






至于ssh密钥、jdk配置、hadoop配置网上的大体都是正确的,自行上网搜索,这里给出hadoop/etc下的文件配置,这个文件夹下面的配置文件,网上可谓是五花八门,相信你们一定遇到很多困扰——我试过其中一个提交文件的时候出错,又试了另外一个,于是恶性循环就出现了,一直报错
现给出我的配置,是最新的成功的配置:
对于hadoop的配置无非是以下几个文件配置
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>网上各种秀,加这加那,最后自己因为报错而慌乱,得不偿失
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=hadoop的classpath</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=hadoop的classpath</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=hadoop的classpath/value>
</property>什么是hadoop的classpath:直接运行
hadoop classpath将这个复制到上面配置文件hadoop的classpath的位置上
core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>这里第一个file:/usr/hadoop/tmp改成你存放hadoop的位置再在后面加tmp文件,即
hadoop路径/tmphdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>这里照葫芦画瓢就行
在hadoop-env.sh中添加jdk路径
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_301这里jdk环境配置中配置什么改成对应的就好
配置完上面的,再配置一下hosts,hosts在哪?
在/etc/hosts
在hosts中,一般没修改前是
127.0.0.1 localhost
127.0.1.1 ubuntu这里修改成
127.0.0.1 localhost
127.0.0.1 ubuntu在这个基础上,用ifconfig命令查看ip,在上面修改的下面添加
查询好的ip 主机名可以进行
hdfs namenode -format然后在hadoop目录下运行
sbin/start-all.sh用安装好的jps,查看是否所有node都在运行,运行成功是,下面的都有
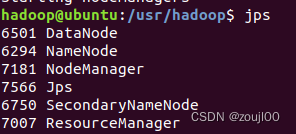
此时,一定要清理磁盘,hdfs节点需要的磁盘空间挺大的,否则等后续运行wordcount的时候,一定会卡在running,查看文档他会说节点因空间不够而不健康
完事具备,可以执行该使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令、下载dfs文件至本地)_hadoop jar命令_nana-li的博客-CSDN博客网站的代码了















 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









