




大型语言模型(Large Language Models, LLMs)的崛起标志着人工智能从专用任务导向向通用认知智能的范式转移。本报告旨在为工程与研究人员提供一份详尽的技术路线图,涵盖从底层Transformer架构的数学原理到预训练、微调、对齐,直至现代检索增强生成(RAG)与智能体(Agent)系统的全生命周期。
我们将深入剖析注意力机制的梯度流向、参数高效微调(PEFT)的量化误差分析、基于人类反馈的强化学习(RLHF)与直接偏好优化(DPO)的博弈论本质,以及vLLM分页注意力机制对显存管理的革新。通过整合2025年的最新研究成果与开源模型基准,本报告将带领读者完成从模型使用者到架构设计者的认知跃迁。
1. 架构创世纪:从序列依赖到注意力机制
要彻底掌握大型语言模型,首先必须解构使其成为可能的架构革命。在2017年之前,自然语言处理(NLP)的主流范式长期被循环神经网络(RNN)及其变体长短期记忆网络(LSTM)所统治。这些架构的核心特征是顺序处理:模型在时刻 t t t 的计算严格依赖于时刻 t − 1 t-1 t−1 的隐藏状态 h _ t − 1 h\_{t-1} h_t−1 。这种顺序依赖性不仅阻碍了大规模并行计算——因为无法同时处理整个序列——而且在长序列中导致了信息的衰减,即所谓的“梯度消失”问题。尽管LSTM通过门控机制缓解了这一问题,但其本质上仍受限于将无限上下文压缩为固定大小向量的能力。

1.1 注意力机制的数学重构
《Attention Is All You Need》一文提出的Transformer架构,彻底摒弃了循环与卷积,完全依赖注意力机制来捕捉输入输出之间的全局依赖关系 。其核心创新在于自注意力(Self-Attention),它允许模型在处理序列中的每个位置时,都能“关注”并加权聚合序列中所有其他位置的信息。
从数学角度审视,缩放点积注意力(Scaled Dot-Product Attention)构成了现代LLM的原子单元。给定输入嵌入矩阵 X X X,我们通过三个可学习的线性投影矩阵 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV 将其映射为查询(Query)、键(Key)和值(Value)矩阵 2:
Q = X W Q , K = X W K , V = X W V Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV
注意力权重的计算公式如下:
Attention ( Q , K , V ) = softmax ( Q K T d _ k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d\_k}}\right)V Attention(Q,K,V)=softmax(d_kQKT)V
在此公式中, Q K T QK^T QKT 计算了查询与键之间的相似度分数。对于初学者而言,除以 d _ k \sqrt{d\_k} d_k(缩放因子)这一步常被忽视,但它对训练稳定性至关重要。当键向量的维度 d _ k d\_k d_k 较大时,点积结果的方差会显著增大,导致Softmax函数进入梯度极小的饱和区,从而阻碍反向传播中的梯度流动 4。缩放因子的引入有效地将点积结果归一化,维持了梯度的方差稳定。
1.2 多头注意力与子空间表征
单一的注意力头限制了模型关注不同位置的能力。现代LLM采用**多头注意力(Multi-Head Attention)**机制,将 d _ m o d e l d\_{model} d_model 维度的查询、键和值投影到 h h h 个不同的子空间中并行计算 6。
