










 挑战传统的Transformer模型设计
挑战传统的Transformer模型设计
在深度学习和自然语言处理领域,Transformer模型已经成为一种标准的架构,广泛应用于各种任务中。传统的Transformer模型依赖于一个固定的、按深度排序的层次结构,每一层的输出都作为下一层的输入。这种设计虽然简单有效,但也存在参数冗余和计算效率低下的问题。
最近,一项新的研究提出了一种名为“Mixture-of-Modules”(MoM)的新架构,旨在打破这种固定层次的传统,通过动态组装不同的模块来计算每个token,从而提高模型的灵活性和计算效率。这种设计允许模型在不同层之间自由地“移动”计算,而不是严格遵循从浅层到深层的顺序。MoM通过引入两个路由器动态选择不同的注意力模块和前馈网络模块,组合成一个完整的计算图,实现了对传统Transformer的一种创新性改进。
这项研究不仅挑战了Transformer的传统设计,还展示了在保持相当性能的同时,如何显著减少计算资源的消耗。通过这种新的架构设计,MoM在多个基准测试中展示了其优越性,包括GLUE和XSUM,证明了其在处理深度和参数数量上的灵活性。
先看结论
1. 主要优势
MoM架构的主要优势包括:
- 提供了一个统一的框架,将多种Transformer变体(如混合专家、提前退出和混合深度等)纳入其中,为未来的架构设计提供了新的思路。
- 在前向计算中引入了前所未有的灵活性,使得“深度”和“参数数量”不再像传统方式那样紧密耦合,用户可以通过扩大模块池或增加深度来构建更强大的架构。
- 通过合理配置模块和压缩模型深度,实现了与传统Transformer相当的性能,同时显著降低了计算资源的消耗。
2. 实验结果
通过在不同的参数规模上预训练MoM模型,并在GLUE和XSUM基准测试中进行评估,实验结果显示:
- 在所有参数规模上,MoM模型一致地超越了传统的GPT-2模型。
- MoM架构能够在保持性能的同时,显著减少计算资源的消耗,特别是在大规模模型上,资源节约更为显著。
论文标题: MIXTURE-OF-MODULES: REINVENTING TRANSFORMERS AS DYNAMIC ASSEMBLIES OF MODULES
机构: Peking University, Renmin University, Tsinghua University, Ant Group
