









目录
一、前期准备
本文是我在自己电脑和帮助很多人安装后总结出来一个字一个字的打出来的,其中可能还会有(手残)打错的地方或者哪里(脑残)不正确的地方,还请指教一下,如果觉得不错的话也可以打个赏啥的。。
如果对Linux一点都不了解想要快速掌握一些基础命令的话可以看我之前的一篇,应该有帮助
https://blog.csdn.net/weixin_44495941/article/details/109523427
我是用的VMware安装的Ubuntu操作系统,也可以用virtual box等。用virtual box可以打开共享剪贴板(没见几个管用的),或者直接用fz通过sftp发送文件等(后面有教程)
开机前,建议分配内存2G左右,储存20G(不要用默认的10G,后面会空间不足,需要扩容)
本教程分享的时hadoop伪分布式的安装,也就是名称节点和数据节点都在一个上面配置。
如果按照我的配置,务必使用和我一样的文件
VMware-workstation-full-12.5.7-5813279
ubuntu-20.04.2.0-desktop-amd64
hadoop-3.1.3.tar
jdk-8u11-linux-x64.tar
eclipse-4.7.0-linux.gtk.x86_64.tar(如果这个不可以用的话用下面这个)
eclipse-inst-jre-linux64.tar
链接:https://pan.baidu.com/s/1qwljIjzG1jXsJ0Qcin_YHQ
提取码:1ud3
VMware-tools安装
这里建议直接在打开虚拟机之前通过勾选安装,必须在关机时才可以勾选。
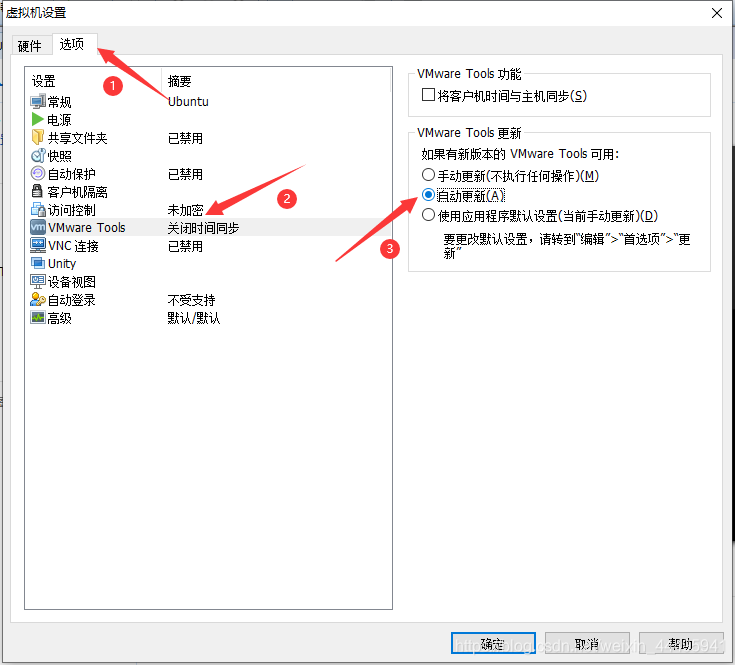
基本配置
提醒读者,一定要注意是在什么用户下敲的命令,我在里面都有详细解释,务必认真阅读,弄错一步都有可能不成功

cat /proc/version
hostname hadooproot配置
修改root密码(如果开始没有创建的话)
sudo passwd root
su
网络配置
ip ad正常情况下输出是这样的

/etc/init.d/network-manager restart2.可能是你的外面的路由器的问题,可以换成NAT模式


dhclient软件源配置
这里更正一下,当初看我教程的朋友们,我道个歉,我给的系统和这个系统并不对应,今天刚改过来 日期2021/3/9
另外,专门写了一篇关于更新源的文章,补充一下
https://blog.csdn.net/weixin_44495941/article/details/114608867
网络配置通后先更换一下软件仓库源为阿里的镜像源
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
vim 1.txt 如果没有vim可以先使用vi,命令一样进入后按i进入编辑模式后右键paste黏贴进入,再shift加两下z(两下大写z)保存退出
cat 1.txt >>/etc/apt/source.list最后使用update命令更新源文件
apt-get update -y
apt-get install vim -y安装ssh
apt-get install openssh-server -y
二、创建hadoop用户和文件
用户创建
useradd -m hadoop -s /bin/bash
passwd hadoop
usermod -a -G hadoop hadoop![]()
vim /etc/sudoers进入后按i进入编辑模式,找到root这里在下面添加一行
hadoop ALL=(ALL:ALL) ALL然后按一下ESC键,再按住shift不放按两下Z(大写的两个Z)保存并推出vim编辑器,Hadoop用户将会拥有sudo提权的权限

