






前面介绍了 PostgreSQL 基于 pgpool 实现读写分离实践、数据库备份与恢复、主从数据目录同步工具 pg_rewind、数据库作业调度工具、性能优化、日志与日常巡检等相关的知识点,今天我将详细的为大家介绍 PostgreSQL 数据库运维管理相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!
版本升级
小版本升级pg_upgrade
-
su - postgres -
#将旧的数据库目录重命名 -
mkdir /usr/local/pgsql.old -
chown -R postgres.postgres /usr/local/pgsql.old -
mv /usr/local/pgsql/* /usr/local/pgsql.old/ -
exit #切回root -
cd /opt -
rz #上传源码包 -
tar -zxvf postgresql-11.16.tar.gz #解压 -
cd postgresql-11.16/ #进入到源码目录 -
./configure --prefix=/usr/local/pgsql --with-openssl --with-pgport=5432 --with-tcl --with-perl --with-python --with-libxml --with-libxslt --with-ossp-uuid --with-pam --with-ldap -
gmake world #gmake包括第三方插件全部编译 -
gmake install-world #包括第三方插件全部安装 -
mkdir /usr/local/pgsql/data #创建数据目录 -
chown -R postgres.postgres /usr/local/pgsql -
chown -R postgres.postgres /usr/local/pgsql/data #授权数据目录 -
su - postgres -
#初始化数据库 -
/usr/local/pgsql/bin/initdb -D /usr/local/pgsql/data --encoding=UTF8 --lc-collate=en_US.UTF-8 --lc-ctype=en_US.UTF-8 #初始化数据库 -
#如果有外部extension插件则在这安装插件 -
#关闭旧数据库 -
/usr/local/pgsql.old/bin/pg_ctl -D /usr/local/pgsql.old/data/ stop -m fast -
#环境变量临时赋值本地ip -
export PGHOST=127.0.0.1 -
#升级前检查 -
/usr/local/pgsql/bin/pg_upgrade -d /usr/local/pgsql.old/data/ -D /usr/local/pgsql/data/ -b /usr/local/pgsql.old/bin/ -B /usr/local/pgsql/bin/ -c -
#升级 -
/usr/local/pgsql/bin/pg_upgrade -d /usr/local/pgsql.old/data/ -D /usr/local/pgsql/data/ -b /usr/local/pgsql.old/bin/ -B /usr/local/pgsql/bin/ -
#收集表的统计信息 -
./analyze_new_cluster.sh -
cd $PGDATA -
rm -f pg_hba.conf #删除新的pg_hba.conf -
rm -f postgresql.conf #删除新的postgresql.conf -
#拷贝旧的pg_hba.conf和postgresql.conf到升级的库 -
cp /usr/local/pgsql.old/data/pg_hba.conf $PGDATA/ -
cp /usr/local/pgsql.old/data/postgresql.conf $PGDATA/ -
#启动数据库 -
pg_ctl -D $PGDATA start
这是个bug,版本升级后,pg_config改变了,会导致后面装外部extension时没有装到指定目录。
-
#旧版本 -
/database/postgres11.old/psql/bin/pg_config -
BINDIR = /database/postgres11.old/psql/bin -
DOCDIR = /database/postgres11.old/psql/share/doc -
HTMLDIR = /database/postgres11.old/psql/share/doc -
INCLUDEDIR = /database/postgres11.old/psql/include -
PKGINCLUDEDIR = /database/postgres11.old/psql/include -
INCLUDEDIR-SERVER = /database/postgres11.old/psql/include/server -
LIBDIR = /database/postgres11.old/psql/lib -
PKGLIBDIR = /database/postgres11.old/psql/lib -
LOCALEDIR = /database/postgres11.old/psql/share/locale -
MANDIR = /database/postgres11.old/psql/share/man -
SHAREDIR = /database/postgres11.old/psql/share -
SYSCONFDIR = /database/postgres11.old/psql/etc -
PGXS = /database/postgres11.old/psql/lib/pgxs/src/makefiles/pgxs.mk -
CONFIGURE = '--prefix=/database/postgres11/psql/' '--with-perl' '--with-python' -
CC = gcc -
CPPFLAGS = -D_GNU_SOURCE -
CFLAGS = -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -
CFLAGS_SL = -fPIC -
LDFLAGS = -Wl,--as-needed -Wl,-rpath,'/database/postgres11/psql/lib',--enable-new-dtags -
LDFLAGS_EX = -
LDFLAGS_SL = -
LIBS = -lpgcommon -lpgport -lpthread -lz -lreadline -lrt -lcrypt -ldl -lm -
VERSION = PostgreSQL 11.6
更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
-
#新版本 -
/database/postgres11/psql/bin/pg_config -
BINDIR = /database/postgres11/psql/bin -
DOCDIR = /database/postgres11/psql/share/doc/postgresql -
HTMLDIR = /database/postgres11/psql/share/doc/postgresql -
INCLUDEDIR = /database/postgres11/psql/include -
PKGINCLUDEDIR = /database/postgres11/psql/include/postgresql -
INCLUDEDIR-SERVER = /database/postgres11/psql/include/postgresql/server -
LIBDIR = /database/postgres11/psql/lib -
PKGLIBDIR = /database/postgres11/psql/lib/postgresql -
LOCALEDIR = /database/postgres11/psql/share/locale -
MANDIR = /database/postgres11/psql/share/man -
SHAREDIR = /database/postgres11/psql/share/postgresql -
SYSCONFDIR = /database/postgres11/psql/etc/postgresql -
PGXS = /database/postgres11/psql/lib/postgresql/pgxs/src/makefiles/pgxs.mk -
CONFIGURE = '--prefix=' -
CC = gcc -
CPPFLAGS = -D_GNU_SOURCE -
CFLAGS = -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -
CFLAGS_SL = -fPIC -
LDFLAGS = -Wl,--as-needed -Wl,-rpath,'/lib',--enable-new-dtags -
LDFLAGS_EX = -
LDFLAGS_SL = -
LIBS = -lpgcommon -lpgport -lpthread -lz -lreadline -lrt -lcrypt -ldl -lm -
VERSION = PostgreSQL 11.16
![]()
大版本升级
逻辑备份旧数据库
详见:进阶数据库系列(二十):PostgreSQL 数据库备份与恢复
安装新版本数据库
然后创建对应的role和schema和database并且grant。
在新版本库中进行逻辑恢复
数据库管理
简单的psql命令
-
[postgres@pg_master ~]$ psql -h 192.168.233.30 -p 5432 -U postgres -d pgtest -E -
# -h 主机名 默认读取环境变量 PGHOST PGHOST默认为当前主机 -
# -p 端口号 默认读取环境变量 PGPORT PGPORT默认为5432 -
# -U 用户名 默认读取环境变量 PGUSER PGUSER默认为postgres -
# -d 数据库名 默认读取环境变量 PGDATABASE PGDATABASE默认为postgres -
# -W 强制输入密码 当有配值环境变量 PGPASSWORD 时,无需输入密码,加入该参数后,强制用户登录时输入密码 -
# -E 回显命令对应的sql语句
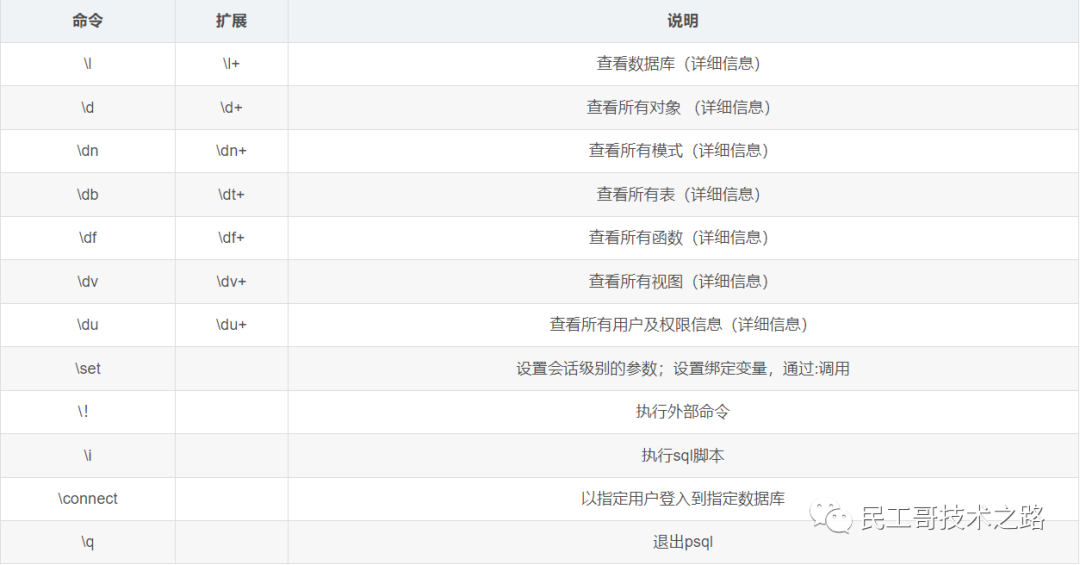
创建数据库
-
CREATE DATABASE name [ [WITH] [OWNER [=] user_name] -
[TEMPLATE [=] template] -
[ENCODING [=] encoding] -
[LC_COLLATE [=] lc_collate] -
[LC_CTYPE [=] lc_ctype] -
[TABLESPACE [=] tablespace] -
[CONNECTION LIMIT [=] connlimit ] ]
-
name:要创建的数据库的名称。
-
user_name:拥有新数据库的⽤户的名称,或者使⽤默认所有者(执⾏命令的⽤户)DEFAULT。
-
template:创建新数据库的模板的名称,或者DEFAULT使⽤默认模板的模板(template1)。
-
encoding:在新数据库中使⽤的字符集编码。指定字符串常量(例如’SQL_ASCII’),整数编码数字或
-
DEFAULT以使⽤默认编码。 有关更多信息,请参⻅字符集⽀持。
-
lc_collate:在新数据库中使⽤的排序规则(LC_COLLATE)。这会影响应⽤于字符串的排序顺序,例如在使⽤ORDER BY的查询中,以及在⽂本列的索引中使⽤的顺序。 默认设置是使⽤模板数据库的排序规则。有关其他限制,请参⻅“注释”部分。
-
lc_ctype:在新数据库中使⽤的字符分类(LC_CTYPE)。 这会影响字符的分类,例如下,上和数字。 默认值是使⽤模板数据库的字符分类。有关其他限制,请参⻅下⽂。
-
tablespace:将与新数据库关联的表空间的名称,或者为DEFAULT以使⽤模板数据库的表空间。该表空间将是⽤于在此数据库中创建的对象的默认表空间。
-
connlimit:可能的最⼤并发连接数。 默认值-1表示没有限制。
-
create database etl; --创建一个etl数据库,其他参数不用配置,直接用模板数据库的即可 -
drop database etl; --删除数据库
更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
用户管理
创建用户组
-
--创建管理员组 admin -
create role admin; -
--创建开发人员用户组 developer -
create role developer; -
--创建数据装载用户组 dataload -
create role dataload; -
--创建外部接口用户组 interface -
create role interface;
创建用户
-
--创建管理员 pgadmin -
create role pgadmin with superuser login password 'pgadminAa123456'; -
--创建开发用户 -
create role yuzhenchao with login password 'yzc+Aa123456' connection limit 10 valid until '2023-01-16 00:00:00'; -
--创建数据装载用户 -
create role copyload with login password 'copy+Aa123456' connection limit 60 valid until '2023-01-16 00:00:00'; -
--创建外部接口用户 -
create role finebi with login password 'finebi+Aa123456' connection limit 20 valid until '2023-01-16 00:00:00';
用户加入到指定的用户组
-
--将pgadmin加入到admin组 -
alter group admin add user pgadmin; -
--将yuzhenchao加入到developer组 -
alter group developer add user yuzhenchao; -
--将copyload加入到dataload组 -
alter group dataload add user copyload; -
--将finebi加入到interface用户组 -
alter group interface add user finebi;
创建用户名对应的模式名
-
--创建pgadmin对应的模式名pgadmin -
create schema pgadmin; -
--创建yuzhenchao对应的模式名yuzhenchao -
create schema yuzhenchao; -
--创建copyload对应的模式名copyload -
create schema copyload; -
--一般外部接口都只有只读权限,所以不需要给他建单独的模式
授权管理
用户模式映射
-
--将pgadmin模式的所有权限授权给pgadmin -
grant create,usage on schema pgadmin to pgadmin; -
--将yuzhenchao模式的所有权限授权给yuzhenchao -
grant create,usage on schema yuzhenchao to yuzhenchao; -
--将copyload模式的所有权限授权给copyload -
grant create,usage on schema copyload to copyload;
所有模式公开usage权限
-
--将pgadmin模式的usage权限授权给public -
grant usage on schema pgadmin to public; -
--将yuzhenchao模式的usage权限授权给public -
grant usage on schema yuzhenchao to public; -
--将copyload模式的usage权限授权给public -
grant usage on schema copyload to public;
回收public模式的create权限
-
--任何用户都拥有public模式的所有权限 -
--出于安全,回收任何用户在public的create权限 -
revoke create on schema public from public;
收回函数的执行权限
-
/* -
* pg中函数默认公开execute权限 -
* 通过pg的基于schema和基于role的默认权限实现 -
*/ -
--在schema为pgadmin上创建的任何函数,除定义者外,其他人调用需要显式授权 -
alter default privileges for role pgadmin revoke execute on functions from public; -
--由pgadmin用户创建的任何函数,除定义者外,其他人调用需要显式授权 -
alter default privileges in schema pgadmin revoke execute on functions from public; -
--在schema为yuzhenchao上创建的任何函数,除定义者外,其他人调用需要显式授权 -
alter default privileges for role yuzhenchao revoke execute on functions from public; -
--由yuzhenchao用户创建的任何函数,除定义者外,其他人调用需要显式授权 -
alter default privileges in schema yuzhenchao revoke execute on functions from public; -
