







功能
- 内存预留,顾名思义,将虚拟机使用的内存在主机上预留出来,不让其它内存使用,同时也禁止主机将内存交换到swap。内存预留的虚拟机,使用的内存与正常虚机有三点不同:
- 内核不会对这段内存执行页回收流程,因此如果虚拟机进程不退出,这段内存永远不会被释放
- 内存一旦预留,内核将为虚机进程立即分配物理内存,因此qemu在访问这段内存时,不会发生缺页异常
- 内存一旦预留,如果内核需要回收内存,不会将这段内存交换到swap分区
开源用法
libvirt配置
<domain>
<memoryBacking>
<locked/>
</memoryBacking>
</domain>
qemu配置
-realtime mlock=on
对比
预留前
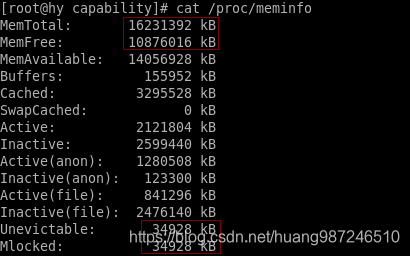
- 内存预留前,主机的内存使用情况和虚拟机占用内存情况如下,这里我的虚机配置的4G内存,主机使用内存1G,qemu进程占用的内存499016KB = 487MB

- 内存预留前,主机的内存统计信息中,不可回收的内存大小为34928KB
预留后
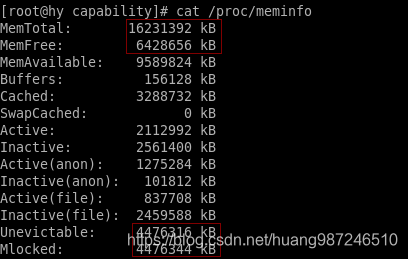
- 内存预留后,情况如下,主机使用的内存增大到5G,qemu进程占用的内存4840004KB = 4.6G

- 内存预留后,预留的内存对应的物理页被不可回收链表(unevictable list)管理起来,系统回收时会跳过这类链表中的页,反映到统计信息中,不可回收的内存增大,与虚机预留的内存大小接近。
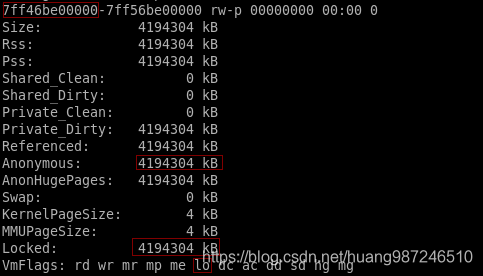
- gdb查看pc.ram RAMBlock的host域记录的地址,这是qemu为虚拟机分配内存的起始虚机地址(HVA):0x7ff46be00000

- 在进程的smaps中查看描述这段虚拟内存的vm_area_struct结构,因为qemu申请内存是通过使用mmap映射匿名文件到进程的地址空间来实现的,因此这段VMA拥有的都是匿名页,同时可以看到,内存预留使能后VMA的物理页面都分配了,即这段虚拟内存对应的页表项被填满,应用程序访问时不会再产生缺页故障使得效率变高。
预留原理
开源实现原理
参数解析
bool enable_mlock = false; // 全局变量
main
/* 解析到realtime参数 */
case QEMU_OPTION_realtime:
/* 取出realtime参数可用的选项 */
opts = qemu_opts_parse_noisily(qemu_find_opts("realtime"),
optarg, false);
/* Don't override the -overcommit option if set */
/* 解析mlock选项 */
enable_mlock = enable_mlock || qemu_opt_get_bool(opts, "mlock", true);
......
功能实现
- 如果命令行参数有这一行
-realtime mlock=on,enable_mlock全局变量为true,qemu进程初始化函数realtime_init会对应设置内存预留,如下:
static void realtime_init(void)
{
if (enable_mlock) {
os_mlock
mlockall(MCL_CURRENT | MCL_FUTURE)
......
