







 本文介绍了Dropout技术,一种在深度学习中用于缓解过拟合的策略。Dropout通过随机关闭部分神经元来降低网络复杂度,模拟集成学习的效果,从而避免过拟合。
本文介绍了Dropout技术,一种在深度学习中用于缓解过拟合的策略。Dropout通过随机关闭部分神经元来降低网络复杂度,模拟集成学习的效果,从而避免过拟合。
本文重点
在深度学习的广泛应用中,模型过拟合(Overfitting)是一个常见问题,尤其当训练数据有限而模型复杂度较高时更为显著。过拟合指的是模型在训练集上表现优异,但在未见过的测试集或实际应用中性能大幅下降的现象。为了缓解这一问题,研究者们提出了多种策略,其中Dropout技术以其简单而有效的特点,成为了深度学习领域中最受欢迎的过拟合解决方法之一。
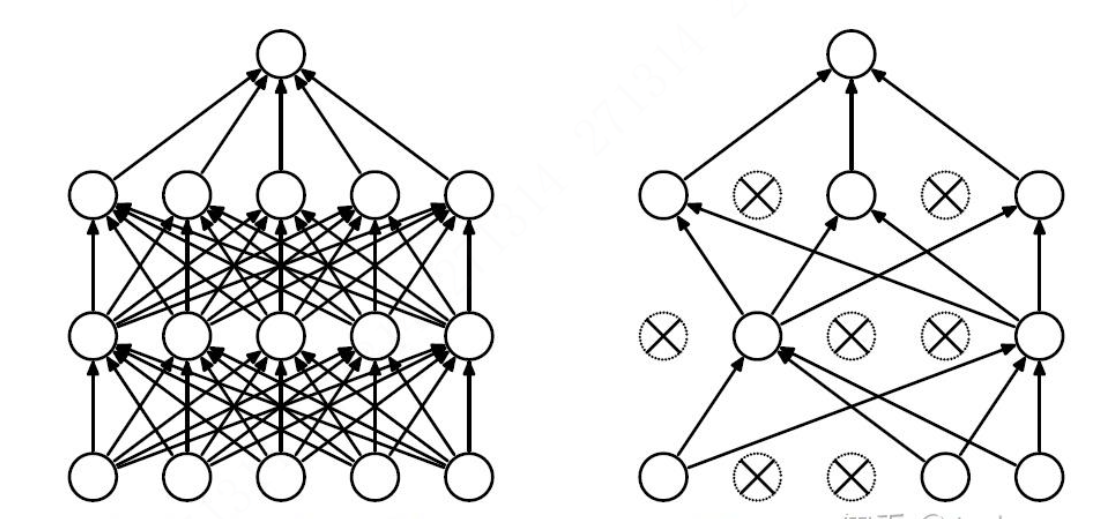
Dropout技术的基本原理
Dropout技术由Hinton等人在2012年提出,其核心思想是在训练神经网络时,随机地“丢弃”(即暂时忽略)网络中的一部分神经元(包括它们的连接)。具体来说,在每次前向传播和反向传播过程中,每个神经元都有一定概率(通常为0.5,但这个概率是可以调整的)被设置为0,这意味着这些神经元的输出对网络的其余部分没有影响,也不参与当前批次的权重更新。然而,在测试阶段,所有的神经元都会被保留,但它们的输出会乘以一个因子(通常是保留概率的倒数,如0.5的保留率则乘以2&#x

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