--在schema为copyload上创建的任何函数,除定义者外,其他人调用需要显式授权 -
alter default privileges for role copyload revoke execute on functions from public; -
--由copyload用户创建的任何函数,除定义者外,其他人调用需要显式授权 -
alter default privileges in schema copyload revoke execute on functions from public;
![]()
公开表的select权限(视情况而定)
-
/* -
* pg与oracle不同,没有select any table的权限 -
* 但是pg有默认权限 -
* 通过pg的基于schema和基于role的默认权限实现 -
*/ -
--在schema为pgadmin上创建的任何表默认公开select权限 -
alter default privileges in schema pgadmin grant select on tables to public; -
--由pgadmin用户创建的任何表默认公开select权限 -
alter default privileges for role pgadmin grant select on tables to public; -
--在schema为yuzhenchao上创建的任何表默认公开select权限 -
alter default privileges in schema yuzhenchao grant select on tables to public; -
--由yuzhenchao用户创建的任何表默认公开select权限 -
alter default privileges for role yuzhenchao grant select on tables to public; -
--在schema为copyload上创建的任何表默认公开select权限 -
alter default privileges in schema copyload grant select on tables to public; -
--由copyload用户创建的任何表默认公开select权限 -
alter default privileges for role copyload grant select on tables to public;
![]()
动态sql函数
-
/* -
* 为了方便各用户的管理 -
* 需要用定义者权限创建动态sql函数 -
* 最终由pgadmin用户集中管理 -
*/ -
--为pgadmin用户创建sp_exec函数 -
create or replace function pgadmin.sp_exec(vsql varchar) -
returns void --返回空 -
language plpgsql -
security definer --定义者权限 -
as $function$ -
begin -
execute vsql; -
end; -
$function$ -
; -
--将对应模式的对应模式的函数给对应的模式的拥有者 -
alter function pgadmin.sp_exec(varchar) owner to pgadmin; -
--将对应模式的sp_exec函数授权给定义者和集中用户execute权限 -
grant execute on function pgadmin.sp_exec(varchar) to pgadmin; -
--为yuzhenchao用户创建sp_exec函数 -
create or replace function yuzhenchao.sp_exec(vsql varchar) -
returns void --返回空 -
language plpgsql -
security definer --定义者权限 -
as $function$ -
begin -
execute vsql; -
end; -
$function$ -
; -
--将对应模式的对应模式的函数给对应的模式的拥有者 -
alter function yuzhenchao.sp_exec(varchar) owner to yuzhenchao; -
--将对应模式的sp_exec函数授权给定义者和集中用户execute权限 -
grant execute on function yuzhenchao.sp_exec(varchar) to yuzhenchao,pgadmin; -
--为copyload用户创建sp_exec函数 -
create or replace function copyload.sp_exec(vsql varchar) -
returns void --返回空 -
language plpgsql -
security definer --定义者权限 -
as $function$ -
begin -
execute vsql; -
end; -
$function$ -
; -
--将对应模式的对应模式的函数给对应的模式的拥有者 -
alter function copyload.sp_exec(varchar) owner to copyload; -
--将对应模式的sp_exec函数授权给定义者和集中用户execute权限 -
grant execute on function copyload.sp_exec(varchar) to copyload,pgadmin;
![]()
更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
集中管理函数
-
create or replace function pgadmin.sp_execsql(exec_sql character varying,exec_user character varying) -
returns void -
language plpgsql -
security definer -
as $function$ -
/* 作者 : v-yuzhenc -
* 功能 : 集中处理程序,以某用户的权限执行某条sql语句 -
* exec_sql : 需要执行的sql语句 -
* exec_user : 需要以哪个用户的权限执行该sql语句 -
* */ -
declare -
p_user varchar := exec_user; -
o_search_path varchar; -
begin -
--记录原来的模式搜索路径 -
execute 'show search_path;' into o_search_path; -
--临时切换模式搜索路径 -
execute 'SET search_path TO '||p_user||',public,oracle'; -
case p_user -
when 'pgadmin' then perform pgadmin.sp_exec(exec_sql); -
when 'yuzhenchao' then perform yuzhenchao.sp_exec(exec_sql); -
when 'copyload' then perform copyload.sp_exec(exec_sql); -
else raise exception '未配置该用户:%',p_user; -
end case; -
--恢复模式搜索路径 -
execute 'SET search_path TO '||o_search_path; -
exception when others then -
--恢复模式搜索路径 -
execute 'SET search_path TO '||o_search_path; -
raise exception '%',sqlerrm; -
end; -
$function$ -
; -
--将对应模式的对应模式的函数给对应的模式的拥有者 -
alter function pgadmin.sp_execsql(varchar,varchar) owner to pgadmin; -
--将对应模式的sp_exec函数授权给定义者和集中用户execute权限 -
grant execute on function pgadmin.sp_execsql(varchar,varchar) to pgadmin;
![]()
备份与恢复
逻辑备份
-
su - postgres -
#先备份全局对象 -
pg_dumpall -f backup.sql --globals-only -
#再备份数据库 -
pg_dump hy_observe -Fc > hy_observe.dump
逻辑恢复
-
su - postgres -
#先恢复全局对象 -
psql -
\i backup.sql -
--创建对应的数据库 -
create database hy_observe; -
\q -
#pg_restore进行恢复 -
pg_restore -d hy_observe hy_observe.dump -v
物理备份
-
# 开启归档日志 -
vi $PGDATA/postgresql.conf -
wal_level = replica # 或者更高级别 -
archive_mode = on -
# backup_in_progress文件用来辅助wal日志备份,通过删除配合test指令控制wal日志备份 -
archive_command = 'test ! -f /usr/local/pgsql/backup_in_progress || (test ! -f /usr/local/pgsql/data/pg_archive/%f && cp %p /usr/local/pgsql/data/pg_archive/%f)' -
# 重启数据库 -
pg_ctl restart -mf -
touch /usr/local/pgsql/backup_in_progress -
# 开始基础备份,可以在代码里连接数据库执行 -
psql -c "select pg_start_backup('hot_backup');" -
# 将数据库文件进行备份 -
BACKUPDATE=`date '+%Y%m%d%H%m%S'` -
tar -cf /data/pg_backup/pgbackup_${BACKUPDATE}.tar $PGDATA -
# 结束备份,可以在代码里连接数据库执行 -
psql -c "select pg_stop_backup();" -
# 停止wal日志备份 -
rm /usr/local/pgsql/backup_in_progress -
# 将wal日志和基础备份打包在一起 -
tar -rf /data/pg_backup/pgbackup_${BACKUPDATE}.tar /usr/local/pgsql/data/pg_archive
![]()
物理恢复
-
pg_ctl stop -mf -
mv $PGDATA ${PGDATA}.old -
tar -xf /data/pg_backup/pgbackup_${BACKUPDATE}.tar -C $PGDATA -
vi $PGDATA/recovery.conf -
restore_command = 'cp /usr/local/pgsql/data/pg_archive/%f %p' -
# 指定要恢复的时间点,也可以不指定,直接恢复所有数据 -
recovery_target_time = '2022-09-01 10:00:00' -
pg_ctl start
更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
开启ssl
-
su - postgres -
#进入到数据目录 -
cd $PGDATA -
#创建证书 -
openssl req -new -x509 -days 365 -nodes -text -out server.crt -keyout server.key -subj "/CN=pg_master" -
#只读权限 -
chmod 400 server.{crt,key} -
#修改pg_hba.conf -
vi $PGDATA/pg_hba.conf -
#所有远程连接都通过ssl连接 -
hostssl all postgres 0.0.0.0/0 md5 -
hostssl all repl 192.168.233.0/24 trust -
hostssl replication repl 192.168.233.0/24 md5 -
hostssl all all 0.0.0.0/0 md5
![]()
-
#开启ssl -
alter system set ssl=on; -
#重新加载数据库配置 -
select pg_reload_conf(); -
#重新登录 -
\q -
psql -
#查看当前连接信息 -
\conninfo -
#查看所有连接信息 -
select -
pg_ssl.pid -
,pg_ssl.ssl -
,pg_ssl.version -
,pg_sa.backend_type -
,pg_sa.usename -
,pg_sa.client_addr -
from pg_stat_ssl pg_ssl -
inner join pg_stat_activity pg_sa -
on (pg_ssl.pid = pg_sa.pid);
![]()
密码安全策略
密码加密存储
-
show password_encryption;--md5 -
select * from pg_shadow where usename='yuzhenchao';
密码有效期
-
alter role yuzhenchao valid until '2022-12-31 23:59:59'; -
select * from pg_user where usename='yuzhenchao';
注意:
-
pg密码有效期仅针对客户端有效,服务器端不受限制。
-
网络访问控制文件中不能配置为trust认证方式
密码复杂度策略
ls -atl $LD_LIBRARY_PATH/passwordcheck*alter system set shared_preload_libraries=pg_stat_statements,passwordcheck;pg_ctl restart -mf密码验证失败延迟
ls -atl $LD_LIBRARY_PATH/auth_delay*-
--重启生效 -
alter system set shared_preload_libraries=pg_stat_statements,passwordcheck,auth_delay;
pg_ctl restart -mf-
--重新加载生效 -
alter system set auth_delay.milliseconds=5000; -
--重新加载 -
select pg_reload_conf();
pg_ctl reload防止密码记录到数据库日志
-
使用createuser命令加上-W选项创建用户
开启服务器日志
postgresql 服务器日志: ,更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
postgresql扩展组件
oracle兼容性函数
-
su - postgres -
cd /opt -
wget https://api.pgxn.org/dist/orafce/3.21.0/orafce-3.21.0.zip --no-check-certificate -
unzip orafce-3.21.0.zip #解压 -
cd orafce-3.21.0/ #进入orafce-3.21.0目录 -
make clean -
make #编译 -
make install #安装 -
psql -d pgtest -U pgadmin -W -
create extension orafce; --创建orafce扩展 -
\q
postgis模块
安装cmake3.x版本
-
cd /opt -
wget https://github.com/Kitware/CMake/releases/download/v3.16.2/cmake-3.16.2.tar.gz -
tar -zxvf cmake-3.16.2.tar.gz -
cd cmake-3.16.2 -
./configure --prefix=/usr/local/cmake-3.16.2 -
make -j 4 -
make install -
vi /etc/profile -
export CMAKE_HOME=/usr/local/cmake-3.16.2 -
export PATH=$CMAKE_HOME/bin:$PATH -
source /etc/profile
安装geos
-
cd /opt -
wget https://download.osgeo.org/geos/geos-3.11.0.tar.bz2 --no-check-certificate -
tar -jxvf geos-3.11.0.tar.bz2 -
cd geos-3.11.0/ -
./configure --prefix=/usr/local/geos-3.11.0 -
make -j 4 -
make install
安装sqlite3.11以上版本
-
cd /opt -
wget https://www.sqlite.org/2022/sqlite-autoconf-3390100.tar.gz --no-check-certificate -
tar -zxvf sqlite-autoconf-3390100.tar.gz -
cd sqlite-autoconf-3390100 -
vi ./sqlite3.c -
#define SQLITE_CORE 1 -
#define SQLITE_AMALGAMATION 1 -
#ifndef SQLITE_PRIVATE -
# define SQLITE_PRIVATE static -
#endif -
#define SQLITE_ENABLE_COLUMN_METADATA 1 //增加这句 -