}
}
- qemu中内存预留的实现非常简单,当虚拟机设置内存预留之后,最终简单的调用mlockall就能完成内存预留的配置,mlockall接口会向内核申请将调用进程的所有虚拟地址空间锁住,不让其交换到swap并立即分配。MCL_CURRENT标记表示锁住当前进程的内存,MCL_FUTURE表示锁住未来进程可能分配的内存。
预留部分内存
开源的内存预留实现,要么全部将内存锁住,要么不做限制,这里我们再加一种功能,锁一半内存,即预留部分内存。核心实现就是在qemu分配内存时,将其中的一半用mlock系统调用锁住,从而实现部分内存预留。实现内存预留,首先需要了解虚拟机的内存是怎样?在什么时候?以何种方式申请的。
内存分配流程
用户空间
- x86平台上,物理空间根据编址的不同可以分为两类:内存空间和IO空间。访问这两类空间的不同点在于,访问内存空间时使用所有的地址总线,访问IO空间时使用低16bit地址总线,由于最大寻址范围由地址总线的宽度决定,因此内存空间和IO空间寻址范围不同,内存空间由CPU位宽决定,IO空间就是16bit的寻址范围,64KB
- qemu要模拟虚拟机的内存,抽象物理内存空间为数据结构是必须的,因此qemu实现内存虚拟化的第一步就是初始化用于模拟内存物理空间的数据结构,这个结构就是AddressSpace,如下:
struct AddressSpace {
/* All fields are private. */
struct rcu_head rcu;
char *name;
/* 指向全局的MemoryRegion
* 一个MemoryRegion表示一段逻辑物理内存 */
MemoryRegion *root;
/* Accessed via RCU. */
struct FlatView *current_map;
int ioeventfd_nb;
struct MemoryRegionIoeventfd *ioeventfds;
QTAILQ_HEAD(, MemoryListener) listeners;
/* 用于链接到全局地址空间链表中 */
QTAILQ_ENTRY(AddressSpace) address_spaces_link;
};
- 一个虚拟机的所有地址空间被qemu组织成一个链表,链表头由全局变量address_spaces记录,如下:
static QTAILQ_HEAD(, AddressSpace) address_spaces = QTAILQ_HEAD_INITIALIZER(address_spaces);
- 物理空间分内存和IO空间,qemu模拟的地址空间也一样,分内存地址空间和IO地址空间,分别是
address_space_memory和address_space_io,它们的初始化在memory_map_init中实现,如下:
static void memory_map_init(void)
{
system_memory = g_malloc(sizeof(*system_memory));
/* 初始化系统内存,名字:system,大小:UINT64_MAX */
memory_region_init(system_memory, NULL, "system", UINT64_MAX);
/* 初始化内存空间,名字:memory
* 把系统内存安装到内存空间的root域上 */
address_space_init(&address_space_memory, system_memory, "memory");
system_io = g_malloc(sizeof(*system_io));
/* 初始化IO内存,名字:io,大小:64KB*/
memory_region_init_io(system_io, NULL, &unassigned_io_ops, NULL, "io", 65536);
/* 初始化IO空间,名字:I/O
* 把IO内存安装到IO空间的root域上 */
address_space_init(&address_space_io, system_io, "I/O");
}
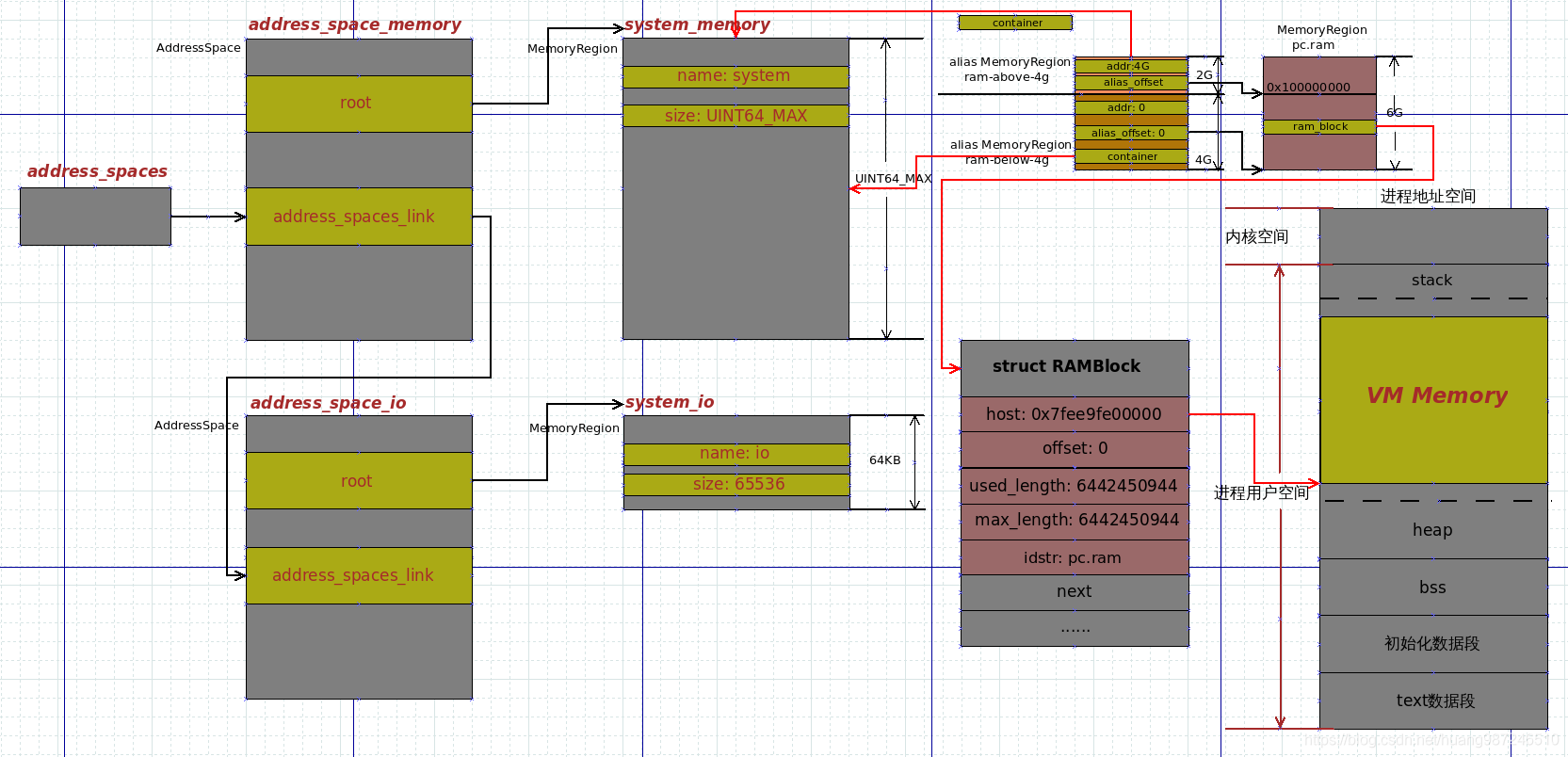
- 地址空间肯定会指向一段内存,这个由AddressSpace的root域表示。root域是个MemoryRegion结构体,它关联一段逻辑内存,MemoryRegion可以是一个容器,用来管理内存,本身没有内存,比如system_memory;可以是一个实体,它有自己的内存,比如pc.ram;可以是一个别名,本身没有内存,但它指向实体内存的一部分,比如ram-below-4g和ram-above-4g
- 一个实体MemoryRegion和其它MemoryRegion的不同在于,它包含一段真正的物理内存,这个内存由MemoryRegiond的ram_block域表示,ram_block是个RAMBlock结构体,表示一段真正可用的内存,说它可用是因为它由qemu进程向内核通过mmap映射得到,对这段内存的访问和普通应用程序申请的内存没有什么两样。
