录(java文件所在的目录就是包目录)。
9、从一个地方复制文件到另一个地方。
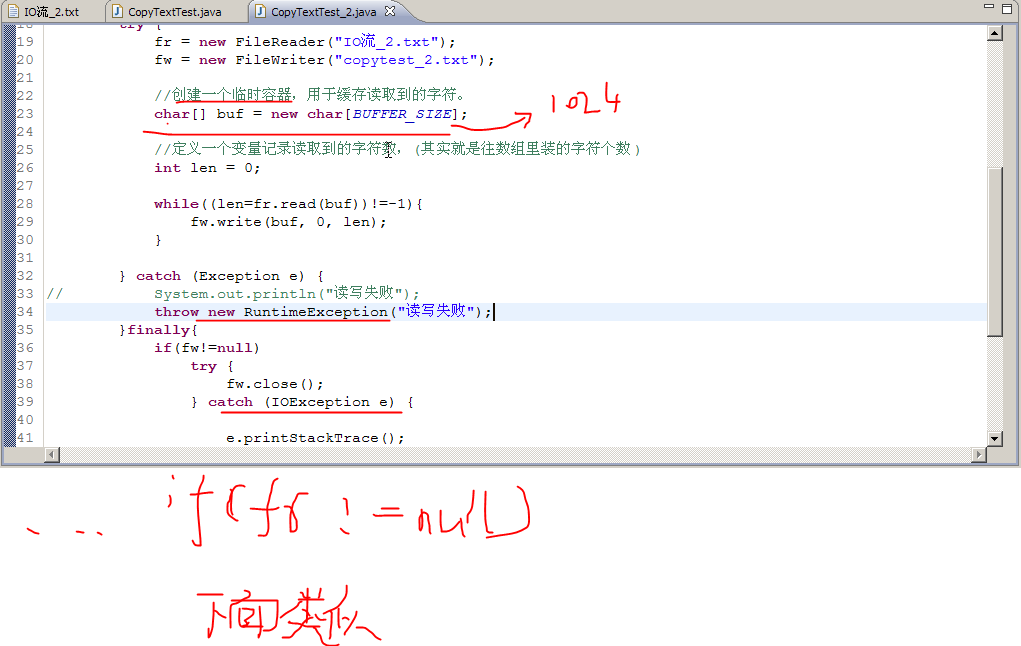
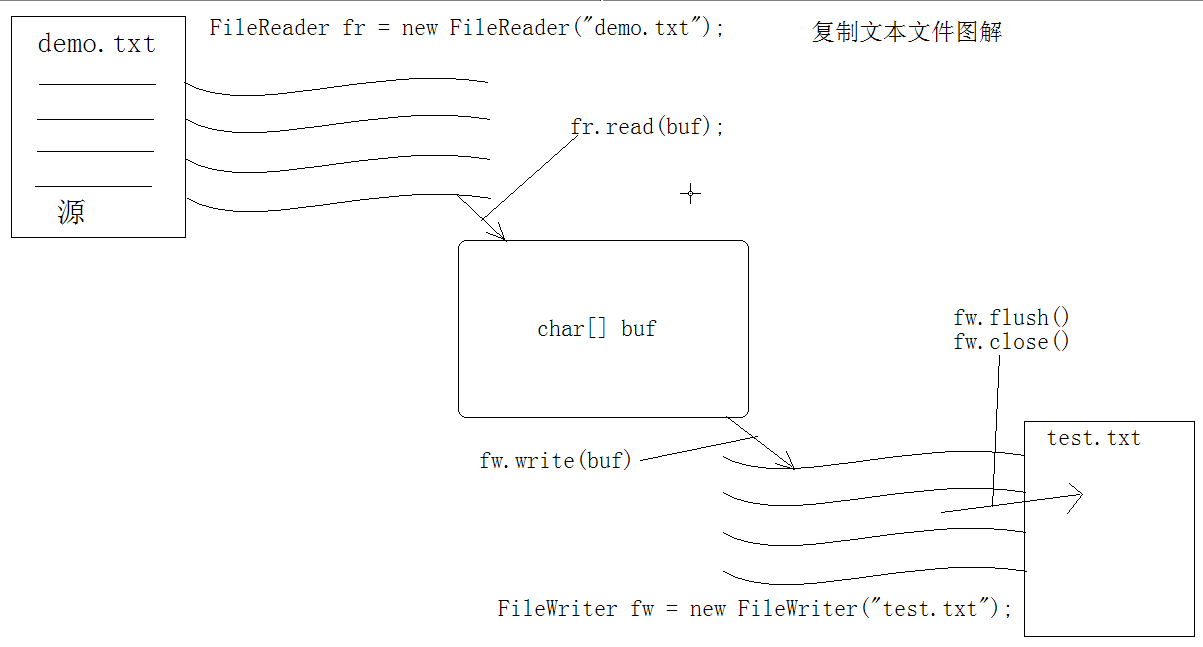
复制过程图解示意图:那个输入输出流就可以理解为输入输出管子,fr.read(buf)是直接读到字符数组buf中了,但是fw.write(buf)并没有将内容直接写到目标文件中,而是先写到了输出流(输出管子的缓冲区),想要真正写入(相当于写入后要保存),还需要调用flush()方法或者close()方法。
10、我们创建的临时容器字符串数组ch其实也就是个数据缓冲区,但是这是我们自己new出来的,java自身其实也提供输入专用缓冲器对象,也提供输出专用缓冲器对象(实质就是封装了一个字符串数组作为缓冲器)。所以直接用java提供的输入输出缓冲器对象最好,因为对象还自带不少实用的方法。
缓冲区对象的好处在于:以前没有缓冲时,硬盘读写器从存储的地方读一个字符就切换到要写的地方,来来回回切换才能写完,效率低,有缓存器后,把数据连续写入缓存器,硬盘磁头在转换到要写的地方开始连续写,把全部内容都写完,一次切换就可以搞定,效率高。
