






分治法
分治法是一种一般性的算法设计技术,它将问题的实例划分为若干个较小的实例(最好拥有相同的规模),对这些较小的实例递归求解,然后合并这些解,以得到原始问题的解。许多高效的算法都基于这种技术,虽然有时候它的适应性和效率并不如一些更简单的算法。
分治法对于并行计算是非常理想的,因为各个子问题都可以由各自的CPU同时计算。
一个规模为n的实例可以划分为b个规模为n/b的实例,其中a个实例需要求解(这里,a和b是常量,
a⩾1
, b>1)。
f(n)是一个函数,表示将问题分解为小问题和将结果合并起来所消耗的时间。
许多分治算法的时间效率T(n)满足方程
T(n)=aT(n/b)+f(n)
。称为通用分治递推式。
主定理确定了该方程解的增长次数。
如果在递推式中
f(n)∈Θ(nd)
,其中
d⩾0
,那么:
合并排序
合并排序是一种分治排序算法。把一个输入数组一分为二,并对它们递归排序,然后把这两个排好序的子数组合并为原数组的一个有序排列。
在任何情况下,这个算法的时间效率都是O(nlogn),而且它的键值比较次数非常接近理论上的最小值。
它的主要缺点是需要相当大的额外存储空间。
代码示例看这里。
相关题目
- A[0..n-1]是一个n个不同实数构成的数组。如果一对元素
(A[i],A[j])是倒序的,即i<j但是A[i]>A[j],则它们被称为一个倒置。设计一个 O(nlogn) 算法来计算数组中的倒置数量。
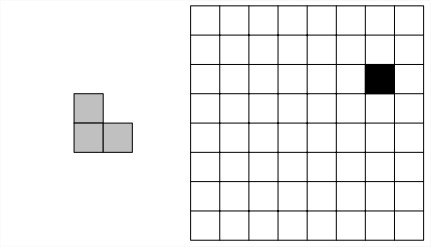
思路:分治法MergeSort中,merge的过程中每次右<左计数就加1。 - Tromino谜题。Tromino是一个由棋盘上的三个邻接方块组成的L型瓦片。我们的问题是,如何用Tromino覆盖一个缺少了一个方块(可以在棋盘上的任何位置)的
2n×2n
棋盘。除了这个缺失的方块,Tromino应该覆盖棋盘上的所有方块,而且不能有重叠。
思路:如图变成4个 4×4 缺一块问题,迭代下去直到到达n个 2×2 缺一块问题。
一个示例网站
快速排序
快速排序是一种分治排序算法,它根据元素值和某些事先确定的元素的比较结果,来对输入元素进行分区。
对于随机排列的数组,它是一种较为出众的nlogn效率算法,而且因为它的最差效率是平方级的。
代码示例看这里。
相关题目
-
设计一个算法对n个实数组成的数组进行重新排列,使得其中所有的负元素都位于正元素之前。这个算法需要兼顾空间效率和时间效率。
思路:维持三个区间:负数、未知、正数。每次迭代都从左或右缩减一位未知区间。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
#include <algorithm> #include <iostream> void neg_before_pos(int* A, int n) { // puts negative elements before positive (and zeros, if any) in an array // input: array A[0..n-1] of real numbers // output: array A[0..n-1] in which all its negative elements precede nonnegative if (!A || n < 2) return; int i(0), j(n-1); while (i <= j) { if (A[i] < 0) {++i;} // shrink the unknown section from the left else{ std::swap(A[i], A[j]); --j; } } } int main() { neg_before_pos(NULL, 0); int A[7] = {5,-5,1,0,0,-2,-3}; neg_before_pos(A, 7); for (int i = 0; i < 7; ++i) { std::cout << A[i] << " "; } system("Pause"); }
-
荷兰国旗问题。要求对字符R、W和B构成的任意数组排序(红、白和蓝是荷兰国旗的颜色),使得所有R排在最前面,W随后,B在最后。为该问题设计一个线性效率的在位算法。
思路:维持四个区间:R、W、未知、B。每次迭代都从左或右缩减一位未知区间。
leetcode上相同题目。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
#include <algorithm> #include <iostream> void dutch_flag(char* A, int n) { // sorts an array with values in a three-element set // input: an array A[0..n-1] of characters from {R,W,B} // output: array A[0..n-1] in which all its R elements precede all its W elements that precede all its B elements if (!A || n < 2) return; int r(0), w(0), b(n-1); while (w <= b) { if (A[w] == 'R') { std::swap(A[r], A[w]); ++r; ++w; }else if (A[w] == 'W') { ++w; }else { std::swap(A[w], A[b]); --b; } } } int main() { dutch_flag(NULL,0); char A[7] = {'B','W','B','R','W','R','W'}; dutch_flag(A,7); for (int i = 0; i < 7; ++i) { std::cout << A[i] << " "; } system("Pause"); }
-
螺钉和螺母问题。假设我们有n个直径各不相同的螺钉,以及n个相应的螺母。我们一次只能比较一对螺钉和螺母,来判断螺母是大于螺钉、小于螺钉还是正好适合螺钉。然而,我们不能拿两个螺母做比较,也不能拿两个螺钉做比较。我们的问题是要找到每一对匹配的螺钉和螺母。为该问题设计一个算法,它的平均效率必须属于集合O(nlogn)。
思路:随便选一个螺钉,然后在螺母中找到匹配的那个,并把螺母分成大于与小于该螺钉的两组。然后根据匹配的螺母,把螺钉分成两组。遍历,直到全部排好序。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