- MemoryRegion结构的关键域如下:
struct MemoryRegion {
bool ram; /* 是否为ram*/
RAMBlock *ram_block; /* 指向MemoryRegion包含的内存(如果存在)*/
MemoryRegion *container;/* 指向所属的MemoryRegion,比如ram-below-4g,container指向的就是system_memory */
Int128 size; /* 内存区域大小 */
hwaddr addr; /* 客户机的物理地址(GPA),当客户机访问addr开始的物理区域,对应的就是qemu模拟的这段内存 */
MemoryRegion *alias; /* 对于别名MemoryRegion,这个域指向实体MemoryRegion */
hwaddr alias_offset; /* 对于别名MemoryRegion,这个域存放别名MemoryRegion在实体MemoryRegion的偏移 */
const char *name;
};
- RAMBlock结构的关键域如下:
struct RAMBlock {
struct MemoryRegion *mr; /* 所属的MemoryRegion,一个RAMBlock肯定有所属的MemoryRegion,但一个MemoryRegion不一定包含RAMBlock*/
uint8_t *host; /* qemu映射的虚拟内存地址起始地址(HVA)*/
ram_addr_t offset; /* 内存区域相对host起始地址的偏移 */
ram_addr_t used_length; /* 内存区域已使用大小 */
ram_addr_t max_length; /* 内存区域大小 */
char idstr[256]; /* 名字 */
/* RCU-enabled, writes protected by the ramlist lock */
QLIST_ENTRY(RAMBlock) next; /* 所有RAMBlock组织成一个链表,头部存放到全局变量ram_list的blocks域中,next用于链入此链表 */
size_t page_size; /* 内存区域的页大小,通常为4K */
};
- qemu开始分配虚机内存流程开始之前,要从命令行解析出用户配置的虚机内存大小,如下:
ram_addr_t ram_size; /* 全局变量 */
main
/* 解析到命令行参数为 -m */
case QEMU_OPTION_m:
/* 从全局变量vm_config_groups中找到内存的选项定义qemu_mem_opts
* 将命令行参数optarg解析后放到qemu_mem_opts中 */
opts = qemu_opts_parse_noisily(qemu_find_opts("memory"), optarg, true);
/* 根据内存参数设置内存大小*/
set_memory_options
/* 找到存放的内存参数 */
opts = qemu_find_opts_singleton("memory")
/* 解析出内存大小 */
sz = qemu_opt_get_size(opts, "size", ram_size)
/* 将内存大小保存到全局变量ram_size中 */
ram_size = sz
/* 将内存大小存放到machine的ram_size中 */
current_machine->ram_size = ram_size
- qemu对虚机内存分配的真正流程,在pc_memory_init函数中,核心函数是memory_region_allocate_system_memory,它负责虚机内存的映射,我们只分析分配内存和管理内存的流程,如下:
pc_memory_init
MemoryRegion *ram;
MemoryRegion *ram_below_4g, *ram_above_4g;
/* Allocate RAM. We allocate it as a single memory region and use
* aliases to address portions of it, mostly for backwards compatibility
* with older qemus that used qemu_ram_alloc().
*/
ram = g_malloc(sizeof(*ram));
memory_region_allocate_system_memory(ram, NULL, "pc.ram",
machine->ram_size);
*ram_memory = ram;