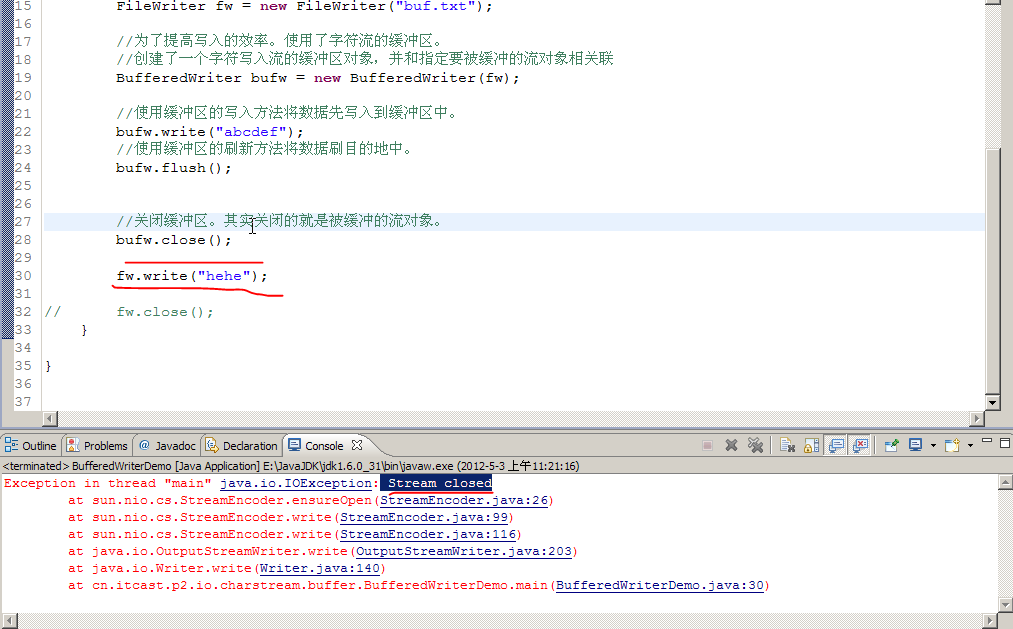
缓冲区仅仅是封装了数组来提高流的操作效率,缓冲区关闭其实就是流(输出管子)关闭
newLine()方法只在BuffWriter这种缓冲器对象才有换行作用,而定义Line_sapartor的方法适用范围更广。
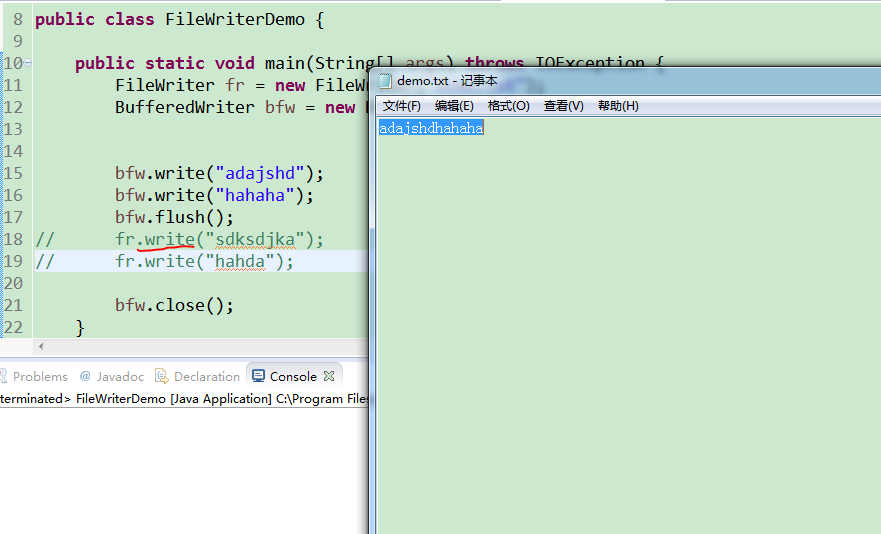
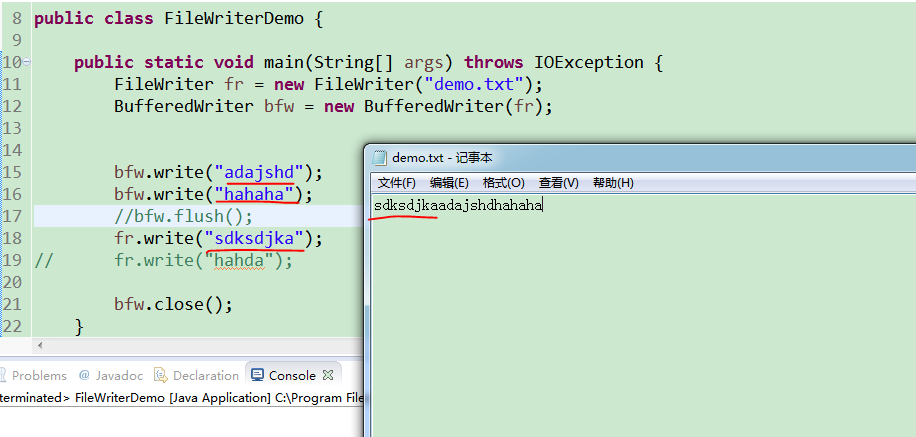
同时注意bfw.write()和fw.write()都可以写数据到指定文件,但是默认的fw.write()是直通文件的,所以优先级也高一点,看下图就明白。
每new出一个缓冲器Bufferedreader或者BufferedWriter都要记得和输入输出流(输入输出管子)FileWriter,FileReader相关联才行,也即缓冲区一定要有被缓冲的对象。