#include <iostream> #include <algorithm> #include <iomanip> using namespace std; void print(int* array, int n) { for (int i = 0; i < 7; ++i) { std::cout << left; std::cout << setw(3) << array[i] << " "; } std::cout << std::endl; } //--------------------------------------------------- int get_random_nut(int* nuts, int left, int right, int n) { if (!nuts || right < left) return -1; return nuts[left+n]; } //--------------------------------------------------- int get_match_bolt(int* bolts, int nut_pivot, int left, int right, int& index) { if (!bolts || right < left) return -1; for (int i = left; i <= right; ++i) { if (bolts[i] == nut_pivot) { index = i; return bolts[i]; } } return -1; } //--------------------------------------------------- int partition(int pivot, int index, int* array, int left, int right) { if (!array || right <= left) return -1; int indexl(left), indexr(right); while (indexl <= indexr) { while (array[indexl] <= pivot && indexl <= indexr) {++indexl;} while (array[indexr] >= pivot && indexl <= indexr) {--indexr;} if (indexl <= indexr) { std::swap(array[indexl], array[indexr]); ++indexl; --indexr; } } indexr = max(indexr, left); std::swap(array[indexr], array[index]); return indexr; } //--------------------------------------------------- void match_nut_bolt(int* nuts, int*bolts, int left, int right) { // set bolt pivot and it's position, get nut pivot and it's position int bolt_pos(0); int nut_pivot = get_random_nut(nuts, left, right, 0); int bolt_pivot = get_match_bolt(bolts, nut_pivot*10, left, right, bolt_pos); // partition int index_nut = partition(bolt_pivot/10, 0+left, nuts, left, right); print(nuts, 7); int index_bolt = partition(nut_pivot*10, bolt_pos, bolts, left, right); print(bolts, 7); if (index_bolt != index_nut) { std::cout << "error" << std::endl; } // recursive if (left < index_nut-1) { match_nut_bolt(nuts, bolts, left, index_nut-1); } if (right > index_nut+1) { match_nut_bolt(nuts, bolts, index_nut+1, right); } } //--------------------------------------------------- void match_nut_bolt(int* nuts, int* bolts, int n) { if (!nuts || !bolts || n < 2) return; match_nut_bolt(nuts, bolts, 0, n-1); } int main() { int nuts[7] = {5,4,6,2,7,1,3}; int bolt[7] = {40,10,20,50,30,70,60}; //int nuts[7] = {4,1,2,5,3,7,6}; //int bolt[7] = {50,40,60,20,70,10,30}; match_nut_bolt(nuts, bolt, 7); std::cout << "nuts: "; print(nuts, 7); std::cout << "bolts: "; print(bolt, 7); std::cout << std::endl; system("Pause"); }
折半查找
折半查找是一种对有序数组进行查找的O(logn)算法。它是应用分治技术的一个非典型案例,因为在每次迭代中,它只需要解决两个问题中的一个。
代码示例看这里。
二叉树的经典遍历算法 - 前序、中序、后序
递归处理左右两棵子树,可输入分治法。
代码示例看这里。
相关题目
- 巧克力块谜题。有一块
n×m
格的巧克力,我们要把它掰成
n×m
个
1×1
的小块。我们只能沿直线掰,而且不能几块同时掰。设计一个算法用最少的次数掰完巧克力,该次数是多少?用二叉树的特性来论证答案。
思路:掰开巧克力块的过程可以用一棵二叉树来表示。根据性质 nleaf=nc+1 ,内部结点数目为nm-1,也就是掰的数目。
大整数乘法
以增加少量加法运算为代价,减少乘法运算的执行总次数。