./configure --prefix=/usr/local/sqlite -
make -j 4 -
make install -
mv /usr/bin/sqlite3 /usr/bin/sqlite3_old -
ln -s /usr/local/sqlite/bin/sqlite3 /usr/bin/sqlite3 -
sqlite3 --version -
export PKG_CONFIG_PATH=/usr/local/sqlite/lib/pkgconfig:$PKG_CONFIG_PATH
![]()
安装proj
-
cd /opt -
wget http://download.osgeo.org/proj/proj-6.3.2.tar.gz -
tar -zxvf proj-6.3.2.tar.gz -
cd proj-6.3.2/ -
./configure --prefix=/usr/local/proj-6.3.2 -
make -j 4 -
make install
安装gdal
-
cd /opt -
wget https://download.osgeo.org/gdal/3.2.1/gdal-3.2.1.tar.gz --no-check-certificate -
tar -zxvf gdal-3.2.1.tar.gz -
cd gdal-3.2.1 -
./configure --prefix=/usr/local/gdal-3.2.1 --with-proj=/usr/local/proj-6.3.2 -
make -j 4 -
make install
安装json-c
-
cd /opt -
wget https://github.com/json-c/json-c/archive/json-c-0.13.1-20180305.tar.gz -
tar -zxvf json-c-0.13.1-20180305.tar.gz -
cd json-c-json-c-0.13.1-20180305 -
./configure --prefix=/usr/local/json-c-0.13.1 -
make -j 4 -
make install
安装libxml
-
cd /opt -
wget https://mirror.ossplanet.net/gnome/sources/libxml2/2.9/libxml2-2.9.14.tar.xz --no-check-certificate -
tar -xvf libxml2-2.9.14.tar.xz -
cd libxml2-2.9.14 -
chmod +x configure -
./configure --prefix=/usr/local/libxml2-2.9.14 -
make -j 4 -
make install
安装protobuf
-
cd /opt -
wget https://github.com/protocolbuffers/protobuf/archive/v3.10.1.tar.gz -
tar -zxvf v3.10.1.tar.gz -
cd protobuf-3.10.1/ -
./autogen.sh #自动生成configure配置文件 -
./configure --prefix=/usr/local/protobuf-3.10.1 -
make -j 4 -
make install -
vi /etc/profile -
export PROTOBUF_HOME=/usr/local/protobuf-3.10.1 -
export PATH=$PROTOBUF_HOME/bin:$PATH -
source /etc/profile -
protoc --version -
libprotoc 3.10.1
安装protobuf-c
-
cd /opt -
wget https://github.com/protobuf-c/protobuf-c/releases/download/v1.3.2/protobuf-c-1.3.2.tar.gz -
tar -zxvf protobuf-c-1.3.2.tar.gz -
cd protobuf-c-1.3.2/ -
#导入protobuf的pkgconfig,否则"--No package 'protobuf' found" -
export PKG_CONFIG_PATH=/usr/local/protobuf-3.10.1/lib/pkgconfig -
./configure --prefix=/usr/local/protobuf-c-1.3.2 -
make -j 4 -
make install -
vi /etc/profile -
export PROTOBUFC_HOME=/usr/local/protobuf-c-1.3.2 -
export PATH=$PROTOBUFC_HOME/bin:$PATH -
source /etc/profile
![]()
安装boost-devel
yum -y install boost-devel安装cgal
-
cd /opt -
wget https://github.com/CGAL/cgal/archive/releases/CGAL-4.13.tar.gz -
tar -zxvf CGAL-4.13.tar.gz -
cd cgal-releases-CGAL-4.13/ -
mkdir build && cd build -
cmake .. -
make -
make install
安装sfcgal
-
cd /opt -
wget https://github.com/Oslandia/SFCGAL/archive/v1.3.7.tar.gz -
tar -zxvf v1.3.7.tar.gz -
cd SFCGAL-1.3.7 -
mkdir build && cd build -
cmake -DCMAKE_INSTALL_PREFIX=/usr/local/sfcgal-1.3.7 .. -
make -j 4 -
make install
安装postgis
-
vi /etc/ld.so.conf -
include ld.so.conf.d/*.conf -
/usr/local/pgsql/lib -
/usr/local/proj-6.3.2/lib -
/usr/local/gdal-3.2.1/lib -
/usr/local/geos-3.11.0/lib64 -
/usr/local/sfcgal-1.3.7/lib64 -
/usr/local/json-c-0.13.1/lib -
/usr/local/libxml2-2.9.14/lib -
/usr/local/protobuf-3.10.1/lib -
/usr/local/protobuf-c-1.3.2/lib -
ldconfig -v #重启生效 -
su - postgres -
cd /usr/local/pgsql/contrib -
wget http://download.osgeo.org/postgis/source/postgis-3.2.1.tar.gz -
tar -zxvf postgis-3.2.1.tar.gz -
cd postgis-3.2.1/ -
./configure --prefix=/usr/local/pgsql --with-gdalconfig=/usr/local/gdal-3.2.1/bin/gdal-config --with-pgconfig=/usr/local/pgsql/bin/pg_config --with-geosconfig=/usr/local/geos-3.11.0/bin/geos-config --with-projdir=/usr/local/proj-6.3.2 --with-xml2config=/usr/local/libxml2-2.9.14/bin/xml2-config --with-jsondir=/usr/local/json-c-0.13.1 --with-protobufdir=/usr/local/protobuf-c-1.3.2 --with-sfcgal=/usr/local/sfcgal-1.3.7/bin/sfcgal-config -
make -j 4 -
make install
![]()
创建extension
-
psql -d pgtest -U pgadmin -W -
--postgis扩展 -
create extension postgis; -
--验证栅格类数据需要的raster扩展 -
create extension postgis_raster; -
--如果安装带有sfcgal,验证下三维sfcgal扩展 -
create extension postgis_sfcgal; -
create extension fuzzystrmatch; -
create extension postgis_tiger_geocoder; -
create extension postgis_topology; -
\q
-
创建extension时遇到问题
could not load library "/usr/local/pgsql/lib/postgis-3.so": /usr/local/pgsql/lib/postgis-3.so: undefined symbol: GEOSLargestEmpt-
查找原因,是geos存在多个版本
-
ldconfig -p | grep libgeos_c.so.1 -
libgeos_c.so.1 (libc6,x86-64) => /usr/geos39/lib64/libgeos_c.so.1 -
libgeos_c.so.1 (libc6,x86-64) => /usr/local/geos-3.11.0/lib64/libgeos_c.so.1 -
#查找geos39 -
rpm -qa geos39 -
geos39-3.9.2-1.rhel7.x86_64
-
解决方案:卸载geos39-3.9.2-1.rhel7.x86_64
-
再次校验,发现只剩一个了
-
ldconfig -p | grep libgeos_c.so.1 -
libgeos_c.so.1 (libc6,x86-64) => /usr/local/geos-3.11.0/lib64/libgeos_c.so.1
-
最后 create extension postgis; 成功了
更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
数据库开发规范
命名规范
-
标识符总长度不超过63,由于oracle标识符长度不超过30,原则上,为了兼容oracle,标识符长度最好不要超过30;
-
对象名(表名、列名、函数名、视图名、序列名、等对象名称)规范,对象名务必只使用小写字母,下划线,数字。不要以pg开头,不要以数字开头,不要使用保留字;
-
查询中的别名不要使用 “小写字母,下划线,数字” 以外的字符,例如中文;
-
主键索引应以 pk_ 开头, 唯一索引要以 uk_ 开头,普通索引要以 idx_ 打头
-
临时表以 tmp_ 开头,子表以规则结尾,例如按年分区的主表如果为tbl, 则子表为tbl_2016,tbl_2017等;
-
库名最好以部门名字开头 + 功能,如 xxx_yyy,xxx_zzz,便于辨识;
-
禁用public schema,应该为每个应用分配对应的schema,schema_name最好与user name一致。
设计规范
-
多表中的相同列,必须保证列名一致,数据类型一致;
-
btree索引字段不建议超过2000字节,如果有超过2000字节的字段需要建索引,建议使用函数索引(例如哈希值索引),或者使用分词索引;
-
对于频繁更新的表,建议建表时指定表的fillfactor=85,每页预留15%的空间给HOT更新使用;(create table test123(id int, info text) with(fillfactor=85); CREATE TABLE)
-
表结构中字段定义的数据类型与应用程序中的定义保持一致,表之间字段校对规则一致,避免报错或无法使用索引的情况发生;
-
建议有定期历史数据删除需求的业务,表按时间分区,删除时不要使用DELETE操作,而是DROP或者TRUNCATE对应的表;
-
为了全球化的需求,所有的字符存储与表示,均以UTF-8编码;
-
对于值与堆表的存储顺序线性相关的数据,如果通常的查询为范围查询,建议使用BRIN索引。例如流式数据,时间字段或自增字段,可以使用BRIN索引,减少索引的大小,加快数据插入速度。(create index idx on tbl using brin(id); )
-
设计时应尽可能选择合适的数据类型,能用数字的坚决不用字符串,使用好的数据类型,可以使用数据库的索引,操作符,函数,提高数据的查询效率;
-
应该尽量避免全表扫描(除了大数据量扫描的数据分析),PostgreSQL支持几乎所有数据类型的索引;
-
应该尽量避免使用数据库触发器,这会使得数据处理逻辑复杂,不便于调试;
-
未使用的大对象,一定要同时删除数据部分,否则大对象数据会一直存在数据库中,与内存泄露类似;
-
对于固定条件的查询,可以使用部分索引,减少索引的大小,同时提升查询效率;(create index idx on tbl (col) where id=1;)
-
对于经常使用表达式作为查询条件的语句,可以使用表达式或函数索引加速查询;(create index idx on tbl ( exp ); )
-
如果需要调试较为复杂的逻辑时,不建议写成函数进行调试,可以使用plpgsql的匿名代码块;
-
当用户有prefix或者 suffix的模糊查询需求时,可以使用索引,或反转索引达到提速的需求;(select * from tbl where reverse(col) ~ ‘^def’; – 后缀查询使用反转函数索引)
-
用户应该对频繁访问的大表(通常指超过8GB的表,或者超过1000万记录的表)进行分区,从而提升查询的效率、更新的效率、备份与恢复的效率、建索引的效率等等;
-
设计表结构时必须加上字段数据的入库时间inputed_time和数据的更新时间updated_time;
查询规范
-
统计行数用count(*)或者count(1),count(列名)不会统计列为空的行;
-
count(distinct col) 计算该列的非NULL不重复数量,NULL不被计数;
-
count(distinct (col1,col2,…) ) 计算多列的唯一值时,NULL会被计数,同时NULL与NULL会被认为是想同的;
-
NULL是UNKNOWN的意思,也就是不知道是什么。 因此NULL与任意值的逻辑判断都返回NULL;
-
除非是ETL程序,否则应该尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理;
-
尽量不要使用 select * from t ,用具体的字段列表代替*,不要返回用不到的任何字段,另外表结构发生变化也容易出现问题。
管理规范
-
数据订正时,删除和修改记录时,要先select,避免出现误删除,确认无误才能提交执行;
-
用户可以使用explain analyze查看实际的执行计划,但是如果需要查看的执行计划设计数据的变更,必须在事务中执行explain analyze,然后回滚;
-
如何并行创建索引,不堵塞表的DML,创建索引时加CONCURRENTLY关键字,就可以并行创建,不会堵塞DML操作,否则会堵塞DML操作;(create index CONCURRENTLY idx on tbl(id); )
-
为数据库访问账号设置复杂密码;
-
业务系统,开发测试账号,不要使用数据库超级用户,非常危险;
-
应该为每个业务分配不同的数据库账号,禁止多个业务共用一个数据库账号;
-
大批量数据入库的优化,如果有大批量的数据入库,建议使用copy语法,或者 insert into table values (),(),…(); 的方式,提高写入速度。
稳定性与性能规范
-
游标使用后要及时关闭;
-
两阶段提交的事务,要及时提交或回滚,否则可能导致数据库膨胀;
-
不要使用delete 全表,性能很差,请使用truncate代替;
-
应用程序一定要开启autocommit,同时避免应用程序自动begin事务,并且不进行任何操作的情况发生,某些框架可能会有这样的问题;
-
在函数中,或程序中,不要使用count(*)判断是否有数据,很慢。 建议的方法是limit 1;
-
必须选择合适的事务隔离级别,不要使用越级的隔离级别,例如READ COMMITTED可以满足时,就不要使用repeatable read和serializable隔离级别;
-
高峰期对大表添加包含默认值的字段,会导致表的rewrite,建议只添加不包含默认值的字段,业务逻辑层面后期处理默认值;
-
可以预估SQL执行时间的操作,建议设置语句级别的超时,可以防止雪崩,也可以防止长时间持锁;
-
PostgreSQL支持DDL事务,支持回滚DDL,建议将DDL封装在事务中执行,必要时可以回滚,但是需要注意事务的长度,避免长时间堵塞DDL对象的读操作;
-
如果用户需要在插入数据和,删除数据前,或者修改数据后马上拿到插入或被删除或修改后的数据,建议使用insert into … returning …; delete … returning …或update … returning …; 语法。减少数据库交互次数;
-
自增字段建议使用序列,序列分为2字节,4字节,8字节几种(serial2,serial4,serial8)。按实际情况选择。 禁止使用触发器产生序列值;
-
使用窗口查询减少数据库和应用的交互次数;
-
如何判断两个值是不是不一样(并且将NULL视为一样的值),使用col1 IS DISTINCT FROM col2;
-
对于经常变更,或者新增,删除记录的表,应该尽量加快这种表的统计信息采样频率,获得较实时的采样,输出较好的执行计划。
性能优化
优化简介
-
PostgreSQL优化一方面是找出系统的瓶颈,提高PostgreSQL数据库整体的性能;
-
另一方面,需要合理的结构设计和参数调整,以提高用户操作响应的速度;
-
同时还要尽可能的节省系统资源,以便系统可以提供更大负荷的服务。