ram_below_4g = g_malloc(sizeof(*ram_below_4g));
memory_region_init_alias(ram_below_4g, NULL, "ram-below-4g", ram,
0, pcms->below_4g_mem_size);
memory_region_add_subregion(system_memory, 0, ram_below_4g);
e820_add_entry(0, pcms->below_4g_mem_size, E820_RAM);
if (pcms->above_4g_mem_size > 0) {
ram_above_4g = g_malloc(sizeof(*ram_above_4g));
memory_region_init_alias(ram_above_4g, NULL, "ram-above-4g", ram,
pcms->below_4g_mem_size,
pcms->above_4g_mem_size);
memory_region_add_subregion(system_memory, 0x100000000ULL,
ram_above_4g);
e820_add_entry(0x100000000ULL, pcms->above_4g_mem_size, E820_RAM);
}
函数首先声明了几个MemoryRegion变量,ram用于表示实体MemoryRegion,ram_below_4g和ram_above_4g用于别名MemoryRegion,用来将实体MemoryRegion分成两部分,变量声明之后就是内存的分配,后面会介绍,内存被分配完之后,其对应的MemoryRegion并不用作管理,qemu会初始化2个MemoryRegion(ram_below_4g,ram_above_4g),让它们指向实体MemoryRegion,然后将两个别名MemoryRegion安装到系统内存的容器(system_memory)中。实际上,当虚机内存不大于4G时,只有ram_below_4g会被创建并安装,当虚机内存大于4G时才同时安装ram_below_4g和ram_above_4g。system_memory,ram_below_4g,ram_above_4g和rm的关系如下图所示。
- 虚机内存的映射在memory_region_allocate_system_memory实现,这是内存分配的核心,它最终会调用mmap向内核申请映射一段虚机内存大小的内存,流程如下:
memory_region_allocate_system_memory
allocate_system_memory_nonnuma
memory_region_init_ram_nomigrate
memory_region_init_ram_shared_nomigrate
qemu_ram_alloc
qemu_ram_alloc_internal
ram_block_add
qemu_anon_ram_alloc
qemu_ram_mmap
mmap(0, total, PROT_NONE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0)
内核空间
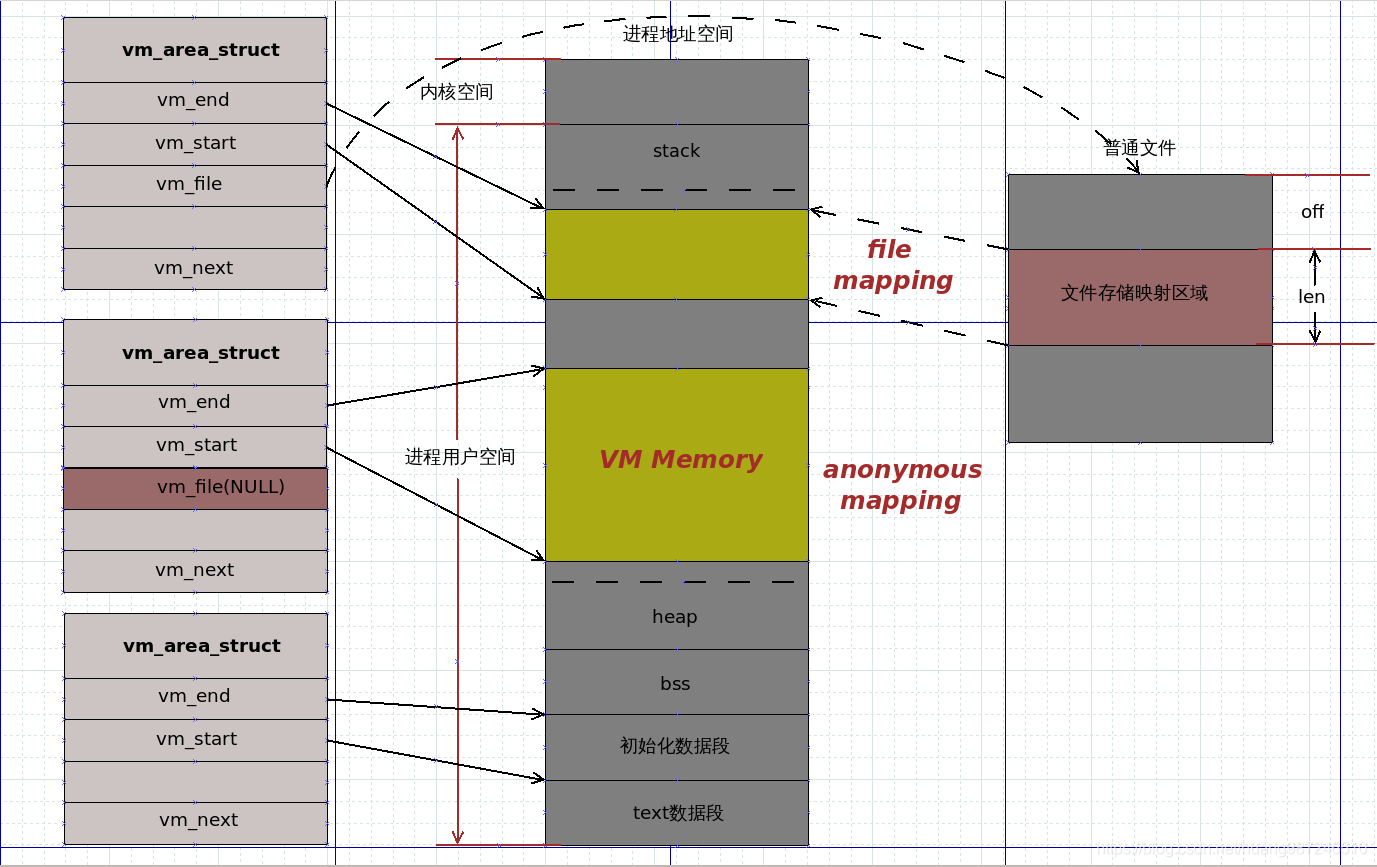
- qemu为虚拟机申请的内存位置处于进程地址空间的堆和栈之间的地址空间中。它调用内存映射接口mmap为虚拟机分配空间,下图的VM Memory区域就是qemu为虚拟机分配的内存空间
- mmap函数原型:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset) - mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。但这里我们的目的并非映射文件,而是申请一段空间给进程,因此传入的fd为-1,flags为
MAP_PRIVATE|MAP_ANONYMOUS,表示匿名映射,这段内存不会映射到磁盘文件。 - 内核的匿名映射的流程如下:
- 在当前进程的虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址
- 为此虚拟区分配一个vm_area_struct结构,接着对其各个域进行初始化,对于匿名映射,vm_file字段为NULL
- 将新分配的vm_area_struct结构插入进程的虚拟地址区域链表和树中
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags, unsigned long, fd, unsigned long, pgoff)
vm_mmap_pgoff
do_mmap_pgoff
do_mmap
mmap_region
/* 分配内存 */