MultiHead ( Q , K , V ) = Concat ( head _ 1 , . . . , head _ h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}\_1,..., \text{head}\_h)W^O MultiHead(Q,K,V)=Concat(head_1,...,head_h)WO
这种设计的深层含义在于“表征解耦”。实证研究表明,不同的注意力头会分化出不同的功能关注点:某些头可能专注于语法结构(如主谓一致),而另一些头则可能捕捉语义关系(如代词与其先行词的指代关系)。最终的线性投影 W O W^O WO 将这些不同子空间的信息融合,形成丰富的上下文表征 2。
1.3 位置编码的演进:从绝对到相对
由于自注意力机制具有排列不变性(Permutation Invariant),即打乱输入序列的顺序不会改变 Q K T QK^T QKT的点积结果(仅改变输出行序),因此必须显式注入位置信息。
早期的Transformer使用固定的正弦/余弦函数作为绝对位置编码,将其直接加到输入嵌入上 。然而,绝对位置编码在处理超过训练长度的序列时表现不佳(外推性差)。
当前主流模型(如Llama 3, Mistral, Qwen)普遍采用旋转位置编码(Rotary Positional Embeddings, RoPE)。RoPE不直接叠加位置向量,而是通过将查询和键向量在复数域内进行旋转来编码相对位置信息 8。
( q ′ _ 0 q ′ _ 1 ) = ( cos m θ − sin m θ sin m θ cos m θ ) ( q _ 0 q _ 1 ) \begin{pmatrix} q'\_0 \\ q'\_1 \end{pmatrix} = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} q\_0 \\ q\_1 \end{pmatrix} (q′_0q′_1)=(cosmθsinmθ−sinmθcosmθ)(q_0q_1)
这种旋转操作使得两个标记之间的注意力分数仅依赖于它们的相对距离 ( m − n ) (m-n) (m−n),而非绝对位置。RoPE极大地增强了模型处理长上下文(Long Context)的能力,是现代LLM实现128k甚至1M上下文窗口的关键技术支柱 10。
2. 预训练工程:从数据清洗到算力优化
LLM的生命周期始于预训练,这是将通用世界知识注入参数矩阵的过程。此阶段占据了总算力预算的98%以上 12,其核心任务是因果语言建模(Causal Language Modeling),即基于前文预测下一个Token。
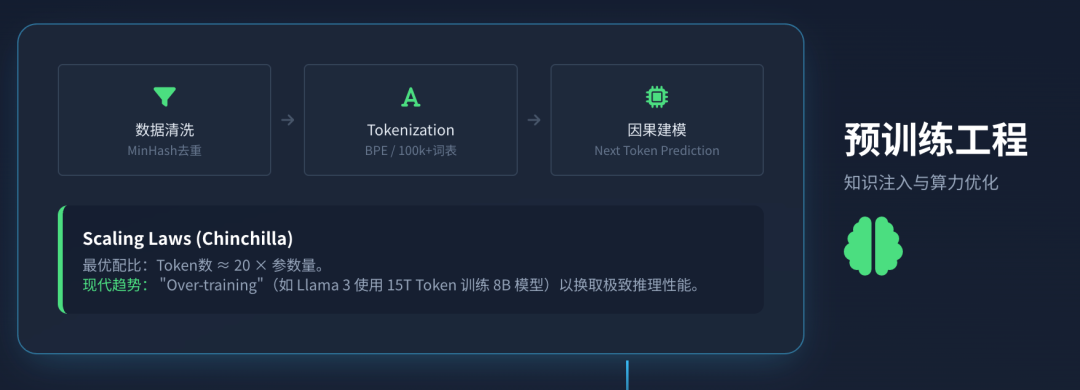
2.1 数据管线与Tokenization
模型性能的上限由数据质量决定。现代预训练数据管线涉及复杂的清洗流程:使用MinHash或SimHash算法进行大规模去重以防止模型记忆而非泛化;过滤低质量、有害或重复的文本;并混合多种数据源(网页、代码、书籍、论文)以平衡通用能力与推理能力 13。
分词(Tokenization)是将文本转化为数值序列的关键步骤。现代LLM普遍使用字节对编码(Byte-Pair Encoding, BPE)。BPE从字符级别开始,迭代合并频率最高的字节对,直到达到预设的词表大小(通常在32k到128k之间) 2。