Bufferedreader特别的是提供行的读入,效率更高 ,具体有几行,是根据有几个回车符来判定的。readLine()方法。读一行返回的自然是字符串。我们之前是用字符数组读,或者一个一个字符读。readLine()每次调用读一行,再调用读下一行
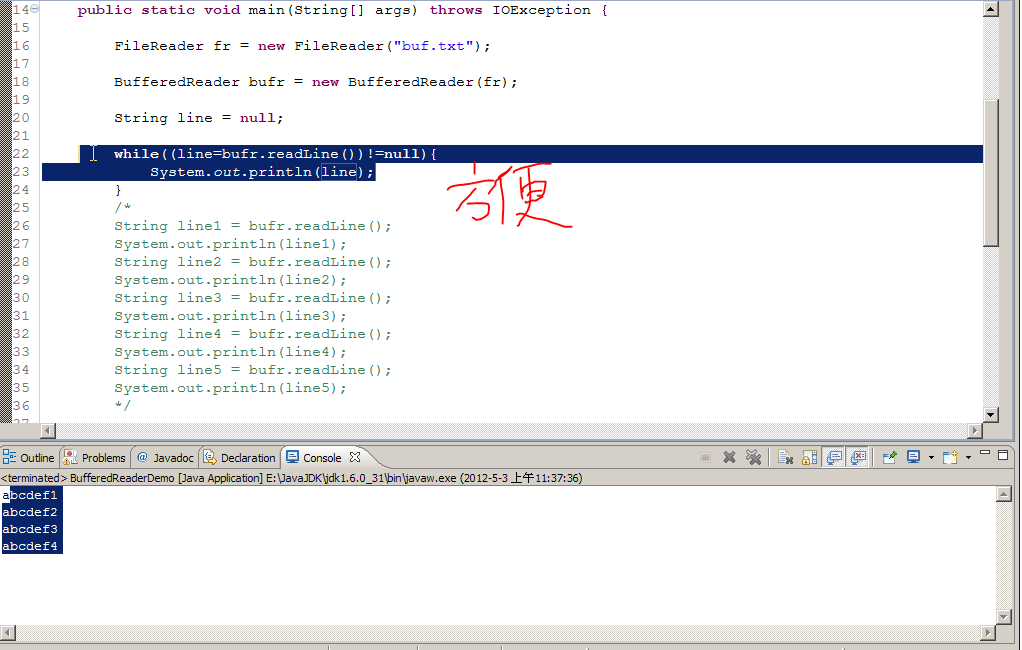
14、Bufferedreader里有特殊的方法readLine(),每次读一行的效果或者BufferedWriter里有一个newLine()产生换行符效果,值得注意,方便使用。
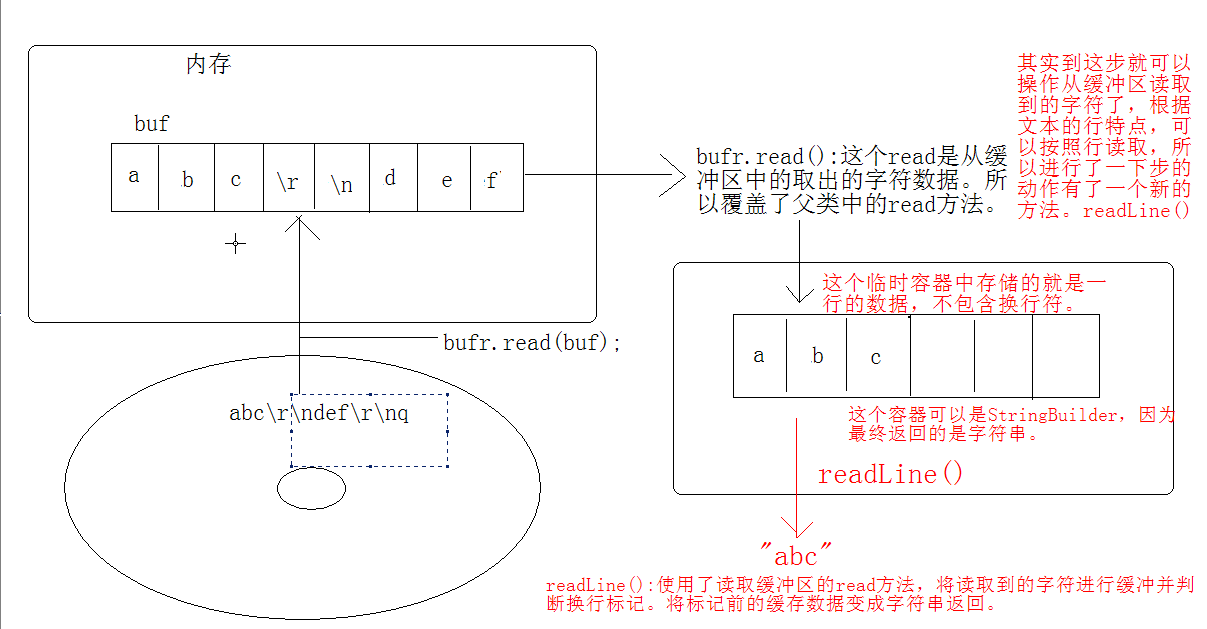
缓冲区操作的百分百都是缓冲区中的数据。流(输入输出管子)操作的都是硬盘上的数据。FileRead.read()是每次从硬盘读一个字符,而Bufferedreader.read()是把数据先装到缓冲区数组中,然后在缓冲区中读一个字符,因为缓冲区在内存,不用来回跑硬盘,所以效率更高。