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL)
/* 初始化各字段 */
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
/* 插入虚拟机地址区域链表和树中 */
vma_link(mm, vma, prev, rb_link, rb_parent)
- 匿名映射和普通文件的映射不同点在于内核缺页异常的处理,当用户态进程访问映射的内存区域,触发缺页异常时有下面两种情况:
- 对于进程虚拟机内存区域映射了磁盘文件的情况,vm_area_struct的vm_ops成员的nopages字段不为NULL,nopage字段装入页的函数,该函数把所缺的页从磁盘装入到内存,然后填充页表,完成缺页处理
- 对于匿名映射的情况,vm_area_struct的vm_ops字段为NULL,或者vm_ops->nopage字段为NULL,这种情况下do_anonymous_page最终调用alloc_pages为进程虚拟机内存区域分配页框,然后填充页表,完成缺页处理
- 内核对匿名映射的缺页异常处理流程如下:
do_page_fault
handle_mm_fault
__handle_mm_fault
handle_pte_fault
do_anonymous_page
__alloc_zeroed_user_highpage(__GFP_MOVABLE, vma, vaddr)
alloc_page_vma(GFP_HIGHUSER | __GFP_ZERO | __GFP_MOVABLE, vma, vaddr)
alloc_page_vma
alloc_pages_vma
alloc_pages
分析上面的流程,匿名映射的内存,缺页后会从伙伴系统中申请物理页,GFP_HIGHUSER指示伙伴系统的扫描顺序依次为
ZONE_HIGHMEM -> ZONE_NORMAL -> ZONE_DMA32 -> ZONE_DMA,因此匿名页默认从高端内存区域分配内存
内存预留流程
实现
- 内存预留使用mlock接口,将给定的一段虚拟内存空间内存锁住。具体实现步骤如下:
- qemu的realtime参数增加布尔选项mlock_part用来指示将虚机内存锁一半,主进程代码中增加全局变量enable_part_mlock,qemu解析到part_mlock=on之后将enable_part_mlock设置为true
- qemu为虚拟机分配RAMBlock流程中,在分配成功后,如果检查到enable_part_mlock为true,使用mlock将分配完成的内存锁住一半
- libvirt增加xml选项,控制部分内存预留使能
- qemu代码如下:
diff --git a/exec.c b/exec.c
index 6ab62f4..82c6b84 100644
--- a/exec.c
+++ b/exec.c
@@ -2193,6 +2193,7 @@ static void ram_block_add(RAMBlock *new_block, Error **errp, bool shared)
RAMBlock *last_block = NULL;
ram_addr_t old_ram_size, new_ram_size;
Error *err = NULL;
+ int ret = -1;
old_ram_size = last_ram_page();
@@ -2262,6 +2263,16 @@ static void ram_block_add(RAMBlock *new_block, Error **errp, bool shared)
qemu_madvise(new_block->host, new_block->max_length, QEMU_MADV_DONTFORK);
ram_block_notify_add(new_block->host, new_block->max_length);
}
+ /* 在分配内存的流程中拦截,判断是否开启部分内存预留,如果开启,使用mlock将内存锁住 */
+ if (enable_part_mlock) {
+ fprintf(stderr, "part memory lock: host %llx, length %lld\n",
+ (long long int)new_block->host, (long long int)new_block->max_length/2);
+
+ ret = mlock(new_block->host, new_block->max_length/2);
+ if (ret) {
+ fprintf(stderr, "failed to lock memory, errno: %d\n", -errno);
+ }
+ }
}
#ifdef CONFIG_POSIX