PostgreSQL数据库优化是多方面的,原则是减少系统的瓶颈,减少资源的占用,增加系统的反应速度。例如:
-
通过优化文件系统,提高磁盘IO的读写速度;
-
通过优化操作系统调度策略,提高PostgreSQL的在高负荷情况下负载能力;
-
优化表结构、索引、查询语句等使查询响应更快。
首先了解系统情况后便可做相关合理的调整,以达到性能优化的目的。
-
/*CPU查看CPU型号*/ -
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c -
/*查看物理CPU个数*/ -
cat /proc/cpuinfo | grep "physical id" | sort -u | wc -l -
/*查看逻辑CPU个数*/ -
cat /proc/cpuinfo | grep "processor" | wc -l -
/*查看CPU内核数*/ -
cat /proc/cpuinfo | grep "cpu cores" | uniq -
/*查看单个物理CPU封装的逻辑CPU数量*/ -
cat /proc/cpuinfo | grep "siblings" | uniq -
/*计算是否开启超线程 -
##逻辑CPU > 物理CPU x CPU核数 #开启超线程 -
##逻辑CPU = 物理CPU x CPU核数 #没有开启超线程或不支持超线程*/ -
/*查看是否超线程,如果cpu cores数量和siblings数量一致,则没有启用超线程,否则超线程被启用。*/ -
cat /proc/cpuinfo | grep -e "cpu cores" -e "siblings" | sort | uniq -
/*内存 -
TOP -
/*命令经常用来监控linux的系统状况,比如cpu、内存的使用等。*/ -
/*查看某个用户内存使用情况,如:postgres*/ -
top -u postgres -
/* -
内容解释: -
PID:#进程的ID -
USER:#进程所有者 -
PR:#进程的优先级别,越小越优先被执行 -
NInice:#值 -
VIRT:#进程占用的虚拟内存 -
RES:#进程占用的物理内存 -
SHR:#进程使用的共享内存 -
S:#进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值为负数 -
%CPU:#进程占用CPU的使用率 -
%MEM:#进程使用的物理内存和总内存的百分比 -
TIME+:#该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。 -
COMMAND:#进程启动命令名称 -
常用的命令: -
P:#按%CPU使用率排行 -
T:#按MITE+排行 -
M:#按%MEM排行 -
/*查看进程相关信息占用的内存情况,(进程号可以通过ps查看)如下所示:*/ -
pmap -d 14596 -
ps -e -o 'pid,comm,args,pcpu,rsz,vsz,stime,user,uid' -
ps -e -o 'pid,comm,args,pcpu,rsz,vsz,stime,user,uid' | grep postgres | sort -nrk5 -
/*其中rsz为实际内存,上例实现按内存排序,由大到小*/ -
/*看内存占用*/ -
free -m -
/*看硬盘占用率*/ -
df -h -
/*查看IO情况*/ -
iostat -x 1 10 -
/*如果 iostat 没有,要 yum install sysstat安装这个包,第一眼看下图红色圈圈的那个如果%util接近100%,表明I/O请求太多,I/O系统已经满负荷,磁盘可能存在瓶颈,一般%util大于70%,I/O压力就比较大,读取速度有较多的wait,然后再看其他的参数, -
内容解释: -
rrqm/s:#每秒进行merge的读操作数目。即delta(rmerge)/s -
wrqm/s:#每秒进行merge的写操作数目。即delta(wmerge)/s -
r/s:#每秒完成的读I/O设备次数。即delta(rio)/s -
w/s:#每秒完成的写I/0设备次数。即delta(wio)/s -
rsec/s:#每秒读扇区数。即delta(rsect)/s -
wsec/s:#每秒写扇区数。即delta(wsect)/s -
rKB/s:#每秒读K字节数。是rsec/s的一半,因为每扇区大小为512字节 -
wKB/s:#每秒写K字节数。是wsec/s的一半 -
avgrq-sz:#平均每次设备I/O操作的数据大小(扇区)。即delta(rsect+wsect)/delta(rio+wio) -
avgqu-sz:#平均I/O队列长度。即delta(aveq)/s/1000(因为aveq的单位为毫秒) -
await:#平均每次设备I/O操作的等待时间(毫秒)。即delta(ruse+wuse)/delta(rio+wio) -
svctm:#平均每次设备I/O操作的服务时间(毫秒)。即delta(use)/delta(rio+wio) -
%util:#一秒中有百分之多少的时间用于I/O操作,或者说一秒中有多少时间I/O队列是非空的 -
/*找到对应进程*/ -
ll /proc/进程号/exe
更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
优化查询
分析查询语句EXPLAIN
使用EXPLAIN语句来分析一个查询语句,执行如下语句:
EXPLAIN ANALYZE SELECT * FROM fruits;索引对查询速度的影响
下面是查询语句中不使用索引和使用索引的对比。首先,分析未使用索引时的查询情况,EXPLAIN语句执行如下:
EXPLAIN SELECT * FROM fruits WHERE f_name='apple';然后,在fruits表的f_name字段上加上索引。执行添加索引的语句及结果如下:
CREATE INDEX index_name ON fruits(f_name);现在,再分析上面的查询语句。执行的EXPLAIN语句及结果如下:
EXPLAIN ANALYZE SELECT * FROM fruits WHERE f_name='apple';优化子查询
子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作。子查询虽然可以使查询语句很灵活,但执行效率不高。执行子查询时,PostgreSQL需要为内层查询语句的查询结果建立一个临时表。然后外层查询语句从临时表中查询记 录。查询完毕后,再撤销这些临时表。因此,子查询的速度会受到一定的影响。如果查询的数据量比较大,这种影响就会随之增大。
在PostgreSQL中可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表,其速度比子查询要快,如果查询中使用到索引的话,性能会更好。连接之所以更有效率,是因为PostgreSQL不需要在内存中创建临时表来完成查询工作。
优化数据库结构
-
将字段很多的表分解成多个表
-
增加中间表
-
增加冗余字段
设计数据库表时尽量遵循范式理论的规约,尽可能少的冗余字段,让数据库设计看起来精致、优雅。但是,合理的加入冗余字段可以提高查询速度。
-
优化插入记录的速度
-
删除索引
-
使用批量插入
-
删除外键约束
-
禁止自动提交
-
使用COPY批量导入
-
分析表的统计信息
PostgreSQL中提供了ANALYZE语句收集表内容的统计信息,然后把结果保存在系统表pg_statistic 里。
使用ANALYZ来分析fruits表,执行的语句:
ANALYZE VERBOSE fruits;更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
优化PostgreSQL服务器
优化服务器硬件
-
配置较大的内存。足够大的内存,是提高PostgreSQL数据库性能的方法之一。内存的速度比磁盘I/0快得多,可以通过增加系统的缓冲区容量,使数据在内存中停留的时间更 长,以减少磁盘I/0。
-
配置高速磁盘系统,以减少读盘的等待时间,提高响应速度。
-
合理分布磁盘I/O,把磁盘I/O分散在多个设备上,以减少资源竞争,提高并行操作能力。
-
配置多处理器,PostgreSQL是多线程的数据库,多处理器可同时执行多个线程。
PostgreSQL 系统参数
shared_buffers
PostgreSQL既使用自身的缓冲区,也使用内核缓冲IO。这意味着数据会在内存中存储两次,首先是存入PostgreSQL缓冲区,然后是内核缓冲区。这被称为双重缓冲区处理。对大多数操作系统来说,这个参数是最有效的用于调优的参数。此参数的作用是设置PostgreSQL中用于缓存的专用内存量。
shared_buffers的默认值设置得非常低,因为某些机器和操作系统不支持使用更高的值。但在大多数现代设备中,通常需要增大此参数的值才能获得最佳性能。
建议的设置值为机器总内存大小的25%,但是也可以根据实际情况尝试设置更低和更高的值。实际值取决于机器的具体配置和工作的数据量大小。举个例子,如果工作数据集可以很容易地放入内存中,那么可以增加shared_buffers的值来包含整个数据库,以便整个工作数据集可以保留在缓存中。
在生产环境中,将shared_buffers设置为较大的值通常可以提供非常好的性能,但应当时刻注意找到平衡点。
查看当前shared_buffers的值:
-
postgres=# show shared_buffers; -
shared_buffers -
---------------- -
128MB -
(1 row)
wal_buffers
PostgreSQL将其WAL(预写日志)记录写入缓冲区,然后将这些缓冲区刷新到磁盘。由wal_buffers定义的缓冲区的默认大小为16MB,但如果有大量并发连接的话,则设置为一个较高的值可以提供更好的性能。
查看当前wal_buffers的值:
-
postgres=# show wal_buffers; -
wal_buffers -
------------- -
4MB -
(1 row)
effective_cache_size
effective_cache_size提供可用于磁盘高速缓存的内存量的估计值。它只是一个建议值,而不是确切分配的内存或缓存大小。它不会实际分配内存,而是会告知优化器内核中可用的缓存量。在一个索引的代价估计中,更高的数值会使得索引扫描更可能被使用,更低的数值会使得顺序扫描更可能被使用。在设置这个参数时,还应该考虑PostgreSQL的共享缓冲区以及将被用于PostgreSQL数据文件的内核磁盘缓冲区。默认值是4GB。
查看当前effective_cache_size的值:
-
postgres=# show effective_cache_size; -
effective_cache_size -
---------------------- -
4GB -
(1 row)
work_mem
此配置用于复合排序。内存中的排序比溢出到磁盘的排序快得多,设置非常高的值可能会导致部署环境出现内存瓶颈,因为此参数是按用户排序操作。如果有多个用户尝试执行排序操作,则系统将为所有用户分配大小为work_mem *总排序操作数的空间。全局设置此参数可能会导致内存使用率过高,因此强烈建议在会话级别修改此参数值。默认值为4MB。
查看当前work_mem的值:
-
postgres=# show work_mem; -
work_mem -
---------- -
4MB -
(1 row)
maintenance_work_mem
maintenance_work_mem是用于维护任务的内存设置。默认值为64MB。设置较大的值对于VACUUM,RESTORE,CREATE INDEX,ADD FOREIGN KEY和ALTER TABLE等操作的性能提升效果显著。
查看当前maintenance_work_mem的值:
-
postgres=# show maintenance_work_mem; -
maintenance_work_mem -
---------------------- -
64MB -
(1 row)
synchronous_commit
此参数的作用为在向客户端返回成功状态之前,强制提交等待WAL被写入磁盘。这是性能和可靠性之间的权衡。如果应用程序被设计为性能比可靠性更重要,那么关闭synchronous_commit。这意味着成功状态与保证写入磁盘之间会存在时间差。在服务器崩溃的情况下,即使客户端在提交时收到成功消息,数据也可能丢失。
查看当前synchronous_commit的设置值:
-
postgres=# show synchronous_commit; -
synchronous_commit -
-------------------- -
on -
(1 row)
checkpoint_timeout和checkpoint_completion_target
PostgreSQL将更改写入WAL。检查点进程将数据刷新到数据文件中。发生CHECKPOINT时完成此操作。这是一项开销很大的操作,整个过程涉及大量的磁盘读/写操作。用户可以在需要时随时发出CHECKPOINT指令,或者通过PostgreSQL的参数checkpoint_timeout和checkpoint_completion_target来自动完成。
checkpoint_timeout参数用于设置WAL检查点之间的时间。将此设置得太低会减少崩溃恢复时间,因为更多数据会写入磁盘,但由于每个检查点都会占用系统资源,因此也会损害性能。此参数只能在postgresql.conf文件中或在服务器命令行上设置。
checkpoint_completion_target指定检查点完成的目标,作为检查点之间总时间的一部分。默认值是 0.5。这个参数只能在postgresql.conf文件中或在服务器命令行上设置。高频率的检查点可能会影响性能。
查看当前checkpoint_timeout和checkpoint_completion_target的值:
-
postgres=# show checkpoint_timeout; -
checkpoint_timeout -
-------------------- -
5min -
(1 row) -
-
postgres=# show checkpoint_completion_target; -
checkpoint_completion_target -
------------------------------ -
0.5 -
(1 row)
max_connections
允许客户端连接的最大数目
fsync
强制把数据同步更新到磁盘,如果系统的IO压力很大,把改参数改为off
在fsync打开的情况下,优化后性能能够提升30%左右。因为有部分优化选项在默认的SQL测试语句中没有体现出它的优势,如果到实际测试中,提升应该不止30%。
测试的过程中,主要的瓶颈就在系统的IO,如果需要减少IO的负荷,最直接的方法就是把fsync关闭,但是这样就会在掉电的情况下,可能会丢失部分数据。
commit_delay
事务提交后,日志写到wal log上到wal_buffer写入到磁盘的时间间隔。需要配合commit_sibling。能够一次写入多个事务,减少IO,提高性能
commit_siblings
设置触发commit_delay的并发事务数,根据并发事务多少来配置。减少IO,提高性能
注意:并非所有参数都适用于所有应用程序类型。某些应用程序通过调整参数可以提高性能,有些则不会。必须针对应用程序及操作系统的特定需求来调整数据库参数。
下面介绍几个我认为重要的:
增加maintenance_work_mem参数大小
增加这个参数可以提升CREATE INDEX和ALTER TABLE ADD FOREIGN KEY的执行效率。
增加checkpoint_segments参数的大小
增加这个参数可以提升大量数据导入时候的速度。
设置archive_mode无效
这个参数设置为无效的时候,能够提升以下的操作的速度
-
CREATE TABLE AS SELECT
-
CREATE INDEX
-
ALTER TABLE SET TABLESPACE
-
CLUSTER等。
autovacuum相关参数 (autovacuum介绍文章)
autovacuum:默认为on,表示是否开起autovacuum。默认开起。特别的,当需要冻结xid时,尽管此值为off,PG也会进行vacuum。
autovacuum_naptime:下一次vacuum的时间,默认1min。这个naptime会被vacuum launcher分配到每个DB上。autovacuum_naptime/num of db。
log_autovacuum_min_duration:记录autovacuum动作到日志文件,当vacuum动作超过此值时。“-1”表示不记录。“0”表示每次都记录。
autovacuum_max_workers:最大同时运行的worker数量,不包含launcher本身。
autovacuum_work_mem :每个worker可使用的最大内存数。
autovacuum_vacuum_threshold :默认50。与autovacuum_vacuum_scale_factor配合使用,autovacuum_vacuum_scale_factor默认值为20%。当update,delete的tuples数量超过autovacuum_vacuum_scale_factor*table_size+autovacuum_vacuum_threshold时,进行vacuum。如果要使vacuum工作勤奋点,则将此值改小。
autovacuum_analyze_threshold :默认50。与autovacuum_analyze_scale_factor配合使用。
autovacuum_analyze_scale_factor :默认10%。当update,insert,delete的tuples数量超过autovacuum_analyze_scale_factor*table_size+autovacuum_analyze_threshold时,进行analyze。
autovacuum_freeze_max_age:200 million。离下一次进行xid冻结的最大事务数。