所有的下载的以及从主机上发过来的文件全部都放到/home/hadoop/downloads下
创建文件
mkdir /home/hadoop/downloads
小插曲
![]()

ps -aux |grep 19689
kill -9 19689再次查看进程

三、FTP配置
有人会有疑问,明明前面没有搭建ftp怎么会使用ftp呢。其实是使用的sftp的协议,就是ssh里面的,是linux自带的
下面使用filezilla连接
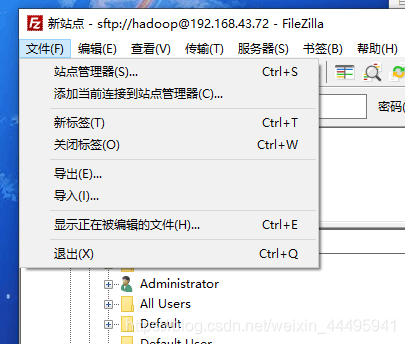
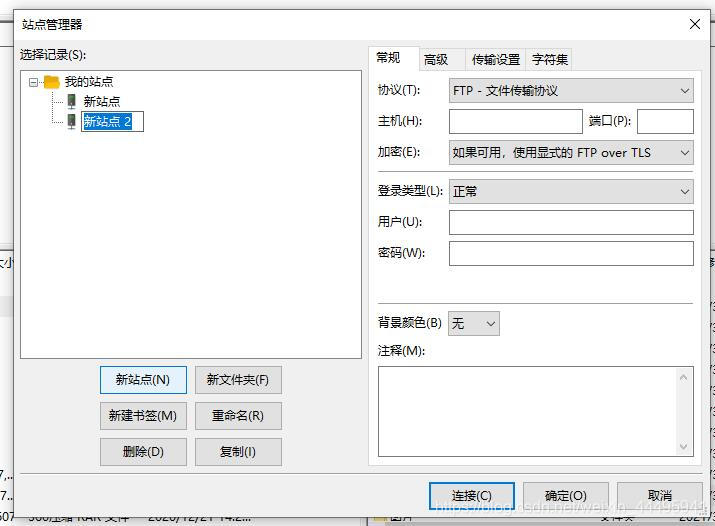
主要是需要选择这个sftp协议
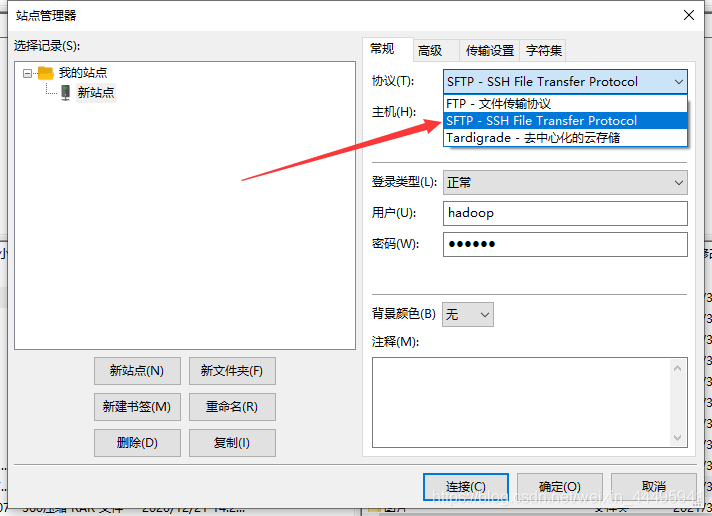
点击连接,出来弹框点击确定。
四、配置java环境及安装eclipse
安装eclipse

find /* -name eclipse*然后再使用mv命令移动到上面创建的hadoop下载文件夹中
mv /home/zxl/.cache/vmware/drag_and_drop/rrwsez/eclipse-4.7.0-linux.gtk.x86_64.tar.gz /home/hadoop/downloads/
tar -zxvf eclipse-4.7.0-linux.gtk.x86_64.tar.gz -C /usr/local/
cd /usr/local/eclipse/
./eclipse