diff --git a/include/sysemu/sysemu.h b/include/sysemu/sysemu.h
index 6065d9e..4b3b4f7 100644
--- a/include/sysemu/sysemu.h
+++ b/include/sysemu/sysemu.h
@@ -17,6 +17,7 @@ extern const char *bios_name;
extern const char *qemu_name;
extern QemuUUID qemu_uuid;
extern bool qemu_uuid_set;
+extern bool enable_part_mlock;
bool runstate_check(RunState state);
void runstate_set(RunState new_state);
diff --git a/vl.c b/vl.c
index d61d560..788b967 100644
--- a/vl.c
+++ b/vl.c
@@ -141,6 +141,7 @@ ram_addr_t ram_size;
const char *mem_path = NULL;
int mem_prealloc = 0; /* force preallocation of physical target memory */
bool enable_mlock = false;
+bool enable_part_mlock = false;
bool enable_cpu_pm = false;
int nb_nics;
NICInfo nd_table[MAX_NICS];
@@ -389,6 +390,10 @@ static QemuOptsList qemu_realtime_opts = {
.name = "mlock",
.type = QEMU_OPT_BOOL,
},
+ { /* 新增 part_mlock参数 */
+ .name = "part_mlock",
+ .type = QEMU_OPT_BOOL,
+ },
{ /* end of list */ }
},
};
@@ -3923,7 +3928,10 @@ int main(int argc, char **argv, char **envp)
}
/* Don't override the -overcommit option if set */
enable_mlock = enable_mlock ||
- qemu_opt_get_bool(opts, "mlock", true);
+ qemu_opt_get_bool(opts, "mlock", false);
+ /* 解析到part_mlock参数 */
+ enable_part_mlock = enable_part_mlock ||
+ qemu_opt_get_bool(opts, "part_mlock", false);
break;
case QEMU_OPTION_overcommit:
opts = qemu_opts_parse_noisily(qemu_find_opts("overcommit"),
- libvirt代码如下:
diff --git a/src/conf/domain_conf.c b/src/conf/domain_conf.c
index eb4e9ac..b56a22f 100644
--- a/src/conf/domain_conf.c
+++ b/src/conf/domain_conf.c
@@ -19522,6 +19522,9 @@ virDomainDefParseXML(xmlDocPtr xml,
if (virXPathBoolean("boolean(./memoryBacking/locked)", ctxt))
def->mem.locked = true;
/* 解析xml配置 */
+ if (virXPathBoolean("boolean(./memoryBacking/part_locked)", ctxt))
+ def->mem.part_locked = true;
+
if (virXPathBoolean("boolean(./memoryBacking/discard)", ctxt))
def->mem.discard = VIR_TRISTATE_BOOL_YES;
@@ -27372,6 +27375,8 @@ virDomainMemtuneFormat(virBufferPtr buf,
virBufferAddLit(&childBuf, "<nosharepages/>\n");
if (mem->locked)
virBufferAddLit(&childBuf, "<locked/>\n");