autovacuum_multixact_freeze_max_age:400 million。离下一次进行xid冻结的最大事务数。
autovacuum_vacuum_cost_delay :如果为-1,取vacuum_cost_delay值。
autovacuum_vacuum_cost_limit:如果为-1,到vacuum_cost_limit的值,这个值是所有worker的累加值。
PostgreSQL 配置参数修改
修改配置文件
在配置文件C:\PostgreSQL\data\pg96\postgresql.conf中直接修改,修改前记得备份一下原文件,因为你不知道意外和明天不知道哪个会先来。修改完成之后,记得重启数据库哦。
命令行的修改方式
ALTER SYSTEM SET configuration_parameter { TO | = } { value | 'value' | DEFAULT }例如:我们现在要修改 maintenance_work_mem。
-
--查看所有数据库参数的值 -
show all; -
show maintenance_work_mem; -
--注意这里的设置不会改变postgresql.conf,只会改变postgresql.conf -
ALTER SYSTEM SET maintenance_work_mem= 1048576; -
--重启数据库 -
show maintenance_work_mem; -
--取消postgresql.auto.conf的参数设置 -
ALTER SYSTEM SET maintenance_work_mem= default;
数据库参数优化总结
-
max_connections = 300 #(change requires restart) -
unix_socket_directories = '.' #comma-separated list of directories -
shared_buffers = 194GB #尽量用数据库管理内存,减少双重缓存,提高使用效率 -
huge_pages = on #on, off, or try,使用大页 -
work_mem = 256MB # min 64kB ,减少外部文件排序的可能,提高效率 -
maintenance_work_mem = 2GB #min 1MB,加速建立索引 -
autovacuum_work_mem = 2GB #min 1MB, or -1 to use maintenance_work_mem ,加速垃圾回收。 -
dynamic_shared_memory_type = mmap #the default is the first option -
vacuum_cost_delay = 0 #0-100 milliseconds,垃圾回收不妥协,极限压力下,减少膨胀可能性。 -
bgwriter_delay = 10ms #10-10000ms between rounds,刷shared buffer脏页的进程调度间隔,尽量高频调度,减少用户进程申请不到内存而需要主动刷脏页的可能(导致RT升高)。 -
bgwriter_lru_maxpages = 1000 #0-1000 max buffers written/round , 一次最多刷多少脏页。 -
bgwriter_lru_multiplier = 10.0 #0-10.0 multipler on buffers scanned/round 一次扫描多少个块,上次刷出脏页数量的倍数。 -
effective_io_concurrency = 2 #1-1000; 0 disables prefetching , 执行节点为bitmap heap scan时,预读的块数。 -
wal_level = minimal #minimal, archive, hot_standby, or logical , 如果现实环境,建议开启归档。 -
synchronous_commit = off #synchronization level; ,异步提交。 -
wal_sync_method = open_sync # the default is the first option ,因为没有standby,所以写xlog选择一个支持O_DIRECT的fsync方法。 -
full_page_writes = off # recover from partial page writes ,生产中,如果有增量备份和归档,可以关闭,提高性能。 -
wal_buffers = 1GB # min 32kB, -1 sets based on shared_buffers ,wal buffer大小,如果大量写wal buffer等待,则可以加大。 -
wal_writer_delay = 10ms #1-10000 milliseconds wal buffer调度间隔,和bg writer delay类似。 -
commit_delay = 20 #range 0-100000, in microseconds ,分组提交的等待时间。 -
commit_siblings = 9 #range 1-1000 , 有多少个事务同时进入提交阶段时,就触发分组提交。 -
checkpoint_timeout = 55min #range 30s-1h 时间控制的检查点间隔。 -
max_wal_size = 320GB #2个检查点之间最多允许产生多少个XLOG文件。 -
checkpoint_completion_target = 0.99 #checkpoint target duration, 0.0 - 1.0 ,平滑调度间隔,假设上一个检查点到现在这个检查点之间产生了100个XLOG,则这次检查点需要在产生100*checkpoint_completion_target个XLOG文件的过程中完成。PG会根据这些值来调度平滑检查点。 -
random_page_cost = 1.0 #same scale as above , 离散扫描的成本因子,本例使用的SSD IO能力足够好。 -
effective_cache_size = 240GB #可用的OS CACHE -
log_destination = 'csvlog' #Valid values are combinations of -
logging_collector = on #Enable capturing of stderr and csvlog -
log_truncate_on_rotation = on #If on, an existing log file with the -
update_process_title = off -
track_activities = off -
autovacuum = on #Enable autovacuum subprocess? 'on' -
autovacuum_max_workers = 4 #max number of autovacuum subprocesses ,允许同时有多少个垃圾回收工作进程。 -
autovacuum_naptime = 6s #time between autovacuum runs,自动垃圾回收探测进程的唤醒间隔。 -
autovacuum_vacuum_cost_delay = 0 #default vacuum cost delay for,垃圾回收不妥协。
PostgreSQL 服务器日志
开启审计日志
编辑 $PGDATA/postgresql.conf文件
-
vi $PGDATA/postgresql.conf -
# 做以下修改,下面2部分未提及的全部备注掉 -
# - Where to Log - -
log_destination = 'csvlog' # 日志输出格式 -
logging_collector = on # 日志收集器,打开后某些不会出现在审计日志中的日志会被重定向到审计日志 -
log_directory = 'pg_log' # 相对于 $PGDATA 的相对路径,全路径即为 $PGDATA/pg_log -
# 保留近7天的审计日志,轮询替换 -
log_filename = 'postgresql.%a' #日志名称 -
log_file_mode = 0600 # 只有postgres有读写权限 -
log_truncate_on_rotation = on # 覆盖同名日志 -
log_rotation_size = 0 # 不限制日志大小 -
log_min_messages = warning # 控制哪些消息级别被写入到审计日志 -
log_min_error_statement = error # 控制哪些导致一个错误情况的 SQL 语句被记录在服务器日志中 -
log_min_duration_statement = 0 # 记录所有sql运行时长,可以查慢sql -
# - What to Log - -
log_duration = on # 导致每一个完成的语句的持续时间被记录 -
log_lock_waits = on # 等锁超时记录日志,超时时间参数 deadlock_timeout -
log_statement = 'mod' # mod记录所有ddl语句,外加数据修改语句例如INSERT, UPDATE、DELETE、TRUNCATE, 和COPY FROM -
log_replication_commands = off # 不记录流复制命令 -
log_timezone = 'Asia/Shanghai' # 时区,查看操作系统时区 timedatectl | grep "Time zone"
重启数据库
pg_ctl restart -mf更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
sql直接读取日志
安装 file_fdw 插件
create extension file_fdw;创建外部表
-
drop foreign table if exists pg_log_mon; -
create foreign table pg_log_mon( -
log_time timestamp -
,user_name text -
,database_name text -
,process_id integer -
,connection_from text -
,session_id text -
,session_line_num bigint -
,command_tag text -
,session_start_time timestamp -
,virtual_transaction_id text -
,transaction_id bigint -
,error_severity text -
,sql_state_code text -
,message text -
,detail text -
,hint text -
,internal_query text -
,internal_query_pos integer -
,context text -
,query text -
,query_pos integer -
,location text -
,application_name text -
) server pg_file_server options( -
filename '/data/pgdata/pg_log/postgresql.Mon.csv' -
,format 'csv' -
,header 'false' -
,delimiter ',' -
,quote '"' -
,escape '"' -
); -
comment on foreign table pg_log_mon is '每周一当天审计日志'; -
comment on column pg_log_mon.log_time is '日志时间'; -
comment on column pg_log_mon.user_name is '用户名'; -
comment on column pg_log_mon.database_name is '数据库名'; -
comment on column pg_log_mon.process_id is '进程id'; -
comment on column pg_log_mon.connection_from is '客户端ip:端口'; -
comment on column pg_log_mon.session_id is '会话id'; -
comment on column pg_log_mon.session_line_num is '当前会话的第几次查询'; -
comment on column pg_log_mon.command_tag is '命令类型'; -
comment on column pg_log_mon.session_start_time is '会话开始时间'; -
comment on column pg_log_mon.virtual_transaction_id is '虚拟事务id'; -
comment on column pg_log_mon.transaction_id is '事务id'; -
comment on column pg_log_mon.error_severity is '错误级别'; -
comment on column pg_log_mon.sql_state_code is 'sql状态代码'; -
comment on column pg_log_mon.message is '信息'; -
comment on column pg_log_mon.detail is '详细信息'; -
comment on column pg_log_mon.hint is '提示信息'; -
comment on column pg_log_mon.query is '查询的sql'; -
comment on column pg_log_mon.application_name is '应用名(客户端名)'; -
drop foreign table if exists pg_log_tue; -
create foreign table pg_log_tue( -
log_time timestamp -
,user_name text -
,database_name text -
,process_id integer -
,connection_from text -
,session_id text -
,session_line_num bigint -
,command_tag text -
,session_start_time timestamp -
,virtual_transaction_id text -
,transaction_id bigint -
,error_severity text -
,sql_state_code text -
,message text -
,detail text -
,hint text -
,internal_query text -
,internal_query_pos integer -
,context text -
,query text -
,query_pos integer -
,location text -
,application_name text -
) server pg_file_server options( -
filename '/data/pgdata/pg_log/postgresql.Tue.csv' -
,format 'csv' -
,header 'false' -
,delimiter ',' -
,quote '"' -
,escape '"' -
); -
comment on foreign table pg_log_tue is '每周二当天审计日志'; -
comment on column pg_log_tue.log_time is '日志时间'; -
comment on column pg_log_tue.user_name is '用户名'; -
comment on column pg_log_tue.database_name is '数据库名'; -
comment on column pg_log_tue.process_id is '进程id'; -
comment on column pg_log_tue.connection_from is '客户端ip:端口'; -
comment on column pg_log_tue.session_id is '会话id'; -
comment on column pg_log_tue.session_line_num is '当前会话的第几次查询'; -
comment on column pg_log_tue.command_tag is '命令类型'; -
comment on column pg_log_tue.session_start_time is '会话开始时间'; -
comment on column pg_log_tue.virtual_transaction_id is '虚拟事务id'; -
comment on column pg_log_tue.transaction_id is '事务id'; -
comment on column pg_log_tue.error_severity is '错误级别'; -
comment on column pg_log_tue.sql_state_code is 'sql状态代码'; -
comment on column pg_log_tue.message is '信息'; -
comment on column pg_log_tue.detail is '详细信息'; -
comment on column pg_log_tue.hint is '提示信息'; -
comment on column pg_log_tue.query is '查询的sql'; -
comment on column pg_log_tue.application_name is '应用名(客户端名)'; -
drop foreign table if exists pg_log_wed; -
create foreign table pg_log_wed( -