- 压缩率与语义密度: 较大的词表(如Qwen的150k)可以实现更高的压缩率,使得单个Token承载更多的语义信息,从而在相同的上下文窗口内处理更长的文本,这对于多语言支持尤为重要。
- 字节级回退: 现代BPE实现在遇到未登录词(OOV)时可回退到字节级编码,确保了对任何UTF-8字符串的无损处理能力,这对代码生成任务至关重要。
2.2 扩展定律(Scaling Laws)与Chinchilla最优
OpenAI的Kaplan等人以及随后的DeepMind Chinchilla研究揭示了模型性能与参数量( N N N)、数据量( D D D)和计算量( C C C)之间的幂律关系。Chinchilla最优法则指出,对于给定的算力预算,模型参数量与训练Token数应保持线性比例关系,具体约为 D ≈ 20 N D \approx 20N D≈20N。
这意味着,训练一个700亿参数(70B)的模型,至少需要1.4万亿(1.4T)Token才能达到算力最优。然而,现代开源模型(如Llama 3)打破了这一常规,使用了超过15T的Token来训练8B和70B模型 9。这种“过度训练”(Over-training)的目的是为了在推理阶段获得极致的性能——通过在预训练阶段投入更多沉没成本,换取更小模型尺寸下的高性能,从而显著降低下游用户的推理成本与显存需求。
3. 监督微调(SFT):指令跟随与格式对齐
预训练模型本质上是一个“文本补全引擎”,它只能预测下一个最可能的词,而不具备遵循指令交互的能力。**监督微调(Supervised Fine-Tuning, SFT)**旨在将这种概率预测能力转化为对用户意图的理解与执行 12。
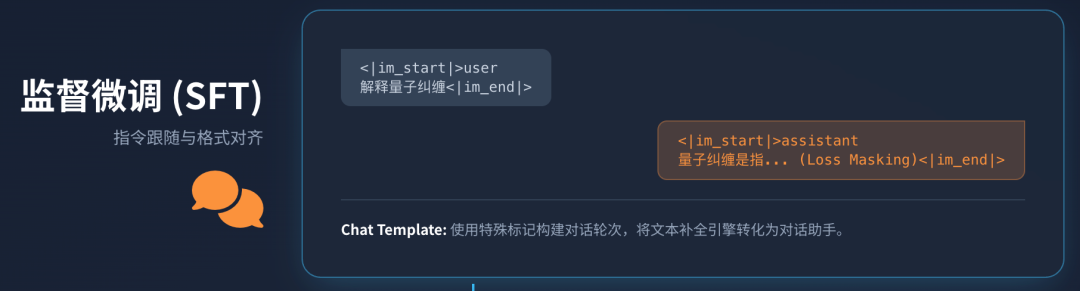
3.1 指令数据集的构建
SFT阶段使用的数据量远小于预训练(通常为几万到几十万条),但对质量要求极高。数据通常由(Prompt, Response)对组成,涵盖问答、摘要、代码生成、逻辑推理等多种任务。
**Chat Template(对话模板)**的作用不可小觑。为了让模型区分用户指令与自身回复,以及处理多轮对话历史,输入序列必须通过特殊的控制符进行格式化。例如,Llama 3 或 ChatML 格式使用了明确的 <|im_start|> 和 <|im_end|> 标记:
JSON
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
解释量子纠缠。<|im_end|>
<|im_start|>assistant
量子纠缠是指…<|im_end|>
这种结构化输入使得模型能够学习对话的轮次概念,是构建聊天机器人的基础。在SFT过程中,通常只对 assistant 回复部分的Token计算损失(Loss Masking),确保模型专注于学习如何生成回复,而非记忆用户的提问 14。
4. 参数高效微调(PEFT):LoRA与QLoRA的技术解构
全量微调(Full Fine-Tuning)一个70B的模型需要更新所有参数,对显存和算力的需求是巨大的(通常需要8张A100/H100)。为了降低门槛,参数高效微调(PEFT)技术应运而生,其中LoRA(Low-Rank Adaptation)及其量化版本QLoRA是目前的事实标准 15。

4.1 LoRA的低秩矩阵分解原理