论文链接: https://arxiv.org/pdf/2407.06677.pdf。
MoM架构概述
Mixture-of-Modules (MoM) 是一种新颖的架构,旨在打破传统的 Transformer 模型中深度有序的层次结构。MoM的核心思想是将神经网络定义为由传统 Transformer 派生的模块的动态组装。这些模块包括多头注意力(MHA)、前馈网络(FFN)和特殊的“SKIP”模块,每个模块都具有独特的参数化。
在 MoM 中,每个令牌的计算图是通过两个路由器动态选择注意力模块和前馈模块并在前向传递中组装这些模块来形成的。这种机制不仅提供了一个统一的框架,将各种 Transformer 变体纳入其中,还引入了一种灵活且可学习的方法来减少 Transformer 参数化中的冗余。
MoM的设计允许在不同的层之间自由地移动令牌的计算,这一点与传统的从浅层到深层的顺序不同。这种设计使得深度和参数数量不再像传统架构中那样紧密耦合,从而为构建更强大的架构提供了更大的灵活性。
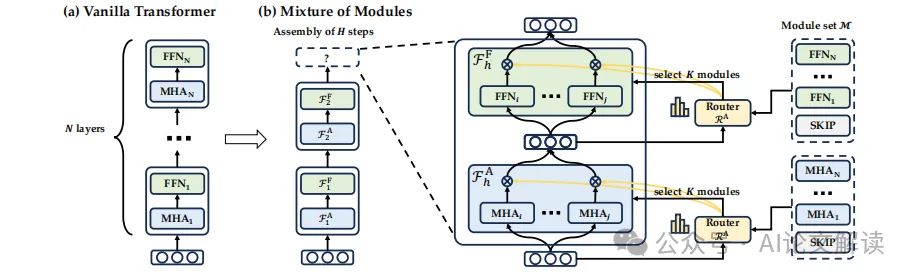
模块动态组装机制
在 MoM 中,模块的动态组装是通过一个迭代过程实现的,每个令牌在每一步都可能被分配到不同的模块。这一过程由两个专门的路由器控制,分别用于选择 MHA 和 FFN 模块。每个路由器输出一个分布,指示每个模块被选中的权重。
在每一步中,根据路由器的输出,选择权重最大的 K 个模块进行组装。这些模块通过一个组装函数联合起来,形成该步骤的输出。这个过程不仅仅是简单的层叠,而是一个根据令牌的需求动态调整的过程,使得每个令牌都可以在最适合它的模块中被处理。
此外,MoM 采用了一种两阶段训练方法来优化这一动态组装过程。首先,在大规模语料库上预训练一个标准的 Transformer,然后将其分解为模块,并用这些模块初始化 MoM,同时随机初始化路由器。在第二阶段,继续在相同的数据和目标上训练模块和路由器,以此来加速模型的收敛并提高参数的利用率。
通过这种动态组装机制,MoM 能够在保持与传统 Transformer 相当的性能的同时,显著减少前向计算中的 FLOPs 和内存使用。
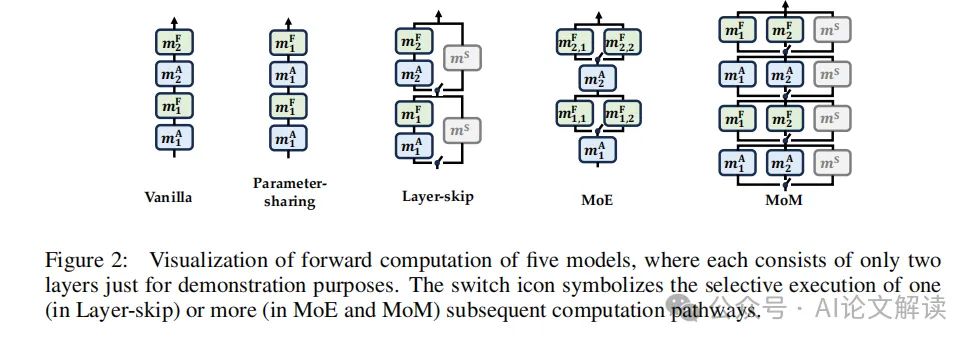
训练策略与实验设置
1. 实验模型与配置
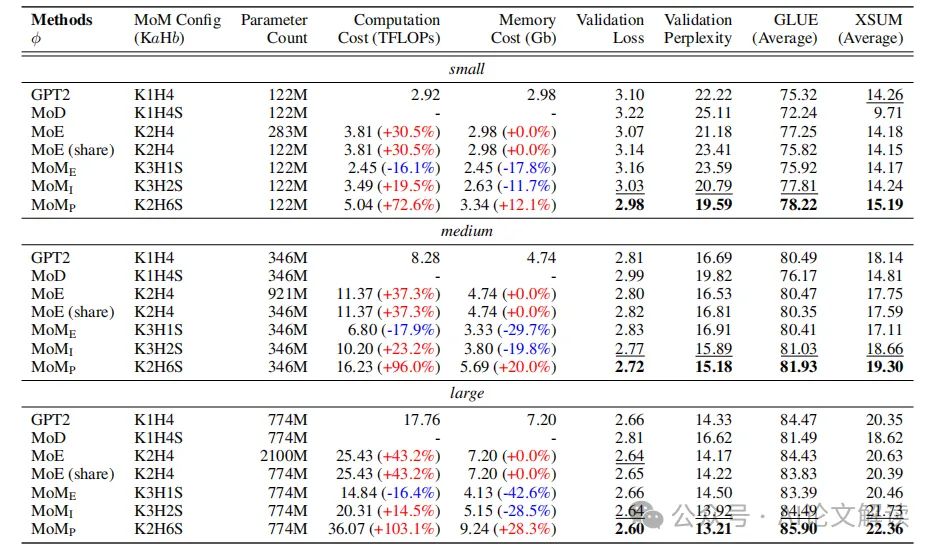