log_time timestamp -
,user_name text -
,database_name text -
,process_id integer -
,connection_from text -
,session_id text -
,session_line_num bigint -
,command_tag text -
,session_start_time timestamp -
,virtual_transaction_id text -
,transaction_id bigint -
,error_severity text -
,sql_state_code text -
,message text -
,detail text -
,hint text -
,internal_query text -
,internal_query_pos integer -
,context text -
,query text -
,query_pos integer -
,location text -
,application_name text -
) server pg_file_server options( -
filename '/data/pgdata/pg_log/postgresql.Wed.csv' -
,format 'csv' -
,header 'false' -
,delimiter ',' -
,quote '"' -
,escape '"' -
); -
comment on foreign table pg_log_wed is '每周三当天审计日志'; -
comment on column pg_log_wed.log_time is '日志时间'; -
comment on column pg_log_wed.user_name is '用户名'; -
comment on column pg_log_wed.database_name is '数据库名'; -
comment on column pg_log_wed.process_id is '进程id'; -
comment on column pg_log_wed.connection_from is '客户端ip:端口'; -
comment on column pg_log_wed.session_id is '会话id'; -
comment on column pg_log_wed.session_line_num is '当前会话的第几次查询'; -
comment on column pg_log_wed.command_tag is '命令类型'; -
comment on column pg_log_wed.session_start_time is '会话开始时间'; -
comment on column pg_log_wed.virtual_transaction_id is '虚拟事务id'; -
comment on column pg_log_wed.transaction_id is '事务id'; -
comment on column pg_log_wed.error_severity is '错误级别'; -
comment on column pg_log_wed.sql_state_code is 'sql状态代码'; -
comment on column pg_log_wed.message is '信息'; -
comment on column pg_log_wed.detail is '详细信息'; -
comment on column pg_log_wed.hint is '提示信息'; -
comment on column pg_log_wed.query is '查询的sql'; -
comment on column pg_log_wed.application_name is '应用名(客户端名)'; -
drop foreign table if exists pg_log_thu; -
create foreign table pg_log_thu( -
log_time timestamp -
,user_name text -
,database_name text -
,process_id integer -
,connection_from text -
,session_id text -
,session_line_num bigint -
,command_tag text -
,session_start_time timestamp -
,virtual_transaction_id text -
,transaction_id bigint -
,error_severity text -
,sql_state_code text -
,message text -
,detail text -
,hint text -
,internal_query text -
,internal_query_pos integer -
,context text -
,query text -
,query_pos integer -
,location text -
,application_name text -
) server pg_file_server options( -
filename '/data/pgdata/pg_log/postgresql.Thu.csv' -
,format 'csv' -
,header 'false' -
,delimiter ',' -
,quote '"' -
,escape '"' -
); -
comment on foreign table pg_log_thu is '每周四当天审计日志'; -
comment on column pg_log_thu.log_time is '日志时间'; -
comment on column pg_log_thu.user_name is '用户名'; -
comment on column pg_log_thu.database_name is '数据库名'; -
comment on column pg_log_thu.process_id is '进程id'; -
comment on column pg_log_thu.connection_from is '客户端ip:端口'; -
comment on column pg_log_thu.session_id is '会话id'; -
comment on column pg_log_thu.session_line_num is '当前会话的第几次查询'; -
comment on column pg_log_thu.command_tag is '命令类型'; -
comment on column pg_log_thu.session_start_time is '会话开始时间'; -
comment on column pg_log_thu.virtual_transaction_id is '虚拟事务id'; -
comment on column pg_log_thu.transaction_id is '事务id'; -
comment on column pg_log_thu.error_severity is '错误级别'; -
comment on column pg_log_thu.sql_state_code is 'sql状态代码'; -
comment on column pg_log_thu.message is '信息'; -
comment on column pg_log_thu.detail is '详细信息'; -
comment on column pg_log_thu.hint is '提示信息'; -
comment on column pg_log_thu.query is '查询的sql'; -
comment on column pg_log_thu.application_name is '应用名(客户端名)'; -
drop foreign table if exists pg_log_fri; -
create foreign table pg_log_fri( -
log_time timestamp -
,user_name text -
,database_name text -
,process_id integer -
,connection_from text -
,session_id text -
,session_line_num bigint -
,command_tag text -
,session_start_time timestamp -
,virtual_transaction_id text -
,transaction_id bigint -
,error_severity text -
,sql_state_code text -
,message text -
,detail text -
,hint text -
,internal_query text -
,internal_query_pos integer -
,context text -
,query text -
,query_pos integer -
,location text -
,application_name text -
) server pg_file_server options( -
filename '/data/pgdata/pg_log/postgresql.Fri.csv' -
,format 'csv' -
,header 'false' -
,delimiter ',' -
,quote '"' -
,escape '"' -
); -
comment on foreign table pg_log_fri is '每周五当天审计日志'; -
comment on column pg_log_fri.log_time is '日志时间'; -
comment on column pg_log_fri.user_name is '用户名'; -
comment on column pg_log_fri.database_name is '数据库名'; -
comment on column pg_log_fri.process_id is '进程id'; -
comment on column pg_log_fri.connection_from is '客户端ip:端口'; -
comment on column pg_log_fri.session_id is '会话id'; -
comment on column pg_log_fri.session_line_num is '当前会话的第几次查询'; -
comment on column pg_log_fri.command_tag is '命令类型'; -
comment on column pg_log_fri.session_start_time is '会话开始时间'; -
comment on column pg_log_fri.virtual_transaction_id is '虚拟事务id'; -
comment on column pg_log_fri.transaction_id is '事务id'; -
comment on column pg_log_fri.error_severity is '错误级别'; -
comment on column pg_log_fri.sql_state_code is 'sql状态代码'; -
comment on column pg_log_fri.message is '信息'; -
comment on column pg_log_fri.detail is '详细信息'; -
comment on column pg_log_fri.hint is '提示信息'; -
comment on column pg_log_fri.query is '查询的sql'; -
comment on column pg_log_fri.application_name is '应用名(客户端名)'; -
drop foreign table if exists pg_log_sat; -
create foreign table pg_log_sat( -
log_time timestamp -
,user_name text -
,database_name text -
,process_id integer -
,connection_from text -
,session_id text -
,session_line_num bigint -
,command_tag text -
,session_start_time timestamp -
,virtual_transaction_id text -
,transaction_id bigint -
,error_severity text -
,sql_state_code text -
,message text -
,detail text -
,hint text -
,internal_query text -
,internal_query_pos integer -
,context text -
,query text -
,query_pos integer -
,location text -
,application_name text -
) server pg_file_server options( -
filename '/data/pgdata/pg_log/postgresql.Sat.csv' -
,format 'csv' -
,header 'false' -
,delimiter ',' -
,quote '"' -
,escape '"' -
); -
comment on foreign table pg_log_sat is '每周六当天审计日志'; -
comment on column pg_log_sat.log_time is '日志时间'; -
comment on column pg_log_sat.user_name is '用户名'; -
comment on column pg_log_sat.database_name is '数据库名'; -
comment on column pg_log_sat.process_id is '进程id'; -
comment on column pg_log_sat.connection_from is '客户端ip:端口'; -
comment on column pg_log_sat.session_id is '会话id'; -
comment on column pg_log_sat.session_line_num is '当前会话的第几次查询'; -
comment on column pg_log_sat.command_tag is '命令类型'; -
comment on column pg_log_sat.session_start_time is '会话开始时间'; -
comment on column pg_log_sat.virtual_transaction_id is '虚拟事务id'; -
comment on column pg_log_sat.transaction_id is '事务id'; -
comment on column pg_log_sat.error_severity is '错误级别'; -
comment on column pg_log_sat.sql_state_code is 'sql状态代码'; -
comment on column pg_log_sat.message is '信息'; -
comment on column pg_log_sat.detail is '详细信息'; -
comment on column pg_log_sat.hint is '提示信息'; -
comment on column pg_log_sat.query is '查询的sql'; -
comment on column pg_log_sat.application_name is '应用名(客户端名)'; -
drop foreign table if exists pg_log_sun; -
create foreign table pg_log_sun( -
log_time timestamp -
,user_name text -
,database_name text -
,process_id integer -
,connection_from text -
,session_id text -
,session_line_num bigint -
,command_tag text -
,session_start_time timestamp -
,virtual_transaction_id text -
,transaction_id bigint -
,error_severity text -
,sql_state_code text -
,message text -
,detail text -
,hint text -
,internal_query text -
,internal_query_pos integer -
,context text -
,query text -
,query_pos integer -
,location text -
,application_name text -
) server pg_file_server options( -
filename '/data/pgdata/pg_log/postgresql.Sun.csv' -
,format 'csv' -
,header 'false' -
,delimiter ',' -
,quote '"' -
,escape '"' -
); -
comment on foreign table pg_log_sun is '每周日当天审计日志'; -
comment on column pg_log_sun.log_time is '日志时间'; -