LoRA基于一个假设:模型适应特定任务时的权重更新矩阵具有极低的“内在秩”(Intrinsic Rank)。因此,我们不需要直接更新巨大的权重矩阵 W ∈ R d × k W \in \mathbb{R}^{d \times k} W∈Rd×k,而是冻结 W W W,并引入两个可训练的低秩矩阵 A ∈ R r × k A \in \mathbb{R}^{r \times k} A∈Rr×k 和 B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r,其中 r ≪ min ( d , k ) r \ll \min(d, k) r≪min(d,k) 17。
前向传播的计算公式变为:
h = W x + Δ W x = W x + B A x ⋅ α r h = Wx + \Delta Wx = Wx + BAx \cdot \frac{\alpha}{r} h=Wx+ΔWx=Wx+BAx⋅rα
这里 α \alpha α 是缩放系数,用于调节适配器权重的影响力。通过这种方式,LoRA将可训练参数量减少了几个数量级(通常小于原模型的1%)。例如,微调Llama 3-70B可能只需要训练几百MB的参数,而不是几百GB 19。
4.2 QLoRA:4-bit量化与NormalFloat
QLoRA进一步结合了高精度的量化技术,使得在单张消费级显卡(如RTX 3090/4090)上微调大模型成为可能。其核心技术突破包括 15:
- 4-bit NormalFloat (NF4) 数据类型: 传统的INT4量化假设权重均匀分布,但这不符合神经网络权重的正态分布特性。NF4通过基于正态分布的分位数设计量化桶,实现了信息论层面最优的量化精度,显著减少了量化误差。
- 双重量化(Double Quantization): 为了进一步节省显存,QLoRA对量化常数本身也进行了再次量化。
- 分页优化器(Paged Optimizers): 利用NVIDIA的统一内存特性,在显存不足时自动将优化器状态(Optimizer States)逐页换出到CPU内存中,从而防止OOM(Out of Memory)错误。
实测数据表明,QLoRA将65B模型的微调显存需求从超过780GB(全量FP16)降低到了48GB以内,且在性能上几乎没有损失 23。
5. 对齐工程:从RLHF到DPO的博弈演进
SFT后的模型虽然能遵循指令,但仍可能产生幻觉、偏见或有害内容。**对齐(Alignment)**阶段的目标是让模型符合人类的价值观(如有用性、诚实性、无害性)。
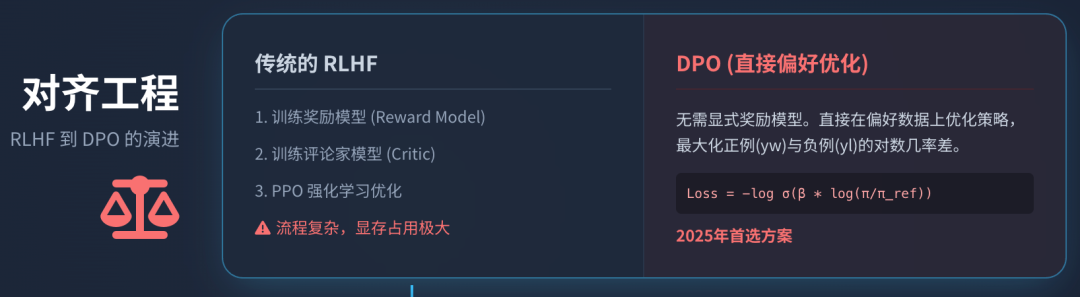
5.1 RLHF:基于人类反馈的强化学习
OpenAI在InstructGPT中确立的RLHF(Reinforcement Learning from Human Feedback)流水线包含三个步骤 12:
- 奖励模型(Reward Model, RM)训练: 收集人类对模型多个回复的排序数据(例如 A > B > C A > B > C A>B>C),训练一个RM来预测人类偏好分数。
- PPO(Proximal Policy Optimization)优化: 使用RM作为环境反馈,利用PPO算法优化SFT模型(策略)。
- PPO目标函数与KL惩罚: 为了防止模型为了通过“作弊”获取高分(Reward Hacking)而输出乱码或偏离自然语言分布,PPO在目标函数中加入了一个KL散度(Kullback-Leibler Divergence)惩罚项。该项约束当前的强化学习策略 π _ RL \pi\_{\text{RL}} π_RL 不能偏离原始SFT策略 π _ SFT \pi\_{\text{SFT}} π_SFT 太远 26。
