







一、一句话了解算法
【分类】:从训练样本中找出最近的K个值的类别来代表待预测值的类别;
【预测】:从训练样板中找出最近的K个值的平均值来表示待预测的值;
网络说法:
它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。
二、KNN算法详解
k-NN (k-nearest neighbor) 由 Cover 和 Hart 于 1968 年提出,属于机器学习算法中的监督学习算法,可以用来解决分类和回归问题。
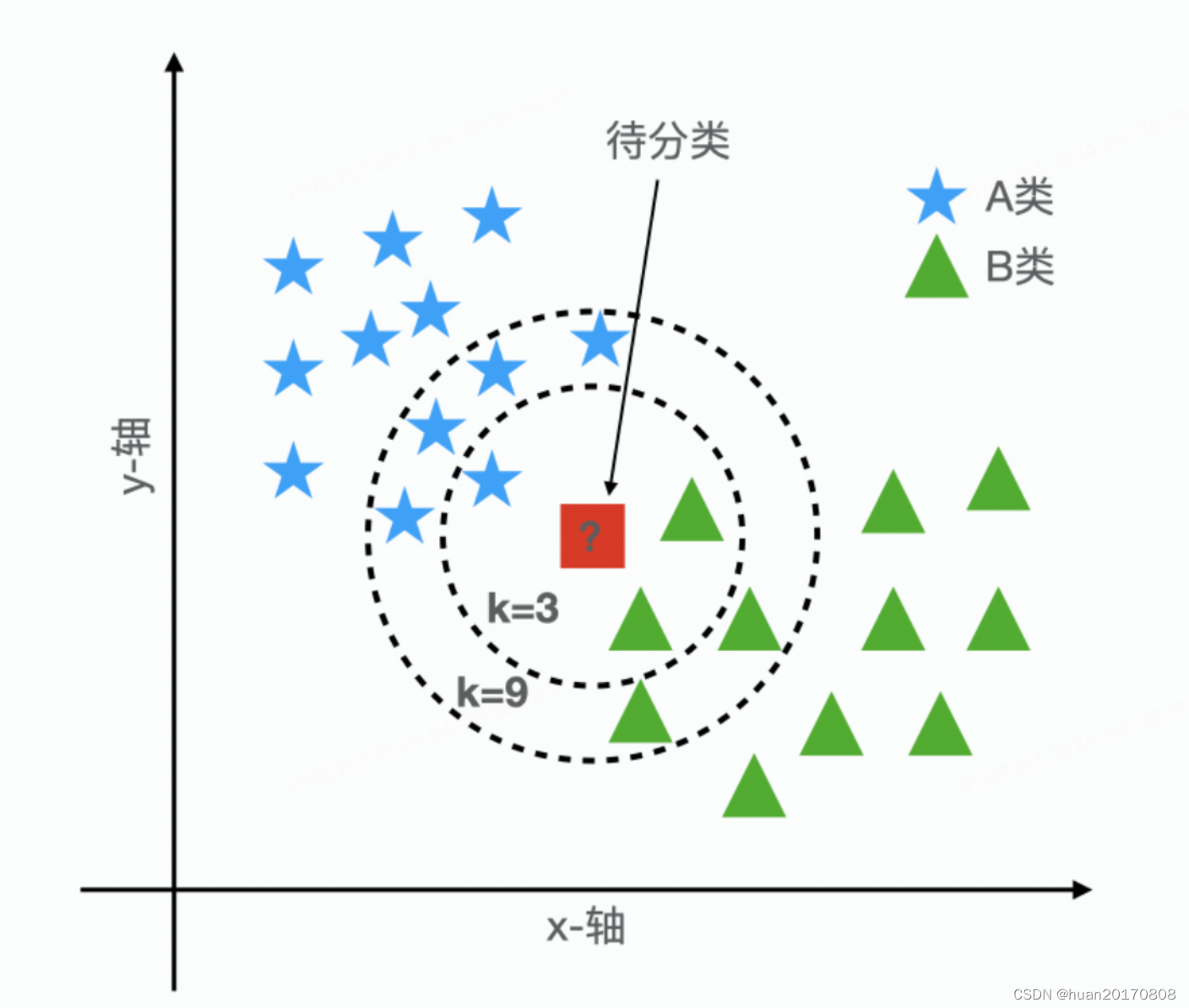
有两类物体 A 和 B,它们在坐标轴中的分布如上图所示。现在来了一个未知类别的物体,由图中的正方形表示,我们该把它归为哪一类呢?k-NN 算法的工作原理是看离待分类物体最近的 k 个物体的类别,这 k 个物体的大多数属于那个类别,待分类物体也就属于那个类别。例如:当 k = 3 时,离待分类物体最近的 3 个物体中,有 1 个 A 类物体,2 个 B 类物体,所以待分类物体属于 B 类;当 k = 9 时,离待分类物体最近的 9 个物体中,有 5 个 A 类物体,4 个 B 类物体,所以待分类物体属于 A 类。
1)具体实现步骤:
- 计算待分类物体和其他物体之间的距离。
- 选取距离待分类物体最近的 k 个物体。
- 这 k 个物体的大多数属于那个分类,待分类物体也就属于那个分类。
2)距离公式:
- 欧几里得距离(Euclidean Distance):这是KNN算法中最常用的距离计算方法。它的计算公式是 d(x, y) = sqrt((x1 - y1)^2 + (x2 - y2)^2 + ... + (xn - yn)^2),其中x和y分别表示两个样本点的特征向量,x1、x2、...、xn和y1、y2、...、yn表示它们对应的特征值,sqrt表示平方根运算。欧几里得距离衡量的是两点之间的直线距离。
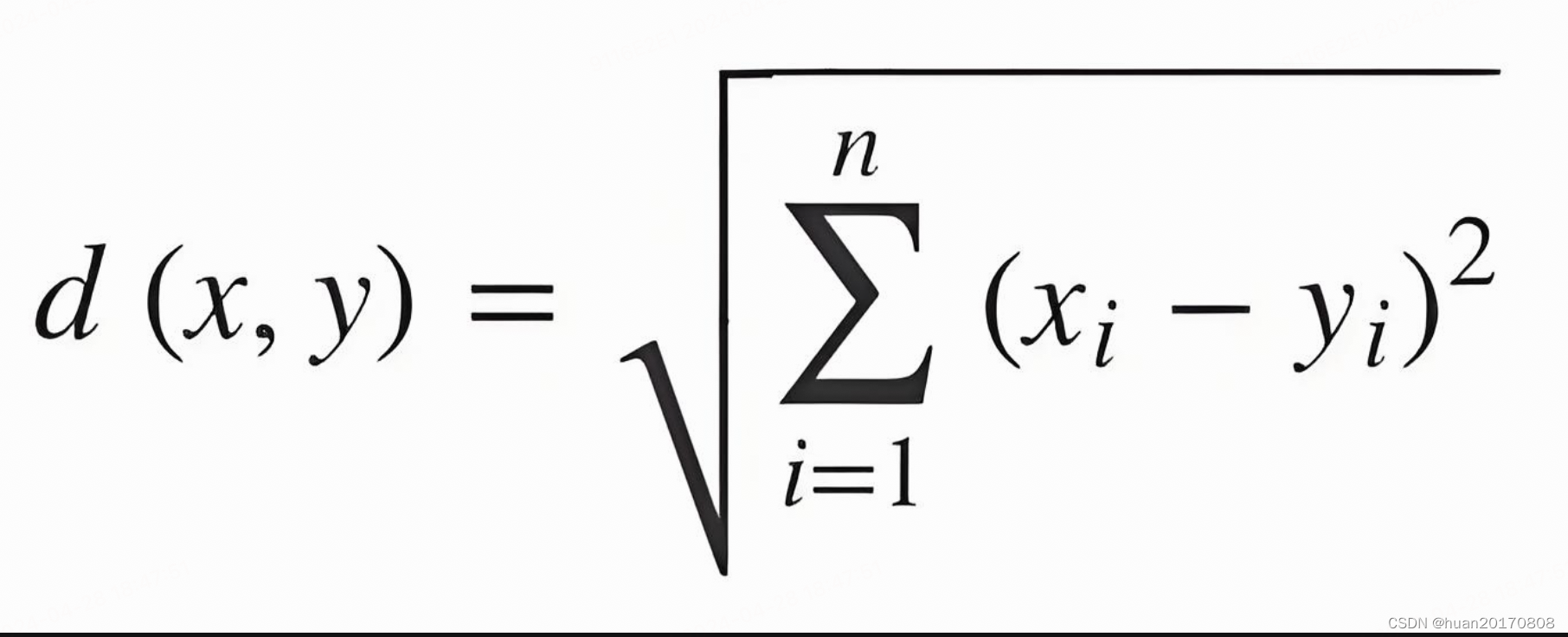
- 曼哈顿距离(Manhattan Distance):也称为L1距离或城市街区距离。它的计算公式是 d(x, y) = |x1 - y1| + |x2 - y2| + ... + |xn - yn|。曼哈顿距离计算的是两点在标准坐标系上的绝对轴距总和。
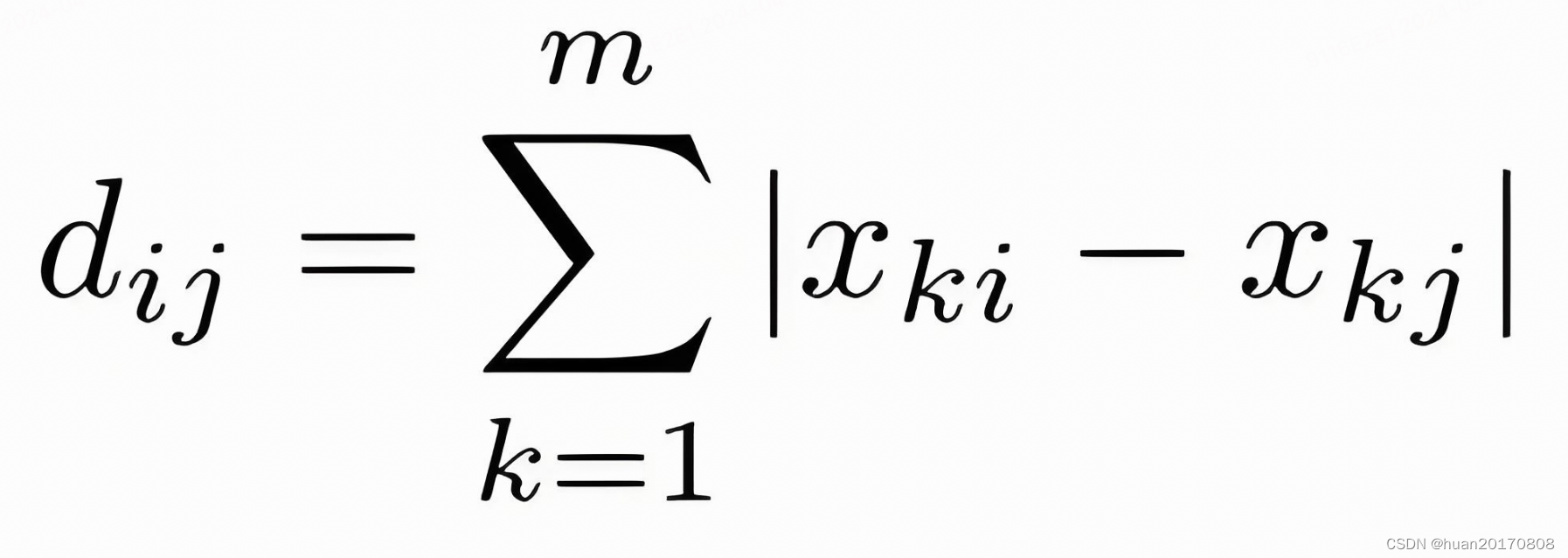
- 切比雪夫距离(Chebyshev Distance):也称为L∞距离或棋盘距离。它的计算公式是 d(x, y) = max(|x1 - y1|, |x2 - y2|, ..., |xn - yn|)。切比雪夫距离取的是坐标数值差的绝对值的最大值。

3)K值的重要性:
从上面的例子我们看到,k 值的选择会对结果产生重大的影响。同一个物体,如果 k 值选择的不同,结果可能完全不同。
k 值的选择也对模型的预测效果产生较大影响:
1)如果 k 值选择的较小,只有较小邻域内的训练实例才会对预测结果起作用,这时整体模型变得复杂,容易发生过拟合;
2)如果 k 值选择的较大,意味着距离输入实例较远的训练实例也会对预测结果起作用,这时整体模型变得简单,容易发生欠拟合。在应用中,一般采用交叉验证法来选取最优的 k 值。
KNN算法的优缺点:
KNN算法的主要优点有:
- 简单易懂,容易实现。
- 无需估计参数,无需训练。
- 适合对稀有事件进行分类。
然而,KNN也存在一些明显的缺点:
- 懒惰学习,没有显式的学习过程,每次分类都要扫描整个训练集。
- 计算量大,内存开销大,尤其是在样本容量大时。
- 必须指定K值,K值选择不当会影响分类结果。
- 对样本类别不平衡问题敏感。
三、KNN算法实现
引入相关的算法库
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_scoreimport numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42) #训练集占比为0.4
构建KNN分类器
knn = KNeighborsClassifier(n_neighbors=10) # 设置邻居数量为10
knn.fit(X_train, y_train) # 在训练集上训练模型
在测试集上进行预测
y_pred = knn.predict(X_test)
计算分类准确率
accuracy = accuracy_score(y_test, y_pred)
print("你的准确率为: {:.2%}".format(accuracy))
总结:
在实际应用中,KNN算法广泛应用于图像分类、文本分类、推荐系统、数据挖掘、生物信息学以及财务分析等领域。但需要注意的是,在使用KNN算法时,应根据具体的数据集和问题特性,选择合适的距离计算公式以及K值,以获得更好的分类效果。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