comment on column pg_log_sun.user_name is '用户名'; -
comment on column pg_log_sun.database_name is '数据库名'; -
comment on column pg_log_sun.process_id is '进程id'; -
comment on column pg_log_sun.connection_from is '客户端ip:端口'; -
comment on column pg_log_sun.session_id is '会话id'; -
comment on column pg_log_sun.session_line_num is '当前会话的第几次查询'; -
comment on column pg_log_sun.command_tag is '命令类型'; -
comment on column pg_log_sun.session_start_time is '会话开始时间'; -
comment on column pg_log_sun.virtual_transaction_id is '虚拟事务id'; -
comment on column pg_log_sun.transaction_id is '事务id'; -
comment on column pg_log_sun.error_severity is '错误级别'; -
comment on column pg_log_sun.sql_state_code is 'sql状态代码'; -
comment on column pg_log_sun.message is '信息'; -
comment on column pg_log_sun.detail is '详细信息'; -
comment on column pg_log_sun.hint is '提示信息'; -
comment on column pg_log_sun.query is '查询的sql'; -
comment on column pg_log_sun.application_name is '应用名(客户端名)'; -
create or replace view pg_log as -
select * from pg_log_mon -
union all -
select * from pg_log_tue -
union all -
select * from pg_log_wed -
union all -
select * from pg_log_thu -
union all -
select * from pg_log_fri -
union all -
select * from pg_log_sat -
union all -
select * from pg_log_sun;
更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
备份策略
每天00:30备份前一天的审计日志
shell脚本实现备份
-
#! /bin/bash -
#备份日期默认昨天,也是备份日期上限 -
BAKUP_DATE_UPPER=`date '+%Y%m%d' -d '-1 day'` -
BAKUP_DATE_FLOOR=`date '+%Y%m%d' -d '-6 day'` -
BAKUP_DATE=${BAKUP_DATE_UPPER} -
showuseage() { -
echo "程序功能:在数据库中备份昨天的pg审计日志 -
Useage: [backup_pglog -h 20220830] -
-h [:可选,指定备份日期,可选范围${BAKUP_DATE_FLOOR}-${BAKUP_DATE_UPPER},其他默认昨天]" -
} -
# /home/postgres/backup_pglog.sh -
# 每天备份昨天的数据 -
while getopts h: OPTS; do -
case "$OPTS" in -
h) -
if [ $OPTARG -ge ${BAKUP_DATE_FLOOR} -a $OPTARG -le ${BAKUP_DATE_UPPER} ]; then -
BAKUP_DATE=$OPTARG -
fi -
;; -
:) -
echo "$0 必须为 -$OPTARG 添加一个参数!" -
exit 1 -
;; -
?) -
showuseage -
exit 1 -
;; -
esac -
done -
BAKUP_SQL=" -
create table if not exists pg_log_:bak_log_span as -
select -
:today::varchar(8) as bak_date -
,* -
from pg_log -
where 1 = 2 -
; -
delete from pg_log_:bak_log_span where to_char(log_time,'yyyymmdd')::numeric = ${BAKUP_DATE} -
; -
insert into pg_log_:bak_log_span -
select :today::varchar as bak_date ,* -
from pg_log -
where to_char(log_time,'yyyymmdd')::numeric = ${BAKUP_DATE} -
; -
" -
echo `date '+%Y-%m-%d %H:%m:%S'`"|INFO|备份数据日期:${BAKUP_DATE}" -
echo `date '+%Y-%m-%d %H:%m:%S'`"|INFO|审计日志备份开始" -
BAKUP_SQL_EXEC_DATE=`date '+%Y%m%d%H%m%S'` -
psql <<EOF > /tmp/bakup_sql_exec_${BAKUP_SQL_EXEC_DATE}.log 2>&1 -
\i ~/var/${BAKUP_DATE}.sql -
${BAKUP_SQL} -
\q -
EOF -
EXECLOG=`cat /tmp/bakup_sql_exec_${BAKUP_SQL_EXEC_DATE}.log` -
rm -f /tmp/bakup_sql_exec_${BAKUP_SQL_EXEC_DATE}.log -
echo `date '+%Y-%m-%d %H:%m:%S'`"|INFO|审计日志备份结束" -
# 错误 -
ERRORNUM=`echo "${EXECLOG}" | grep -i 'ERROR' | wc -l` -
if [ ${ERRORNUM} -eq 0 ] -
then -
# 发短信通知备份成功 -
echo `date '+%Y-%m-%d %H:%m:%S'`"|INFO|审计日志备份成功" -
exit 0 -
else -
# 发短信通知备份失败 -
echo "请及时重新执行备份脚本进行备份" | mail -s "审计日志备份失败" 1445471277@qq.com -
echo `date '+%Y-%m-%d %H:%m:%S'`"|ERROR|审计日志备份失败" -
exit 1 -
fi
-
chmod +x /home/postgres/backup_pglog.sh -
crontab -e -
30 0 * * * . /home/postgres/backup_pglog.sh >> /home/postgres/backup_pglog.log 2>&1
格式符说明
-
%a #星期的英文单词的缩写:如星期一, 则返回 Mon -
%A #星期的英文单词的全拼:如星期一,返回 Monday -
%b #月份的英文单词的缩写:如一月, 则返回 Jan -
%B #月份的引文单词的缩写:如一月, 则返回 January -
%c #返回datetime的字符串表示,如03/08/15 23:01:26 -
%d #返回的是当前时间是当前月的第几天 -
%f #微秒的表示: 范围: [0,999999] -
%H #以24小时制表示当前小时 -
%I #以12小时制表示当前小时 -
%j #返回 当天是当年的第几天 范围[001,366] -
%m #返回月份 范围[0,12] -
%M #返回分钟数 范围 [0,59] -
%P #返回是上午还是下午–AM or PM -
%S #返回秒数 范围 [0,61]。。。手册说明的 -
%U #返回当周是当年的第几周 以周日为第一天 -
%W #返回当周是当年的第几周 以周一为第一天 -
%w #当天在当周的天数,范围为[0, 6],6表示星期天 -
%x #日期的字符串表示 :03/08/15 -
%X #时间的字符串表示 :23:22:08 -
%y #两个数字表示的年份 15 -
%Y #四个数字表示的年份 2015 -
%z #与utc时间的间隔 (如果是本地时间,返回空字符串) -
%Z #时区名称(如果是本地时间,返回空字符串)
![]()
消息严重级别

更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
Postgresql 数据库巡检
主机信息
CPU
-
mpstat | sed -n '3,$p' | awk -F' ' '{print $13}' -
echo 'CPU CORE' && cat /proc/cpuinfo|grep processor|wc -l
-
正常:空闲cpu大于20%;
-
异常处理:排查问题,杀掉cpu高进程,top 按c;
检查内存
free -m-
正常:空闲内存大于30%;
-
异常处理:排查问题,杀掉内存高进程,top 按c;
检查磁盘空间
df -lh-
正常:磁盘空间已用空间小于70%;
-
异常处理:增加硬盘或者删除无用的数据;
检查IO
iostat -x | sed -n '6,$p' | awk -F' ' '{print $1,$13,$14}'-
正常:磁盘空间已用空间小于70%;
-
异常处理:增加硬盘或者删除无用的数据;
检查端口
netstat -tanp | grep 'LISTEN' | grep '5432'-
正常:tcp4和tcp6正常监听;
-
异常处理:排查数据库是否正常启动,排查数据库配置文件的端口参数是否为5432;
检查postgres进程
ps -ef | grep "checkpointer|background writer|walwriter|autovacuum launcher|archiver|stats collector|logical replication launcher|logger" | grep -v grep-
正常:进程都在;
-
异常处理:重启数据库;
数据库
检查安装信息
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,to_char(pg_postmaster_start_time(),'yyyy-mm-dd hh24:mi:ss') "pg_start_time(启动时间)" -
,now()-pg_postmaster_start_time() "pg_running_time(运行时长)" -
--,inet_server_addr() "server_ip(服务器ip)" -
--,inet_server_port() "server_port(服务器端口)" -
--,inet_client_addr() "client_ip(客户端ip)" -
--,inet_client_port() "client_port(客户端端口)" -
,version() "server_version(数据库版本)" -
,(case when pg_is_in_recovery()='f' then 'primary' else 'standby' end ) as "primary_or_standby(主或备)" -
;
-
正常:数据库正常使用;
-
异常处理:重装数据库;
检查postgresql.conf文件
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,sourceline "sourceline(行号)" -
,name "para(参数名)" -
,setting "value(参数值)" -
from pg_file_settings -
order by "sourceline(行号)";
-
正常:各项参数设置适合;
-
异常处理:编辑postgresql.conf文件,修改参数后重启数据库;
-
vi $PGDATA/postgresql.conf -
pg_ctl restart -mf
检查pg_hba.conf文件
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,line_number "line_number(行号)" -
,type "type(连接类型)" -
,database "database(数据库名)" -
,user_name "user_name(用户名)" -
,address "address(ip地址)" -
,netmask "netmask(子网掩码)" -
,auth_method "auth_method(认证方式)" -
from pg_hba_file_rules -
order by "line_number(行号)";
-
正常:非套接字连接都需要md5认证;
-
异常处理:编辑pg_hba.conf文件,修改参数后重新加载数据库;
-
vi $PGDATA/postgresql.conf -
pg_ctl reload
检查数据库重要配置
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,name -
,setting -
from -
pg_settings a -
where a.name in ( -
'data_directory', -
'port', -
'client_encoding', -
'config_file', -
'hba_file', -
'ident_file', -
'archive_mode', -
'logging_collector', -
'log_directory', -
'log_filename', -
'log_truncate_on_rotation', -
'log_statement', -
'log_min_duration_statement', -
'max_connections', -
'listen_addresses' -
) -
order by name;
-
正常:各项配置都适合;
-
异常处理:修改不合适的配置;
检查主从WAl状态
-
主
-
select -
-- pid "pid(进程id)" -
--,usename "username(用户名)" -
--,application_name "application_name(应用名)" -
--,client_addr "client_addr(IP)" -
--,backend_start "backend_start(备份开始时间)" -
state "state(WAL发送状态编码)" -
-- ,case -
-- when state = 'startup' then '正在启动' -
-- when state = 'catchup' then '追赶主库' -
-- when state = 'streaming' then '流传送' -
-- when state = 'backup' then '发送备份' -
-- when state = 'stopping' then '发送停止' -
-- end "statename(WAL状态)" -
,sync_state "sync_state(同步状态编码)" -
-- ,case -
-- when sync_state = 'async' then '异步' -
-- when sync_state = 'potential' then '后备失效变同步' -
-- when sync_state = 'sync' then '同步' -
-- when sync_state = 'quorum' then '候选' -
-- end "sync_statename(同步状态名称)" -
--,round(pg_wal_lsn_diff(pg_current_wal_lsn(),replay_lsn) /(1024 * 1024),2) as "slave_latency_mb(同步延迟_MB)" -
from pg_stat_replication;
-
从
-
select -
-- pid "pid(进程id)" -
status "status(WAl接收状态)" -
,'async' "sync_state(同步状态编码)" -
--,last_msg_send_time "last_msg_send_time(接收到最后的消息发送时间)" -
--,last_msg_receipt_time "last_msg_receipt_time(接收到最后的消息接收时间)" -
--,sender_host "sender_host(主库IP)" -
from pg_stat_wal_receiver -
;
更多关于 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
检查表空间
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,spcname AS "Name(名称)" -
,pg_catalog.pg_get_userbyid(spcowner) AS "Owner(拥有者)" -
--,pg_catalog.pg_tablespace_location(oid) AS "Location(数据文件目录)" -
--,pg_catalog.array_to_string(spcacl, E'\n') AS "Access privileges(访问权限)" -
--,spcoptions AS "Options(参数)" -
,pg_catalog.pg_size_pretty(pg_catalog.pg_tablespace_size(oid)) AS "Size(表空间大小)" -