+ if (mem->part_locked)
+ virBufferAddLit(&childBuf, "<part_locked/>\n");
if (mem->source)
virBufferAsprintf(&childBuf, "<source type='%s'/>\n",
virDomainMemorySourceTypeToString(mem->source));
diff --git a/src/conf/domain_conf.h b/src/conf/domain_conf.h
index 5e2f21d..e19772b 100644
--- a/src/conf/domain_conf.h
+++ b/src/conf/domain_conf.h
@@ -2285,6 +2285,7 @@ struct _virDomainMemtune {
bool nosharepages;
bool locked;
+ bool part_locked;
int dump_core; /* enum virTristateSwitch */
unsigned long long hard_limit; /* in kibibytes, limit at off_t bytes */
unsigned long long soft_limit; /* in kibibytes, limit at off_t bytes */
diff --git a/src/qemu/qemu_command.c b/src/qemu/qemu_command.c
index 98b5546..578ce94 100644
--- a/src/qemu/qemu_command.c
+++ b/src/qemu/qemu_command.c
@@ -7542,15 +7542,19 @@ qemuBuildMemCommandLine(virCommandPtr cmd,
qemuBuildMemPathStr(cfg, def, cmd) < 0)
return -1;
- if (def->mem.locked && !virQEMUCapsGet(qemuCaps, QEMU_CAPS_REALTIME_MLOCK)) {
+ if ((def->mem.locked || def->mem.part_locked)
+ && !virQEMUCapsGet(qemuCaps, QEMU_CAPS_REALTIME_MLOCK)) {
virReportError(VIR_ERR_CONFIG_UNSUPPORTED, "%s",
_("memory locking not supported by QEMU binary"));
return -1;
}
+
if (virQEMUCapsGet(qemuCaps, QEMU_CAPS_REALTIME_MLOCK)) {
virCommandAddArg(cmd, "-realtime");
- virCommandAddArgFormat(cmd, "mlock=%s",
- def->mem.locked ? "on" : "off");
+ if (def->mem.locked) /* 组装qemu命令行参数 */
+ virCommandAddArgFormat(cmd, "mlock=on");
+ else if (def->mem.part_locked)
+ virCommandAddArgFormat(cmd, "part_mlock=on");
}
return 0;
diff --git a/src/qemu/qemu_domain.c b/src/qemu/qemu_domain.c
index d80f9b3..0119ca1 100644
--- a/src/qemu/qemu_domain.c
+++ b/src/qemu/qemu_domain.c
@@ -9768,7 +9768,7 @@ qemuDomainGetMemLockLimitBytes(virDomainDefPtr def)
* however, there is no reliable way for us to figure out how much memory
* the QEMU process will allocate for its own use, so our only way out is
* to remove the limit altogether. Use with extreme care */
- if (def->mem.locked) /* 放开rlimit 的资源限制,使得qemu可以锁任意大小的内存,通过/proc/pid/limits可以查看设置效果 */
+ if (def->mem.locked || def->mem.part_locked)