- 经典的笔算算法,需要第一个数中的n个数字都分别被第二个数中的n个数字相乘,这样一共要做 n2 次位乘。
- 使用大整数乘法,处理两个n位整数相乘的分治算法,大约需要做 n1.585 次一位数乘法。
思路
两位整数相乘的例子:
得到两位数 a=a1a0 和 b=b1b0 相乘的公式:
其中, c2=a1×b1 ,是它们第一个数字的积, c0=a0×b0 ,是它们第二个数字的积, c1=(a1+a0)×(b1+b0)−(c2+c0) ,是a数字和与b数字和的积减去 c2 与 c0 的和。
推广到两个n位整数a和b的积:
n是一个正的偶数,从中间把两个数字一分为二。a的前半部分记作
a1
,后半部分记作
a0
。b的前半部分记作
b1
,后半部分记作
b0
。
在这种记法中,
a=a1a0
意味着
a=a110n/2+a0
,
b=b1b0
意味着
b=b110n/2+b0
。
得到公式:
其中, c2=a1×b1 ,是它们前半部分的积, c0=a0×b0 ,是它们后半部分的积, c1=(a1+a0)×(b1+b0)−(c2+c0) ,是a两部分和与b两部分和的积减去 c2 与 c0 的和。
如果n/2也是偶数,用同样方法计算c2,c0和c1。
因此,如果n是2的乘方,就得到了一个计算两个n位数积的递归算法。在完美情况下,n变成1时递归停止。或我们认为n已经足够小可以直接计算时,递归也可停止。
计算该递归算法的时间复杂度:
递推式是:
M(n)=3M(n/2),M(1)=1
。求解得
M(2k)=3k
。
所以
M(n)=3log2n=nlog23≈n1.585
Strassen矩阵乘法
以增加少量加法运算为代价,减少乘法运算的执行总次数。
Strassen算法只需要做7次乘法就能计算出两个2阶方阵的积,但比基于定义的算法要做更多次的加法。
利用分治技术,该算法计算两个n阶方阵的乘法时需要做 n2.807 次乘法。蛮力法需要 n3 。
思路
利用公式:
扩展:
假设n是2的乘方,A和B是两个n阶方阵(如果n不是2的乘方,矩阵可以用为0的行或列来填充)。我们可以把A, B和C分别划分为4个n/2阶的子矩阵。
递归解决。

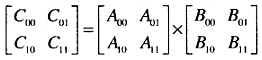
最近对问题
平面上的n个点,求两个点之间最近的距离。
思路
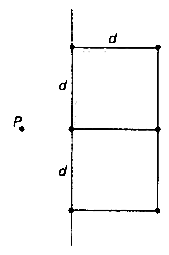
画一条垂直线x=c,把定点分为两个包含n/2个点的子集,分别在直线的左侧+直线或右侧+直线上。
遵循分治方法,可以递归地求出左子集和右子集的最近对。设d1和d2分别是S1和S2的点对中的最小距离,d=min{d1,d2}。但是,d不一定是S1和S2中所有点对的最小距离,因为距离最近的两个点可能分别位于分界线的两侧。
检查是否存在这种情况,限制在以x=c为对称的、宽度为2d的垂直带中,因为任何其他点对的距离都大于d。
对于左子集S1中的每一个点P,在该区间内有可能的点不会超过6个。将S1和S2中的点各自按照y轴坐标以升序排列(可以想象成这些点在分界线上的投影),这样合并时就可以合并两个已经排好序的表。
迭代时, 顺序处理S1中的点,同时一个指针在S2列表的宽度为2d的区间中来回移动,取出最多6个候选点,计算它们和S1当前点P之间的距离。

计算时间复杂度:
T(n)=2T(n/2)+M(n),其中M(n)是上述合并的过程,时间复杂度为O(n)。
应用对O的主定理(其中,a=2,b=2,d=1),得到T(n)属于O(nlogn)。
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 | #include <vector> #include <iterator> #include <iostream> #include <algorithm> using namespace std; // structure of point struct Point { float m_x; float m_y; Point (float x, float y) : m_x(x), m_y(y){} void print_point() { std::cout << "(" << m_x << "," << m_y << ")"; } }; // calculate pow of distance of two points float distance(Point* a, Point* b) { if (!a || !b) return FLT_MAX; return pow((a->m_x - b->m_x), 2.0f) + pow((a->m_y - b->m_y), 2.0f); } // when points are less than four use brute force way float brute_force_nearest_pair(std::vector<Point*>::iterator start, std::vector<Point*>::iterator end, std::pair<Point*, Point*>& nearest) { if (end - start < 1) return FLT_MAX; float md(FLT_MAX); for (auto i = start; i <= end-1; ++i) { for (auto j = i+1; j <= end; ++j) { float d(distance(*i, *j)); if (d < md) { md = d; nearest.first = *i; nearest.second = *j; } } } return md; } // divide and conquer way to find nearest pair of points float find_nearest_pair(std::vector<Point*>::iterator start, std::vector<Point*>::iterator end, std::pair<Point*, Point*>& nearest) { // less than 4, brute force if (end - start <= 3) {return brute_force_nearest_pair(start, end, nearest);} // find mid number of points std::vector<Point*>::iterator mid(start); advance(mid, (end - start)/2); // divide