KaTeX parse error: Expected group as argument to '\left' at end of input: …mathbb{E} \left其中 β \beta β 控制了惩罚的力度。PPO算法通过裁剪(Clipping)概率比率,保证了每次参数更新的幅度在可控范围内,从而维持训练的稳定性。
5.2 DPO:直接偏好优化
RLHF虽然强大,但流程极其复杂且不稳定,需要同时在显存中维护策略模型、参考模型、奖励模型和评论家模型(Critic)。直接偏好优化(Direct Preference Optimization, DPO) 提出了一种革命性的简化方案 28。
DPO的数学推导揭示了一个深刻的结论:最优的奖励函数可以直接用最优策略来表示。因此,我们可以直接在偏好数据上优化策略模型,而无需显式训练奖励模型。DPO的损失函数直接基于正例( y _ w y\_w y_w)和负例( y _ l y\_l y_l)的似然比构建:
L _ DPO ( π _ θ ; π _ ref ) = − E _ ( x , y _ w , y _ l ) ∼ D [ log σ ( β log π _ θ ( y _ w ∣ x ) π _ ref ( y _ w ∣ x ) − β log π _ θ ( y _ l ∣ x ) π _ ref ( y _ l ∣ x ) ) ] \mathcal{L}\_{\text{DPO}}(\pi\_\theta; \pi\_{\text{ref}}) = -\mathbb{E}\_{(x, y\_w, y\_l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi\_\theta(y\_w|x)}{\pi\_{\text{ref}}(y\_w|x)} - \beta \log \frac{\pi\_\theta(y\_l|x)}{\pi\_{\text{ref}}(y\_l|x)} \right) \right] L_DPO(π_θ;π_ref)=−E_(x,y_w,y_l)∼D[logσ(βlogπ_ref(y_w∣x)π_θ(y_w∣x)−βlogπ_ref(y_l∣x)π_θ(y_l∣x))]
这个公式本质上是在最大化正例相对于负例的对数几率差。DPO不仅训练速度更快,显存占用更低,而且在许多基准测试中表现出比PPO更好的稳定性和生成质量,已成为2025年开源模型对齐的首选方案 31。
6. 推理工程与显存优化:速度与成本的平衡
模型训练完成后,如何高效部署推理(Inference)是工程落地的关键。推理阶段的主要瓶颈在于显存带宽(Memory Bandwidth)而非计算速度。
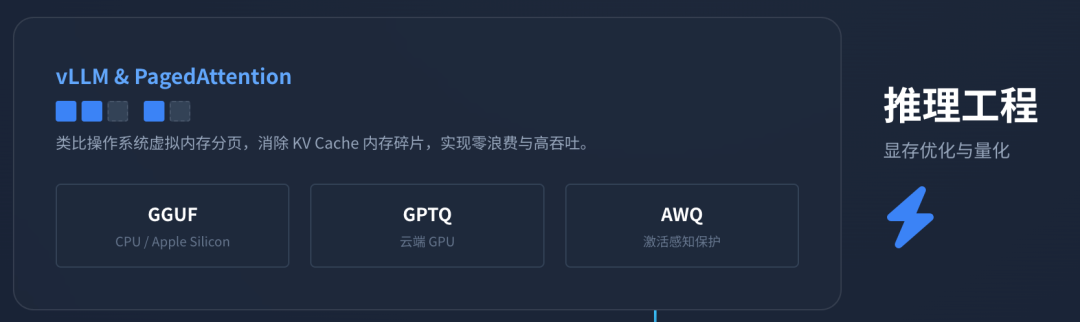
6.1 KV Cache与PagedAttention
LLM生成是一个自回归过程,生成第 n n n 个Token时需要前面 n − 1 n-1 n−1 个Token的信息。为了避免重复计算, K K K 和 V V V 矩阵会被缓存下来(KV Cache)。随着序列长度增加,KV Cache占用的显存会线性增长,甚至超过模型权重本身。
传统的KV Cache要求连续的显存空间,导致了严重的内存碎片化和浪费。vLLM 框架提出的 PagedAttention 算法借鉴了操作系统虚拟内存的分页思想 33。它将KV Cache切分为固定大小的块(Blocks),并通过页表(Page Table)将逻辑上的连续Token映射到物理上不连续的显存块中。