return VIR_DOMAIN_MEMORY_PARAM_UNLIMITED;
if (ARCH_IS_PPC64(def->os.arch) && def->virtType == VIR_DOMAIN_VIRT_KVM) {
验证
- libvirt配置如下xml,启动虚拟机
<memoryBacking>
<part_locked/>
</memoryBacking>
- 查看qemu命令行和日志,参数下发正确part_mlock=on,mlock成功锁了6段内存
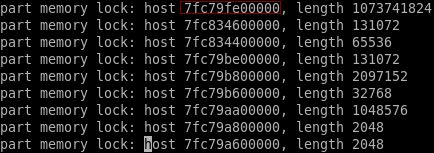
- 第一段内存对应的是pc.ram,它的长度是2147483648(2G)

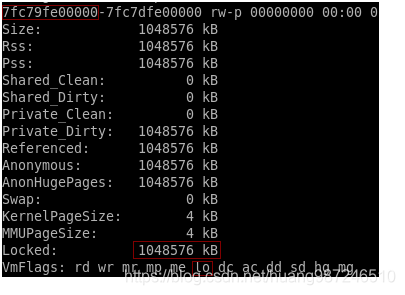
- 查看/proc/pid/smaps,2G中内存有1G被锁住了
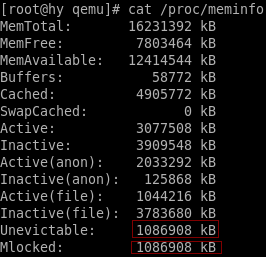
- 再看/proc/meminfo的内容,不可回收的lru链表中有增加了1G大小的内存,锁住的内存也有1G
- 关于smaps的各项的解释,可以参考内核Documentation/filesystems/proc.txt
mlock内核实现
系统调用
mlock的主要步骤如下:
- 检查进程能否执行mlock
- 在进程地址空间中查找合适的vm_area_struct虚拟内存区间,设置VM_LOCKED标记到虚拟内存区
- 为设置标记的虚拟内存区域分配物理页面,填充进程的页表
static __must_check int do_mlock(unsigned long start, size_t len, vm_flags_t flags)
{
unsigned long locked;
unsigned long lock_limit;
int error = -ENOMEM;
if (!can_do_mlock())
return -EPERM;
lru_add_drain_all(); /* flush pagevec */
len = PAGE_ALIGN(len + (offset_in_page(start)));
start &= PAGE_MASK;
lock_limit = rlimit(RLIMIT_MEMLOCK);
lock_limit >>= PAGE_SHIFT;
locked = len >> PAGE_SHIFT;
if (down_write_killable(¤t->mm->mmap_sem))
return -EINTR;
locked += current->mm->locked_vm;
/* 两种场景可以通过检查:
* 一是mlock的内存小于进程的rlimit上限,二是执行mlock的进程具有CAP_IPC_LOCK能力
* 由于用户态的libvirt在设置内存预留时已经放开了rlimit memlock的限制
* 因此这里locked总能在最大值范围内 */
if ((locked > lock_limit) && (!capable(CAP_IPC_LOCK))) {
/*
* It is possible that the regions requested intersect with
* previously mlocked areas, that part area in "mm->locked_vm"
* should not be counted to new mlock increment count. So check
* and adjust locked count if necessary.
*/
locked -= count_mm_mlocked_page_nr(current->mm,
start, len);
}
/* check against resource limits
* 进程的虚拟内存区域VMA是同质的
* 如果锁住的这段内存和进程已存在的不同属性的VMA重叠
* 需要进行额外的分割或者合并VMA操作 */
if ((locked <= lock_limit) || capable(CAP_IPC_LOCK))
error = apply_vma_lock_flags(start, len, flags);
up_write(¤t->mm->mmap_sem);
if (error)
return error;
/* 为mlock锁住的内存区域分配物理页 */
error = __mm_populate(start, len, 0);
if (error)
return __mlock_posix_error_return(error);
return 0;
}


















 8354
8354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