Bufferedreader输出缓冲器对象一建立以后,关联了输入流(管子对准了要读的文件),就把要读的文件的数据从硬盘一个一个连续读入缓冲器内部的数组(效果看起来就是一读一把数据),之后如果调用Bufferedreader的read()方法,就可以从缓冲区里读出一个字符,速度高效,当缓冲器数组全部读完之后,又从硬盘抓了一组新的数据,继续供read()来读。readLine()的原理就是又临时生成一个容器,把缓冲区数组的数据读一行到容器中,供readLine()方法来读取。
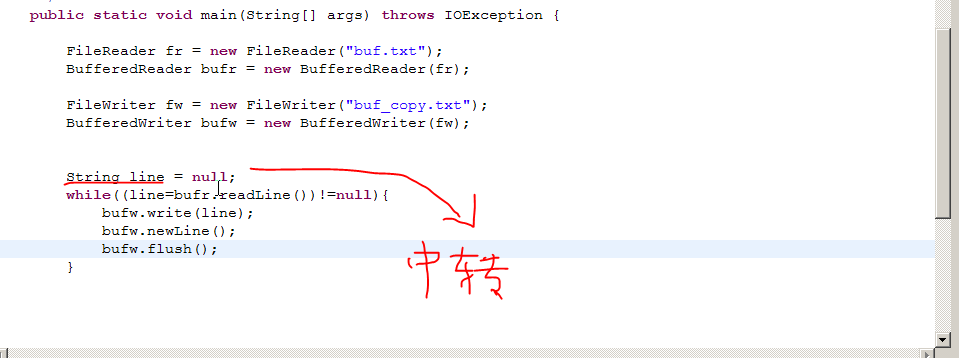
不管有没有用缓冲器,从一个文件读取数据,都需要经过一个中转变量来交接,在由输出流(输出管子)来把这个中转变量给写出去。
16、自定义一个MyBufferedRead类模拟实现BufferedReader的功能。
首先定义一个长度固定的数组buf,然后借助BufferedReader的父类FileWriter的read(buf)方法从硬盘上读取数组长度那么多的数据,MyBufferedRead类的read()方法就是从缓冲器中读到一个字符,也就是从buf数组中读到一个字符,并返回。