这种机制带来了两大突破:
- 零内存浪费: 只有当块填满时才分配新块,消除了内部碎片。
- 高效并发: 多个序列可以共享相同的物理块(例如在Parallel Sampling或System Prompt共享场景下),极大地提高了吞吐量(Throughput)。
6.2 量化格式之争:GGUF, GPTQ, AWQ
为了在资源受限的设备上运行LLM,推理时的后训练量化(PTQ)技术百花齐放。以下是三种主流格式的对比分析 36:
| 特性 | GGUF (llama.cpp) | GPTQ | AWQ |
| 核心原理 | 专为CPU/Apple Silicon优化,支持混合计算(部分层卸载到GPU)。 | 基于Hessian矩阵逆近似,逐层量化,修正剩余权重的误差。 | 激活感知量化(Activation-aware),保护对激活值影响大的权重(Outliers)。 |
| 主要硬件 | CPU, Apple Mac (M1/M2/M3), 移动设备。 | NVIDIA GPU (服务器/桌面端)。 | NVIDIA GPU,边缘端GPU (Jetson)。 |
| 优势 | 兼容性极强,生态普及度高,适合个人用户本地部署。 | 在GPU上推理速度快,压缩率高,适合云端服务。 | 对量化敏感的模型(如Code模型)精度保持更好,校准成本低。 |
| 劣势 | 纯GPU环境下速度不如GPTQ/AWQ。 | 校准过程慢,对激活分布变化敏感。 | 相对较新,生态工具链支持稍弱于GPTQ。 |
对于希望在本地MacBook上运行模型的开发者,GGUF是唯一选择;而对于生产环境的GPU集群,AWQ通常提供更好的精度-速度平衡。
7. 检索增强生成(RAG):突破知识边界
尽管LLM具备海量知识,但存在知识截止(Knowledge Cutoff)和幻觉(Hallucination)问题。RAG(Retrieval-Augmented Generation) 通过外挂知识库解决了这一难题 39。
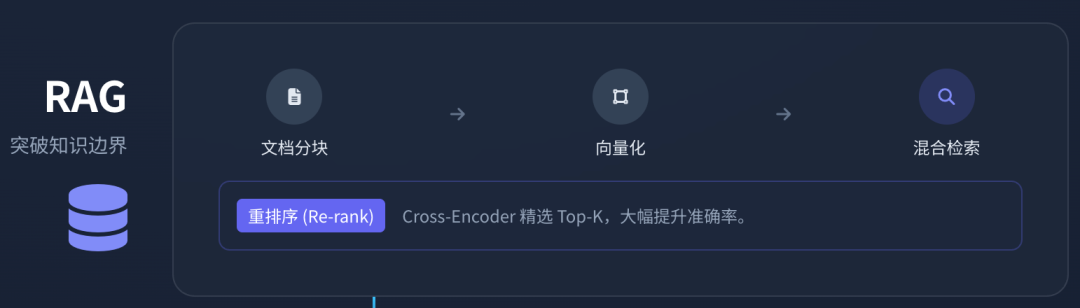
7.1 现代RAG架构解析
构建一个工业级的RAG系统远比简单的“向量检索”复杂。一个完整的Python RAG流水线通常包含以下环节 40:
- 文档分块(Chunking): 将长文档切分为语义完整的片段。简单的按字符切分往往破坏语义,现代方法采用递归字符切分(RecursiveCharacterTextSplitter)或基于语义的切分。
- 向量化(Embedding): 使用Embedding模型(如OpenAI text-embedding-3或开源的BGE-M3)将文本转化为高维向量。
- 混合检索(Hybrid Search): 单纯的向量检索(稠密检索)在匹配专有名词或精确短语时表现不佳。工业界标准做法是结合BM25关键字检索(稀疏检索)与向量检索,通过加权融合(Reciprocal Rank Fusion, RRF)获取候选集。
- 重排序(Re-ranking): 候选集往往包含噪声。引入一个Cross-Encoder重排序模型(如BGE-Reranker),对(Query, Chunk)对进行精细打分,筛选出最相关的Top-K片段注入LLM上下文。
- 上下文注入与生成: 将检索到的片段作为“上下文”填入Prompt模板中,指示LLM“仅根据以下信息回答问题”。
