







流程介绍
虚机向virtio磁盘写入数据后,走到块设备层提交bio,最终会往virtio-blk队列的环上添加写入数据的物理地址,整个流程如下:
submit_bio
generic_make_request /* 将bio提交到块设备的工作队列上去 */
blk_mq_dispatch_rq_list /* 工作队列处理函数 */
q->mq_ops->queue_rq() /* 调用多队列入队请求的具体实现 */
virtio_queue_rq /* virtio磁盘的入队请求实现 */
__virtblk_add_req /* 将IO数据地址添加到virtio的队列上 */
virtqueue_kick_prepare /* 判断是否要通知后端 */
virtqueue_notify /* 通知 */
vq->notify() /* virtio队列的通知实现 */
vp_notify() /* 对于基于pci的virtio设备,最终调用该函数实现通知 */
vp_notify的具体实现如下:
/* the notify function used when creating a virt queue */
bool vp_notify(struct virtqueue *vq)
{
/* we write the queue's selector into the notification register to
* signal the other end */
iowrite16(vq->index, (void __iomem *)vq->priv);
return true;
}
从这里看,notify的动作就是往队列的一个priv成员中写入队列的idx。这个priv成员在哪儿初始化的?看下面:
static struct virtqueue *setup_vq(struct virtio_pci_device *vp_dev,
struct virtio_pci_vq_info *info,
unsigned index,
void (*callback)(struct virtqueue *vq),
const char *name,
u16 msix_vec)
{
......
/* create the vring */
vq = vring_create_virtqueue(index, num, /* 1 */
SMP_CACHE_BYTES, &vp_dev->vdev,
true, true, vp_notify, callback, name);
vq->priv = (void __force *)vp_dev->notify_base + off * vp_dev->notify_offset_multiplier; /* 2 */
......
}
1. 创建virtio磁盘列队,为vring分配空间,并将其挂载到队列上。函数传入了一个vp_notify回调函数,这个函数就是在Guest添加buffer后要调用的
通知后端的notify函数
2. 设置notify函数中要写入的pci地址,这个地址的计算依据是virtio规范
硬件基础
virtio设备的PCI空间中,virtio_pci_cap_notify_cfg是专门用作前端通知的cap,通过读取这个配置空间的信息,可以计算出通知后端时前端写入的地址,整个virtio-pci的配置空间如下:

virtio中关于notify写入地址的计算方法介绍如下:

从规范的介绍来看,notify地址是notify cap在bar空间内的偏移,加上common cap的queue_notify_off字段与notify cap的notify_off_multiplier的乘积。再看一次之前的地址计算公式,就是规范里面介绍的计算方法
vq->priv = (void __force *)vp_dev->notify_base + off * vp_dev->notify_offset_multiplier
VM-exit
前端往notify地址写入数据后,由于这是外设的空间,写操作被认为是敏感指令,触发VM-exit,首先查看前端notify virtio磁盘时要写的地址区间。
- 后端查看virtio磁盘的pci配置空间物理地址,notify的cap位于BAR4,BAR4的物理区间是0xfe008000~0xfe00bfff
virsh qemu-monitor-command vm --hmp info pci
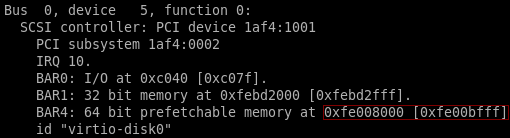
- 后端查看notify配置空间在BAR4占用的物理区间0xfe00b000~0xfe00bfff
virsh qemu-monitor-command vm --hmp info mtree

- 从上面可以知道,前端如果往virtio磁盘上添加buffer之后,notify要写入的地址区间是0xfe00b000~0xfe00bfff,使用gdb跟踪vp_notify的流程,可以看到最终notify会往地址为0xffffc900003b8000的内存空间写0,该地址就是pci总线域notify地址通过ioremap映射到存储器域的地址,理论上,访问这个地址就是访问pci的notify地址

- 继续单指令调试,下面这条mov指令是真正的写io空间的操作,执行的时候触发VM-Exit

- 在执行mov指令之前,打开主机上的kvm的两个trace点,获取VM-Exit中KVM的日志打印
echo 1 > /sys/kernel/debug/tracing/events/kvm/kvm_exit/enable
echo 1 > /sys/kernel/debug/tracing/events/kvm/kvm_fast_mmio/enable

- 两个trace点输出信息在内核的定义如下:
/*
* Tracepoint for kvm guest exit:
*/
TRACE_EVENT(kvm_exit,
TP_PROTO(unsigned int exit_reason, struct kvm_vcpu *vcpu, u32 isa),
TP_ARGS(exit_reason, vcpu, isa),
......
TP_printk("reason %s rip 0x%lx info %llx %llx", /* 1 */
(__entry->isa == KVM_ISA_VMX) ?
__print_symbolic(__entry->exit_reason, VMX_EXIT_REASONS) :
__print_symbolic(__entry->exit_reason, SVM_EXIT_REASONS),
__entry->guest_rip, __entry->info1, __entry->info2)
);
/*
* Tracepoint for fast mmio.
*/
TRACE_EVENT(kvm_fast_mmio,
TP_PROTO(u64 gpa),
TP_ARGS(gpa),
......
TP_printk("fast mmio at gpa 0x%llx", __entry->gpa) /* 2 */
);
1. kvm_exit的输出信息分别是:退出原因,引发退出的指令地址,VM-Exit退出时VMCS VM-Exit相关信息,如下:
info1:EXIT_QUALIFICATION,记录触发VM-Exit的指令或者异常
info2:VM_EXIT_INTR_INFO,记录触发VM-Exit的中断信息
2. kvm_exit如果是EPT violation或者EPT misconfiguration引起的,会将引起退出的物理地址放到VMCS VM-Exit的GUEST_PHYSICAL_ADDRESS
字段,这里就是打印这个字段里面的值
- 追踪VM-Exit流程,可以知道notify引发的退出,被归类为EPT misconfiguration,是由于访问内存异常产生的退出。如果虚机EPT页不存在,触发的是EPT violation异常,KVM会进行缺页处理。如果页存在但访问权限不对,才触发EPT misconfiguration,这里是虚机没有这个地址的访问权限。从而触发VM-Exit。
KVM缺页处理
- 当客户机因为缺页异常而退出后,KVM有两种处理方式,第一种是常规的方式,针对引起缺页的GPA,填充其对应的EPT页表并将信息同步给qemu进程的页表,这时KVM处理客户机缺页的最常见流程。另外一种,就是本文讨论的情况,虚机访问的物理地址不是普通的内存,是一个PCI的配置空间,这种类型的内存,在qemu的分类中是MMIO(Memory-map ),当虚机读写这类内存的时候,KVM检查到之后通过ioeventfd通知qemu,具体原理参考qemu中的eventfd机制。
















 8260
8260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