--,pg_catalog.shobj_description(oid, 'pg_tablespace') AS "Description(备注)" -
from pg_catalog.pg_tablespace -
order by 1;
检查连接数
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,max_conn "max_conn(最大连接数)" -
,now_conn "now_conn(当前连接数)" -
,max_conn - now_conn "remain_conn(剩余连接数)" -
from ( -
select -
setting::int8 as max_conn -
,(select count(*) from pg_stat_activity ) as now_conn -
from pg_settings -
where name = 'max_connections' -
) a -
;
-
正常:连接数不超过总连接数的90%;
-
异常处理:超级用户(postgres)杀连接;
-
--杀掉所有空闲连接 -
select pg_terminate_backend(pid) from pg_stat_activity WHERE state = 'idle';
检查锁表
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,relname "relname(表名)" -
,b.nspname "shemaname(模式名)" -
,c.rolname "user(用户名)" -
,d.locktype "locktype(被锁对象类型)" -
,d.mode "mode(锁类型)" -
,d.pid "pid(进程id)" -
,e.query "query(锁表sql)" -
,current_timestamp-state_change "lock_duration(锁表时长)" -
from pg_class a -
inner join pg_namespace b -
on (a.relnamespace = b.oid) -
inner join pg_roles c -
on (a.relowner = c.oid) -
inner join pg_locks d -
on (a.oid = d.relation) -
left join pg_stat_activity e -
on (d.pid = e.pid) -
where d.mode = 'AccessExclusiveLock' -
order by "lock_duration(锁表时长)" desc;
-
正常:无锁表;
-
异常处理:取消该进程或杀掉该会话;
-
--取消该进程 -
select pg_cancel_backend(pid); -
--杀掉该会话 -
select pg_terminate_backend(pid);
检查空闲连接top5
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,a.datname "datname(数据库名)" -
,a.pid "pid(进程id)" -
,b.rolname "username(用户名)" -
--,a.application_name "app_name(应用名称)" -
,a.client_addr "client_ip(客户端ip)" -
--,a.query_start "query_start(当前查询开始时间)" -
,to_char(a.state_change,'yyyy-mm-dd hh24:mi:ss') "state_change(状态变化时间)" -
--,a.state "state(状态)" -
--,a.query "sql(执行的sql)" -
--,a.backend_type "backend_type(后端类型)" -
from pg_stat_activity a -
inner join pg_roles b -
on (a.usesysid = b.oid) -
where a.state = 'idle' -
and state_change < current_timestamp - interval '30 min' -
order by current_timestamp-state_change desc -
limit 5 -
;
-
正常:超半小时空闲的连接;
-
异常处理:杀连接;
select pg_terminate_backend(pid);检查长事务top5
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,a.datname "datname(数据库名)" -
,a.pid "pid(进程id)" -
,b.rolname "username(用户名)" -
--,a.application_name "app_name(应用名称)" -
,a.client_addr "client_ip(客户端ip)" -
--,a.xact_start "xact_start(当前事务开始时间)" -
--,a.query_start "query_start(当前查询开始时间)" -
,to_char(a.state_change,'yyyy-mm-dd hh24:mi:ss') "state_change(状态变化时间)" -
--,a.state "state(状态)" -
--,a.query "sql(执行的sql)" -
--,a.backend_type "backend_type(后端类型)" -
from pg_stat_activity a -
inner join pg_roles b -
on (a.usesysid = b.oid) -
where a.state in ('idle in transaction','idle in transaction (aborted)') -
and state_change < current_timestamp - interval '30 min' -
order by current_timestamp-state_change desc -
limit 5;
-
正常:不存在长事务;
-
异常处理:杀会话;
select pg_terminate_backend(pid);检查慢SQLtop5
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,a.datname "datname(数据库名)" -
,a.pid "pid(进程id)" -
,b.rolname "username(用户名)" -
--,a.application_name "app_name(应用名称)" -
,a.client_addr "client_ip(客户端ip)" -
--,a.query_start "query_start(当前查询开始时间)" -
,to_char(a.state_change,'yyyy-mm-dd hh24:mi:ss') "state_change(状态变化时间)" -
--,a.wait_event_type "wait_event_type(等待类型)" -
--,a.wait_event "wait_event(等待事件)" -
--,a.state "state(状态)" -
--,a.query "sql(执行的sql)" -
--,a.backend_type "backend_type(后端类型)" -
from pg_stat_activity a -
left join pg_roles b -
on (a.usesysid = b.oid) -
where a.state = 'active' -
and state_change < current_timestamp - interval '1 hour' -
and a.datname is not null -
order by current_timestamp-state_change desc -
limit 5;
![]()
-
正常:不存在慢sql;
-
异常处理:分析原因,有针对性地杀连接;
select pg_terminate_backend(pid);检查对象数
-
--这里需要循环查每个库所有数据然后合并 -
select to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,current_database() -
,sum(obj_num) "obj_num(对象数)" -
from ( -
select count(1) obj_num from pg_class -
union all -
select count(1) from pg_proc -
) a -
;
-
正常:总对象数不超过5万;
-
异常处理:删除无用的对象;
检查表膨胀top5
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间" -
,current_database() current_database -
,relname as "table_name(表名)" -
,schemaname as "schema_name(模式名)" -
,pg_size_pretty(pg_relation_size('"'||schemaname|| '"."'||relname||'"')) as "table_size(表大小)" -
,n_dead_tup as "n_dead_tup(无效记录数)" -
,n_live_tup as "n_live_tup(有效记录数)" -
,to_char(round(n_dead_tup*1.0/(n_live_tup+n_dead_tup)*100,2),'fm990.00') as "dead_rate(无效记录比例%)" -
from -
pg_stat_all_tables -
where n_live_tup+n_dead_tup <> 0 -
;
-
正常:不存在表膨胀,因为有自动清理垃圾进程;
-
异常处理:对膨胀表做vacuum analyze操作;
检查索引膨胀
-
select -
to_char(now(),'yyyy-mm-dd hh24:mi:ss') "巡检时间", -
current_database() AS db, schemaname, tablename,bs, reltuples::bigint AS tups, relpages::bigint AS pages, otta, -
ROUND(CASE WHEN otta=0 OR sml.relpages=0 OR sml.relpages=otta THEN 0.0 ELSE sml.relpages/otta::numeric END,1) AS tbloat, -
CASE WHEN relpages < otta THEN 0 ELSE relpages::bigint - otta END AS wastedpages, -
CASE WHEN relpages < otta THEN 0 ELSE bs*(sml.relpages-otta)::bigint END AS wastedbytes, -
CASE WHEN relpages < otta THEN $$0 bytes$$::text ELSE (bs*(relpages-otta))::bigint || $$ bytes$$ END AS wastedsize, -
iname, ituples::bigint AS itups, ipages::bigint AS ipages, iotta, -
ROUND(CASE WHEN iotta=0 OR ipages=0 OR ipages=iotta THEN 0.0 ELSE ipages/iotta::numeric END,1) AS ibloat, -
CASE WHEN ipages < iotta THEN 0 ELSE ipages::bigint - iotta END AS wastedipages, -
CASE WHEN ipages < iotta THEN 0 ELSE bs*(ipages-iotta) END AS wastedibytes, -
CASE WHEN ipages < iotta THEN $$0 bytes$$ ELSE (bs*(ipages-iotta))::bigint || $$ bytes$$ END AS wastedisize, -
CASE WHEN relpages < otta THEN -
CASE WHEN ipages < iotta THEN 0 ELSE bs*(ipages-iotta::bigint) END -
ELSE CASE WHEN ipages < iotta THEN bs*(relpages-otta::bigint) -
ELSE bs*(relpages-otta::bigint + ipages-iotta::bigint) END -
END AS totalwastedbytes -
FROM ( -
SELECT -
nn.nspname AS schemaname, -
cc.relname AS tablename, -
COALESCE(cc.reltuples,0) AS reltuples, -
COALESCE(cc.relpages,0) AS relpages, -
COALESCE(bs,0) AS bs, -
COALESCE(CEIL((cc.reltuples*((datahdr+ma- -
(CASE WHEN datahdr%ma=0 THEN ma ELSE datahdr%ma END))+nullhdr2+4))/(bs-20::float)),0) AS otta, -
COALESCE(c2.relname,$$?$$) AS iname, COALESCE(c2.reltuples,0) AS ituples, COALESCE(c2.relpages,0) AS ipages, -
COALESCE(CEIL((c2.reltuples*(datahdr-12))/(bs-20::float)),0) AS iotta -- very rough approximation, assumes all cols -
FROM -
pg_class cc -
JOIN pg_namespace nn ON cc.relnamespace = nn.oid AND nn.nspname <> $$information_schema$$ -
LEFT JOIN -
( -
SELECT -
ma,bs,foo.nspname,foo.relname, -
(datawidth+(hdr+ma-(case when hdr%ma=0 THEN ma ELSE hdr%ma END)))::numeric AS datahdr, -
(maxfracsum*(nullhdr+ma-(case when nullhdr%ma=0 THEN ma ELSE nullhdr%ma END))) AS nullhdr2 -
FROM ( -
SELECT -
ns.nspname, tbl.relname, hdr, ma, bs, -
SUM((1-coalesce(null_frac,0))*coalesce(avg_width, 2048)) AS datawidth, -
MAX(coalesce(null_frac,0)) AS maxfracsum, -
hdr+( -
SELECT 1+count(*)/8 -
FROM pg_stats s2 -
WHERE null_frac<>0 AND s2.schemaname = ns.nspname AND s2.tablename = tbl.relname -
) AS nullhdr -
FROM pg_attribute att -
JOIN pg_class tbl ON att.attrelid = tbl.oid -
JOIN pg_namespace ns ON ns.oid = tbl.relnamespace -
LEFT JOIN pg_stats s ON s.schemaname=ns.nspname -
AND s.tablename = tbl.relname -
AND s.inherited=false -
AND s.attname=att.attname, -
( -
SELECT -
(SELECT current_setting($$block_size$$)::numeric) AS bs, -
CASE WHEN SUBSTRING(SPLIT_PART(v, $$ $$, 2) FROM $$#"[0-9]+.[0-9]+#"%$$ for $$#$$) -
IN ($$8.0$$,$$8.1$$,$$8.2$$) THEN 27 ELSE 23 END AS hdr, -
CASE WHEN v ~ $$mingw32$$ OR v ~ $$64-bit$$ THEN 8 ELSE 4 END AS ma -
FROM (SELECT version() AS v) AS foo -
) AS constants -
WHERE att.attnum > 0 AND tbl.relkind=$$r$$ -
GROUP BY 1,2,3,4,5 -
) AS foo -
) AS rs -
ON cc.relname = rs.relname AND nn.nspname = rs.nspname -
LEFT JOIN pg_index i ON indrelid = cc.oid -
LEFT JOIN pg_class c2 ON c2.oid = i.indexrelid -
) AS sml -
;
-
索引膨胀,依赖于统计信息,统计信息未更新,索引膨胀信息不准确。一般每年统一做一次重建索引即可。
-
异常处理:重建索引;
reindex index 索引名;














 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