7.2 代码实现概念(Python)
Python
RAG 核心逻辑概念代码 [40, 42]
from sentence_transformers import SentenceTransformer
import faiss
1. 加载与向量化
encoder = SentenceTransformer(‘all-MiniLM-L6-v2’)
docs =
vectors = encoder.encode(docs)
2. 构建索引 (FAISS)
index = faiss.IndexFlatL2(vectors.shape)
index.add(vectors)
3. 检索
query = “什么是RAG?”
q_vec = encoder.encode([query])
distances, indices = index.search(q_vec, k=3)
4. 生成 (伪代码)
context = [docs[i] for i in indices]
prompt = f"基于上下文: {context} 回答: {query}"
llm.generate(prompt)
8. 智能体(Agents):从LangChain到LangGraph的范式跃迁
如果说RAG是给LLM配了图书馆,那么Agent就是给LLM配了手和脚。Agent系统允许模型自主规划、调用工具并执行复杂任务。
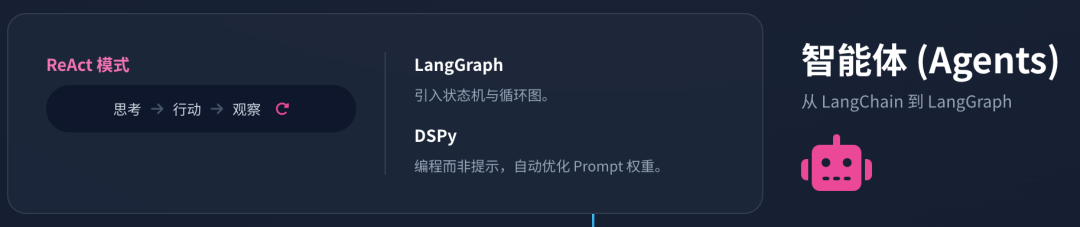
8.1 ReAct模式:推理与行动的循环
ReAct(Reason + Act)是Agent的核心认知模式。模型生成一个“思考(Thought)”,决定调用某个“工具(Action)”,观察工具返回的结果(Observation),然后继续思考,直到完成任务 43。
8.2 LangChain vs. LangGraph
早期的Agent框架如LangChain主要基于有向无环图(DAG),即线性的链式调用。然而,真实的复杂任务往往包含循环(Loops)和条件分支(例如:工具报错需要重试,或者根据结果决定下一步动作)。
LangGraph 应运而生,它引入了状态机(State Machine)的概念 44。
- State(状态): 一个持久化的数据对象(字典或Pydantic模型),在图的节点间传递,保存对话历史和中间变量。
- Nodes(节点): 执行具体逻辑的函数(如调用LLM,执行Python代码)。
- Edges(边): 定义流转逻辑。条件边(Conditional Edges) 允许LLM根据当前状态动态决定下一个节点,从而实现真正的“循环”和“自我修正”。
Python
LangGraph 结构概念 [45, 47]
from langgraph.graph import StateGraph, END
class AgentState(TypedDict):
messages: list
defcall_llm(state):
# LLM 决定是否调用工具
return {"messages": [response]}
defrun_tool(state):
# 执行工具
return {"messages": [tool\_output]}
workflow = StateGraph(AgentState)
workflow.add_node(“agent”, call_llm)
workflow.add_node(“tool”, run_tool)