into two parts std::pair<Point*, Point*> n1, n2; float d1(find_nearest_pair(start, mid-1, n1)); float d2(find_nearest_pair(mid, end, n2)); // get min of both parts: d float d(min(d1, d2)); // record nearest and min distance nearest = d1 > d2 ? n2 : n1; float md(d); // find all points in S2 which is close to mid point with distance less than d std::vector<Point*> close_to_mid_points_in_s2; for (auto i = mid; i <= end; ++i) { if ((*i)->m_x - (*mid)->m_x <= d) { close_to_mid_points_in_s2.push_back(*i); } } // for all points p in S1 find if there are points in close S2 collection that have distances with p less than d for (auto i = start; i <= mid-1; ++i) { if ((*mid)->m_x - (*i)->m_x <= d) { for (auto j = close_to_mid_points_in_s2.begin(); j < close_to_mid_points_in_s2.end(); ++j) { float temp(distance(*i, *j)); if ( temp < md) { // update mid distance and nearest points pair md = temp; nearest.first = *i; nearest.second = *j; } } } } // return final mid distance return md; } int main() { std::vector<Point*> points; Point a(0,1), b(0,11), c(0,3), d(0,10), e(0,6); points.push_back(&a); points.push_back(&b); points.push_back(&c); points.push_back(&d); points.push_back(&e); // sort points collection according to value of coordinate y. sort(points.begin(), points.end(), [](Point* a, Point* b){return a->m_y < b->m_y;}); std::pair<Point*, Point*> nearest; float dist = find_nearest_pair(points.begin(), points.end()-1, nearest); std::cout << "distance: " << sqrt(dist) << std::endl; std::cout << "points: "; nearest.first->print_point(); std::cout << ", "; nearest.second->print_point(); std::cout << std::endl; system("Pause"); } |
凸包问题
求能够完全包含平面上n个给定点的凸多边形。此处的分治算法有时候也称为快包。
思路
假设
P1
到
Pn
是平面上按照x轴坐标升序排列的点集。那么显而易见,最左面的点
P1
和最右面的点
Pn
一定是该集合的凸包顶点。
从
P1
到
Pn
的直线把点集分为两部分,上方的S1(上包)和下方的S2(下包),两者求法相同。
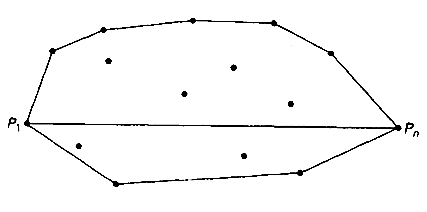
求上包的过程:
- 如果S1为空,上包就是以 P1 和 Pn 为端点的线段。
- 如果S1不空,某算法找到S1中的顶点 Pm ,它是距离直线 P1Pn 最远的点。不难证明, Pm 是上包的顶点,包含在 △P1Pm 中的点不可能是上包的顶点。
- 于是可以递归继续计算 P1Pm 的上包S1.1和 PmPn 的上包S1.2。最后把它们连接起来,就得到整个上包。
上文提到的某算法是一个解析几何知识:如果
P1=(x1,y1),P2=(x2,y2),P3=(x3,y3)
是平面上的任意三个点,那么三角形
△P1P2P3
的面积等于下面这个行列式绝对值的二分之一。
当且仅当点
P3=(x3,y3)
在直线
P1P2
左侧时,该表达式符号为正。
因此使用此公式可知,一个点是否位于两个点确定的直线的两侧,这个点到这根直线的距离。
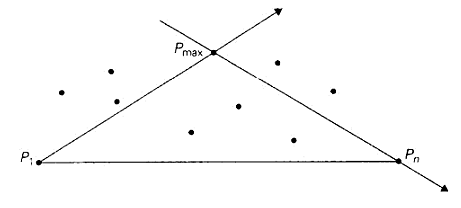
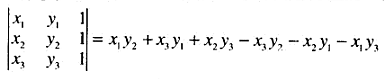
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 | #include <list> #include <iterator> #include <iostream> #include <algorithm> using namespace std; // structure of point struct Point { float m_x; float m_y; Point (float x, float y) : m_x(x), m_y(y){} void print_point() { std::cout << "(" << m_x << "," << m_y << ")"; } }; //--------------------------------------------------- float calculate_formular(Point* a, Point* b, Point* c) { return a->m_x*b->m_y + c->m_x*a->m_y + b->m_x*c->m_y - c->m_x*b->m_y - b->m_x*a->m_y - a->m_x*c->m_y; } //--------------------------------------------------- void convex_hull_problem_up(list<Point*> points, Point* start, Point* end, list<Point*>& convex_points) { list<Point*> left_points; float left_max(FLT_MIN); Point* left_p(NULL); // find all points higher than line start->end. for (auto it = points.begin(); it != points.end(); ++it) { float val(calculate_formular(start, end, *it)); if (val > 0.0f) { left_points.push_back(*it); if (val > left_max) { left_max = val; left_p = *it; } } } // if there is no higher point add line end in convex hull if (left_points.empty()) { convex_points.push_back(end); return; } // recursive convex_hull_problem_up(left_points, start, left_p, convex_points); convex_hull_problem_up(left_points, left_p, end, convex_points); } //--------------------------------------------------- void convex_hull_problem_down(list<Point*> points, Point* start, Point* end, list<Point*>& convex_points) { list<Point*> right_points; float right_max(FLT_MAX); Point* right_p(NULL); // find all points lower than line start->end. for (auto it = points.begin(); it != points.end(); ++it) { float val(calculate_formular(start, end, *it)); if (val < 0.0f) { right_points.push_back(*it); if (val < right_max) { right_max = val; right_p = *it; } } } // if there is no lower point add line end in convex hull if (right_points.empty()) { convex_points.push_back(start); return; } // recursive convex_hull_problem_down(right_points, right_p, end, convex_points); convex_hull_problem_down(right_points, start, right_p, convex_points); } //--------------------------------------------------- void convex_hull_problem(list<Point*> all_points, list<Point*>& convex_points) { Point* start = *all_points.begin(); Point* end = *all_points.rbegin(); // up convex hull convex_hull_problem_up(all_points, start, end, convex_points); // down convex hull convex_hull_problem_down(all_points, start, end, convex_points); } //--------------------------------------------------- int main() { Point a(-1, 0); Point b(0, 1); Point c(1, 0); Point d(0, -1); Point e(0, 0); Point f(-0.7f, 0.5f); Point g(-0.8f, -0.5f); Point h(0.7f, 0.5f); list<Point*> all_points; all_points.push_back(&e); all_points.push_back(&d); all_points.push_back(&a); all_points.push_back(&b); all_points.push_back(&c); all_points.push_back(&f); all_points.push_back(&g); all_points.push_back(&h); all_points.sort([](Point* a, Point* b){return a->m_x < b->m_x;}); list<Point*> convex_points; convex_hull_problem(all_points, convex_points); for (auto it = convex_points.begin(); it != convex_points.end(); ++it) { (*it)->print_point(); cout << " "; } cout << endl; system("Pause"); } |
leetcode相关题目
Pow(x,n)
Sqrt(x)
[Tree] | Convert Sorted Array to Binary Search Tree
Find the Duplicate Number
[1] 算法设计与分析基础(第2版)
[2] leetcode















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