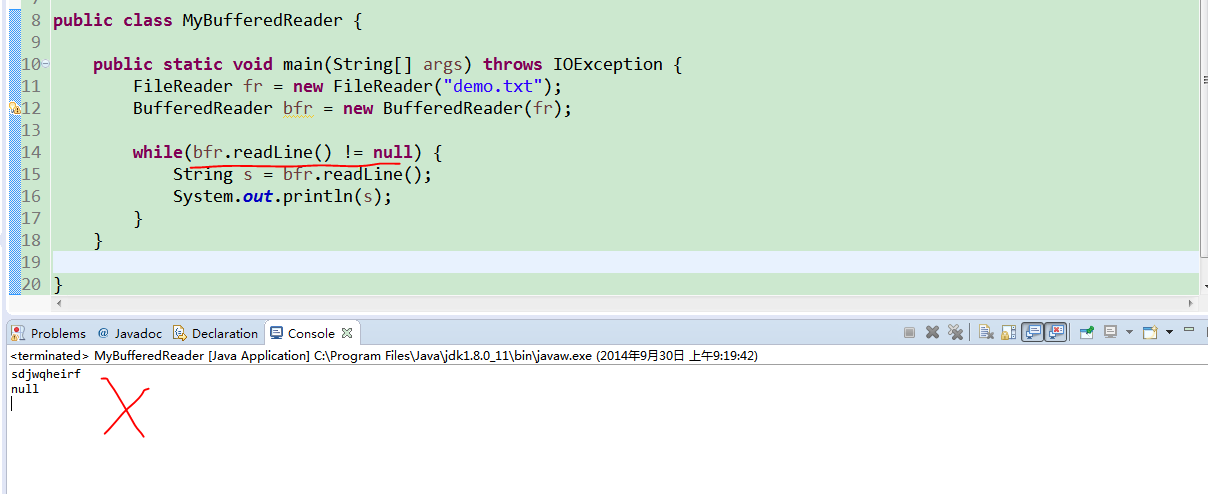
首先我们研究一下传统的BufferedReader,值得注意的是,bfr每调用一次readLine(),就自动向下移动了一行,所以要及时记着接收
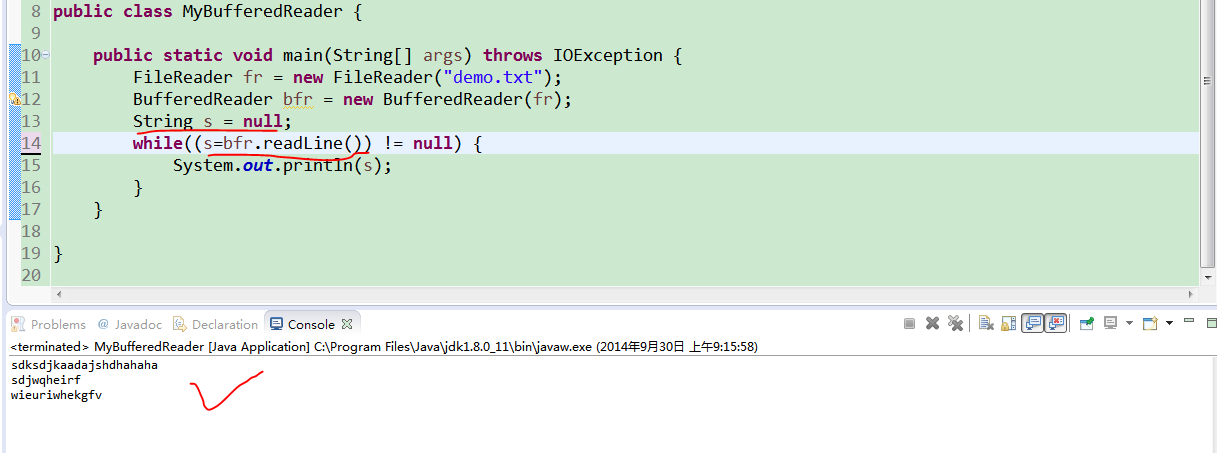
但是下面的图中就忽略了这个问题,因为在while()判断的时候,已经读了一行,但是没有接收的,所以就漏读了内容。同时注意上图中忘记写bfr.close();
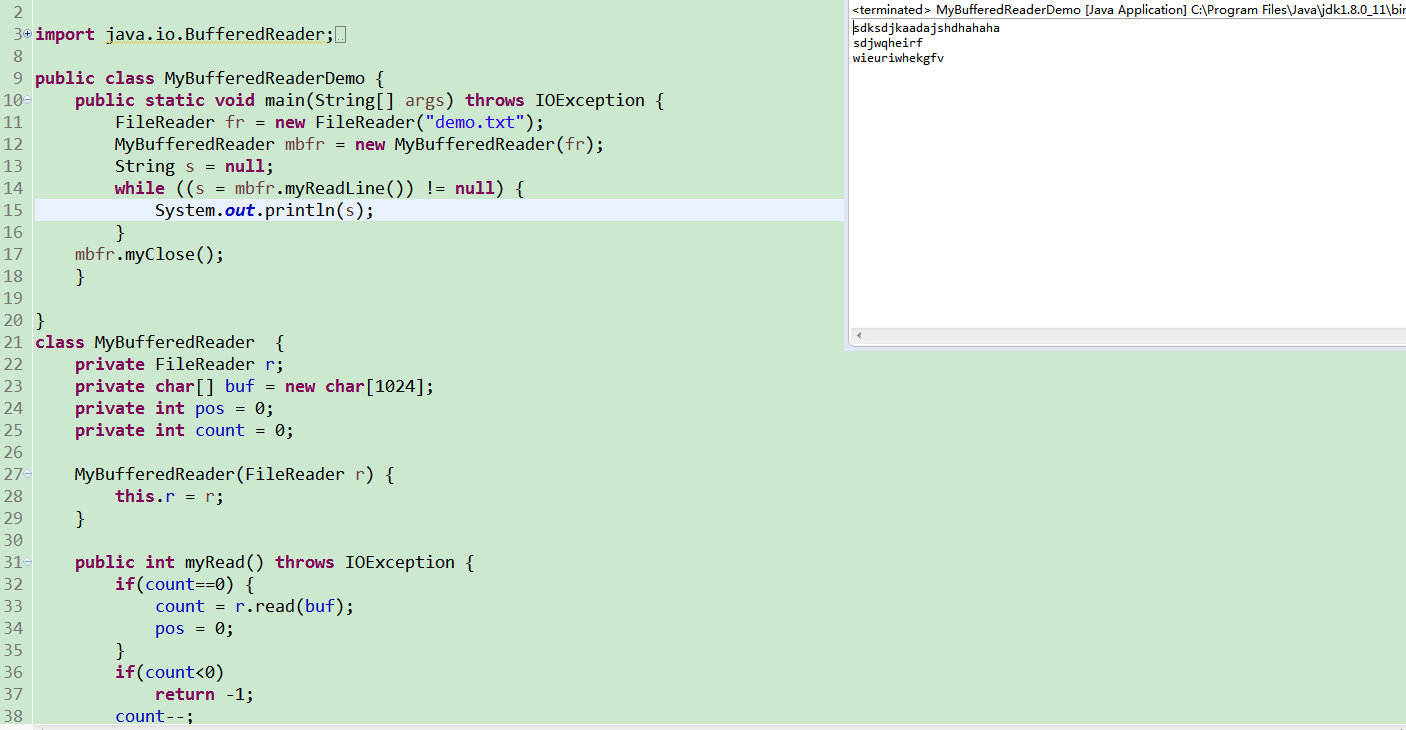
下面就自定义MyBufferedReader类实现BufferedReader的功能。其实MyBufferedReader要实现装饰功能的Reader类,所以还是要继承自Reader,把下面代码中的FileReader换成Reader,这样它就可以装饰(缓冲增强)所有的Reader的子类。

18、装饰设计模式
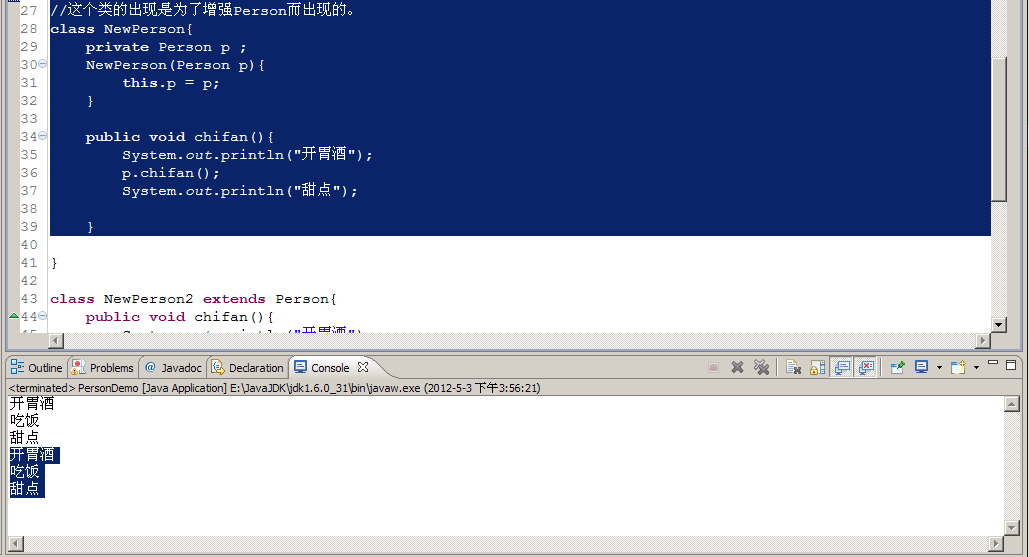