条件跳转:如果LLM想调工具 -> tool,否则 -> END
workflow.add_conditional_edges(“agent”, should_continue)
workflow.add_edge(“tool”, “agent”) # 工具执行完回到Agent继续思考 (循环)
app = workflow.compile()
8.3 DSPy:编程而非提示工程
传统的Agent开发依赖脆弱的Prompt Engineering。DSPy 提出了一种新范式:将LLM视为程序模块,将Prompt视为可优化的“权重” 48。
在DSPy中,开发者定义模块的签名(Signature,例如 input: question -> output: answer),并提供少量的示例数据。DSPy的编译器(Optimizer)会自动调整和优化发给LLM的Prompt,甚至在多跳推理任务中自动生成最优的Few-shot示例。这使得Agent系统更加鲁棒,且能够通过数据驱动的方式自我进化。
9. 2025年模型格局:百花齐放
截止2025年,开源模型生态已呈现三足鼎立之势,性能直逼闭源顶尖模型(如GPT-4o)9。

| 模型系列 | Llama 3 / 3.1 / 3.3 | Qwen 2.5 (通义千问) | Mistral Large 2 |
| 开发者 | Meta (美国) | Alibaba Cloud (中国) | Mistral AI (法国) |
| 核心优势 | 生态系统的基石,微调工具链最完善。3.3 70B在通用任务上表现极佳。 | 代码与数学能力:Qwen 2.5-Coder在HumanEval等代码基准上超越了Llama,甚至匹敌GPT-4。多语言支持极强。 | 极高的参数效率与推理窗口(128k)。擅长逻辑推理与欧洲语言任务。 |
| 架构特点 | 稠密Transformer, GQA, RoPE。 | 包含稠密版与MoE(混合专家)版本。 | 著名的Mixtral MoE架构先驱。 |
| 适用场景 | 通用对话、角色扮演、作为微调的基座模型。 | 编程辅助、数学解题、中文及多语言业务场景。 | 企业级RAG、长文档分析。 |
DeepSeek-R1 等模型的出现,更是引入了推理模型(Reasoning Models)的新赛道,通过强化学习激发模型的思维链(Chain of Thought),在复杂逻辑任务上展现出惊人的潜力 51。
10. 结论:通往精通之路
精通LLM并非仅仅意味着会调用API,而是要建立从底层数学原理到上层系统架构的完整认知闭环。
- 理论层: 必须手写一遍Self-Attention和LoRA的实现,理解梯度如何流动,理解KV Cache如何通过分页机制解决显存瓶颈。
- 训练层: 掌握SFT的数据格式构建与Chat Template原理,理解DPO如何通过简单的分类损失替代复杂的PPO流程实现对齐。
- 应用层: 超越简单的RAG,转向LangGraph构建的循环Agent系统,利用DSPy将Prompt工程转化为可编程、可优化的模块。
未来的AI工程师将不再仅仅是“提示词工程师”,而是认知系统架构师——设计能够规划、记忆、使用工具并自我修正的智能系统。从0到1的跨越已经完成,现在是迈向深水区的时候了。**
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 1410
1410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