实验中,我们采用了三种不同规模的MoM模型:MoM-small、MoM-medium和MoM-large,分别包含122M、346M和774M参数。在训练过程中,我们使用了官方的GPT-2模型作为MoM的初始化基础,这些模型从HuggingFace平台下载。
2. 训练数据与预处理
我们使用OpenWebText作为预训练数据集,该数据集经过标记后包含约9亿个token。从中随机抽取400万token作为验证集。所有模型的输入序列长度设置为1024。我们设置学习率为1e-3,并在两个训练阶段中均采用0.1的预热比例,不使用dropout。所有模型均在8×A100 GPU上训练,总批量大小为8×64。
3. 训练策略
我们采用了两阶段训练策略。在第一阶段,我们在大规模语料库上预训练一个标准的Transformer模型,以此来初始化MoM的模块集合。第二阶段,我们从头开始初始化路由器,继续使用相同的数据和目标训练模块和路由器。这种方法不仅增强了模块功能的专业化,还加速了模型的收敛。
实验结果与分析
1. 主要结果
实验结果表明,MoM在保持参数数量不变的情况下,通过更深的计算图(H)在GLUE和XSUM基准测试中一致地超越了所有基线模型。MoM的增强性能验证了我们的初衷:传统的深度有序层组织是次优的,可以通过动态模块组织和改进参数利用率来实现改进。
MoM的不同实例在资源成本上也显示出显著差异。例如,MoME-medium和MoME-large在资源成本上的减少比MoME-small更为显著。这些观察结果进一步强化了我们之前的动机:Transformer的过度参数化在模型规模增大时变得更加明显。
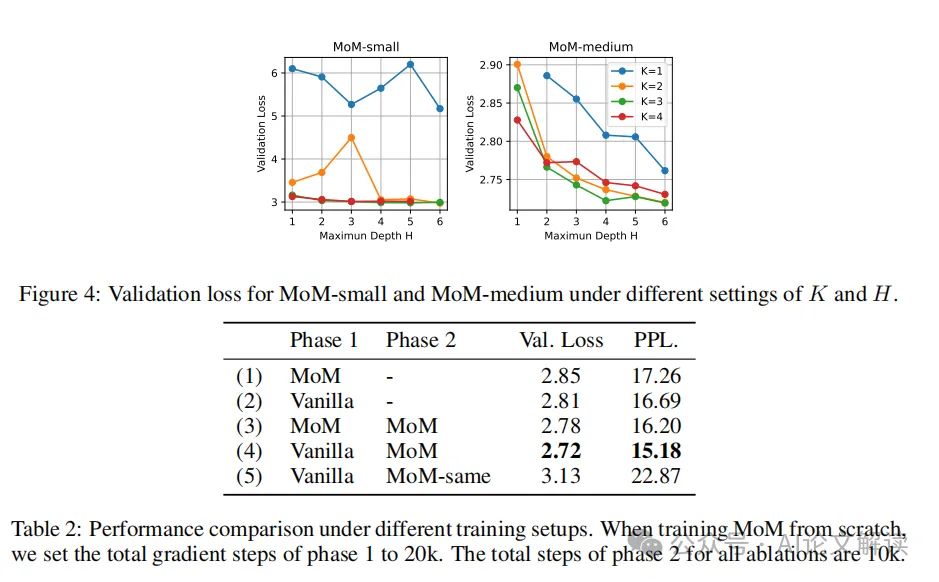
2. 训练策略的影响
我们研究了两阶段训练策略对模型性能的影响。结果显示,与从头开始训练MoM相比,使用预训练的Transformer模型初始化模块权重的两阶段策略具有更好的性能。这一发现强调了使用良好训练的Transformer模型为MoM初始化模块权重的重要性。
此外,我们还观察到,当减少MHA模块的数量时,损失的显著增加并不会立即出现,这表明Transformer中的MHA模块存在相当的冗余。相比之下,当逐渐减少FFN模块的数量时,每次移除一个FFN都会导致明显的损失增加,表明FFN模块的参数化较少冗余。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