字符串缓冲BufferedReader其实就是Reader的增强型,本质用的还是Read类的方法,但是功能更加丰富好用,符合装饰(锦上添花)的意思。
有时继承和装饰可以起到相同的作用,但是两者还是有区别的。

20、LineNumberReader类是装饰类BufferedReader的子类,多了个提供行号的功能。
21、字符流只能处理文本文件,重点掌握FileReader,FileWriter,BufferedReader,BufferedWriter,而字节流可以处理更多类型的文件例如媒体文件MP3之类。
字节流的两个爹InputStream,OutputStream,两个子类FileOutputStream,FileOutputStream,FileInputStream.媒体数据file
字节缓冲区数组为byte[]类型,字节流写的是字节源码,不需要flush,不需要close就能写进去,但是close动作还是要有的,用缓冲形式的字节类时还是要flush的 ,之前的字符还要解析下所以flush
注意一个问题,调用Read(数组)时,读到的数据装在数组中,同时还有长度,因为数据快读完的时候,没有装满bye[]数组的长度,所以要按实际装入的数据长度len来确定。要联想当时的图来记忆。
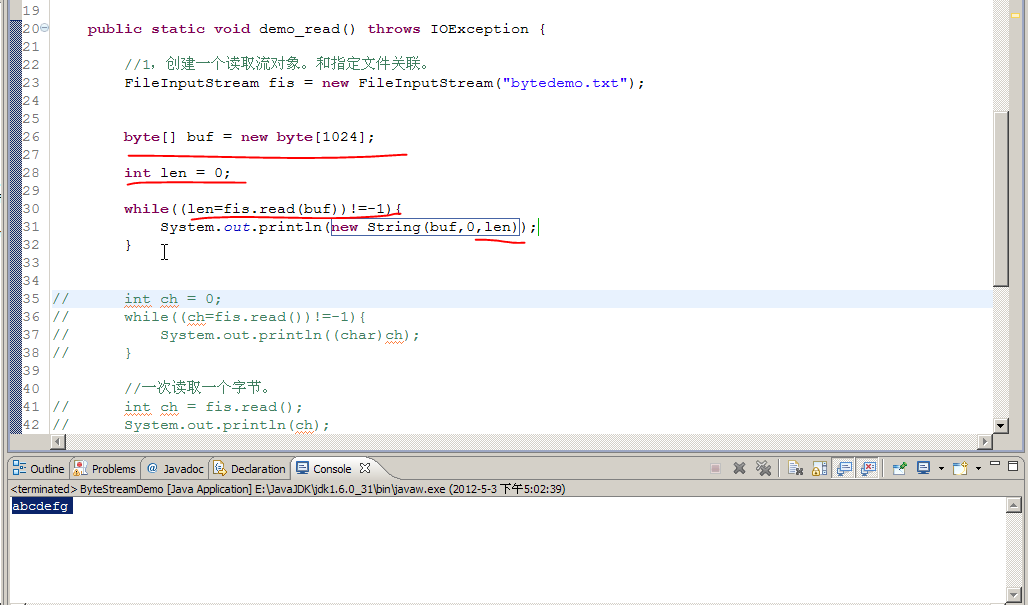
注意最后一句输出时syso(new String(b,0,len));
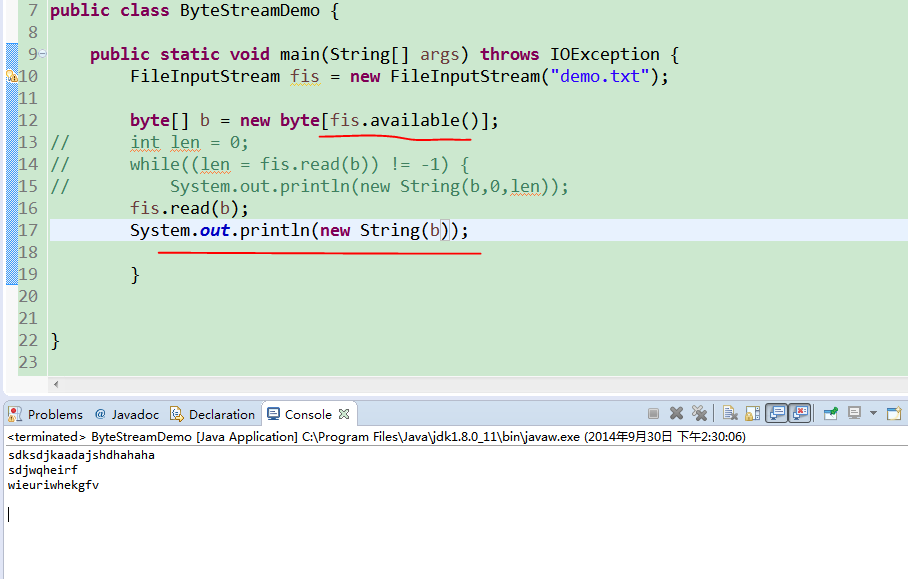
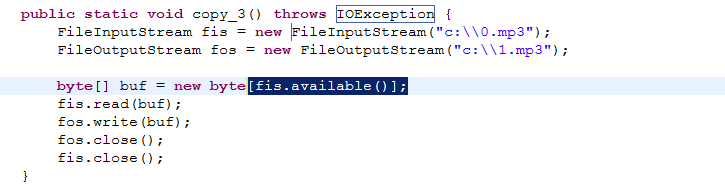
available()方法读取文件的大小,得到的就是文件内容有多少个字节,就开辟多大的数组,这样一次性就能读完,直接就可以打印出来(注意换行符也算一个字节),但是不建议用这种方法,因为遇见文件比较大时,内存容易溢出。
22、重新认识一下BufferedReader和FileReader的区别,FileReader的read()方法是从硬盘上一次读出一个字符,而FileReader的read(数组)是从硬盘上一次读出数组长度那么多的数据(当然也是一个一个读进去的,而BufferedRead是一开始就先读取