安装java环境
java环境包依旧放到download下,解压到创建的/usr/lib/jvm下
mkdir /usr/lib/jvm
find /* -name jdk-8u1*
mv /home/zxl/.cache/vmware/drag_and_drop/rrwsez/jdk-8u11-linux-x64.tar.gz /home/hadoop/downloads/
cd /home/hadoop/downloads/
tar -zxvf /home/hadoop/downloads/jdk-8u11-linux-x64.tar.gz -C /usr/lib/jvm/
vim ~/.bashrc需要切换到Hadoop用户下面的可以如下教程
su hadoop
sudo vim ~/.bashrc
后面的教程相同
在开头输入如下,记得进去后先按下i进入编辑模式才可以黏贴
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_11
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH这里一定要和我输入的一模一样,而且使用我提供的软件包才可以,也可以使用自己的,只不过需要改一下版本号等等
输入后按两次大写的z保存退出

source ~/.bashrc
java -version 
Java环境配置篇结束
五、安装hadoop
find /* -name hadoop*
mv /home/zxl/.cache/vmware/drag_and_drop/rrwsez/hadoop-3.1.3.tar.gz /home/hadoop/downloads/
cd /home/hadoop/downloads/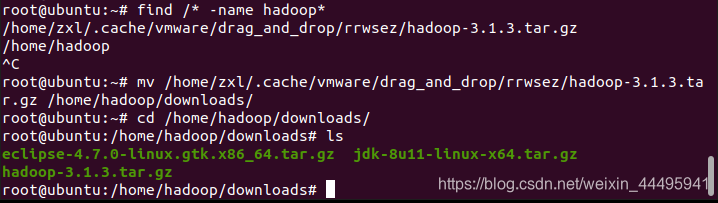
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local/![]()
mv /usr/local/hadoop-3.1.3 /usr/local/hadoop
chown -R hadoop /usr/local/hadoop
cd /usr/local/hadoop
./bin/hadoop version有如下提示则代表成功

六、伪分布式配置
修改配置文件
vim /usr/local/hadoop/etc/hadoop/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml添加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>
dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>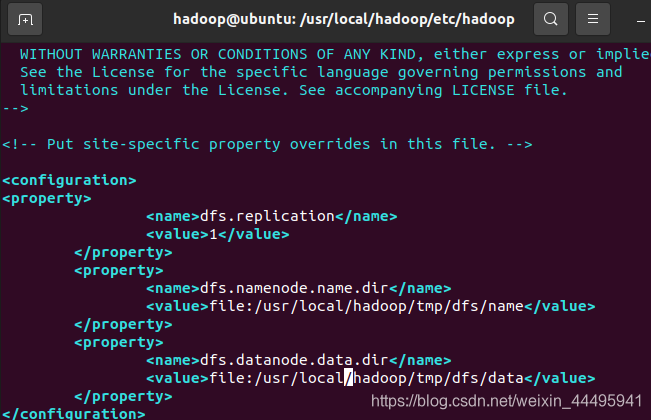
执行名称节点格式化
cd /usr/local/hadoop
./bin/hdfs namenode -format

启动测试
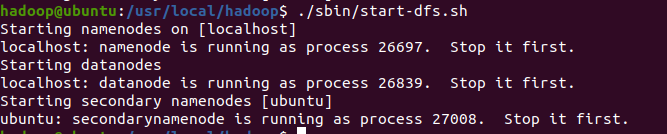
cd /usr/local/hadoop
./sbin/start-dfs.sh![]()

ssh免密登录设置
这个同样区分用户,准备用的那个用户启动hadoop就改那个用户的,本教程使用hadoop的用户启动,所有的环境变量等都需要配置这个用户,这样才可以成功!!!!
cd ~/.ssh/
ssh-keygen -t rsa //前面没有空格一直回车即可

cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys这之后的就不用配置了
scp ~/.ssh/id_rsa.pub xxx@host:/home/xxx/id_rsa.pub然后,将公钥导入到认证文件,这一步的操作在服务器上进行:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys最后在服务器上更改权限:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys(3)测试:ssh localhost 第一次需要输入yes和密码,之后就不需要了。
再次测试
成功!
七、常见错误
1.Ubuntu的老坑
启动Hadoop时拒绝连接
如果在启动hadoop的时候发现拒绝连接一类的中文或者英文字样先看一下你的名称节点启动的时候是在哪个主机名上面
就像我的是在localhost上面,有很多都是在自己创建的主机名上面启动,这个时候就应该看一下你的hosts文件在/etc/hosts下你的主机名是否对应的是127.0.1.1
如果是的话改成127.0.0.1
sudo vim /etc/hosts
#打开后例如这样
localhost 127.0.0.1
zxl 127.0.1.1
#第二行自己创建的主机名对应的是错误的本地地址,改正
localhost 127.0.0.1
zxl 127.0.1.1然后再次启动试一下基本就可以了。















 517
517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