一定的数据到缓冲区数组中,之后不管是read()方法还是readLine()方法都是操作缓冲器的数据,而不是操作硬盘上的数据,区别就是在这里。
下面给出4中常用复制方法:
方法1:直接用不带缓冲的字节流在硬盘上操作数据,定义了一个byte数组,方便操作。

方法2:借助缓冲输入输出类,可以中间用数组来做缓存中转,也可以单个字节来做中转。
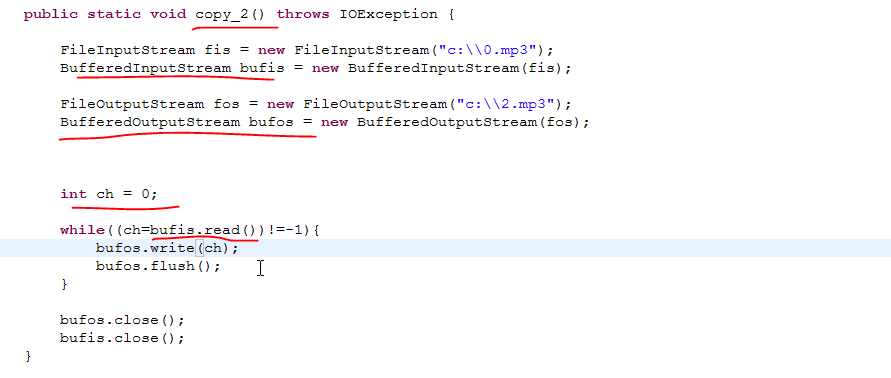
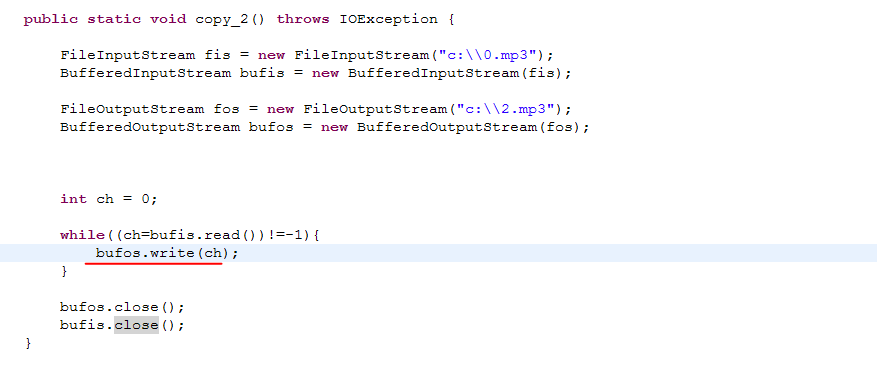
while()循环里不加刷新flush,最后一次性刷新,效率会高点。
方法3:借用fis所特有的available()直接声明一个特定长度的数组,一次性搞定。文件大时,不建议这种方法,太占内存。
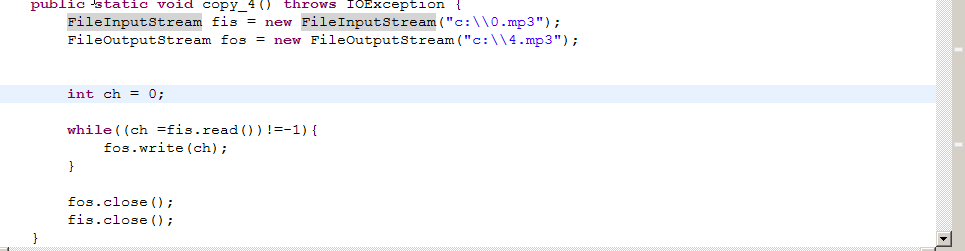
方法4:效率最低















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









