









1、 进入ubuntu 命令台
这里我分了一个ubuntu-node的镜像出来,如果你没有的话你需要分一个镜像出来重命名为ubuntu-node
docker exec -it ubuntu-node /bin/bash

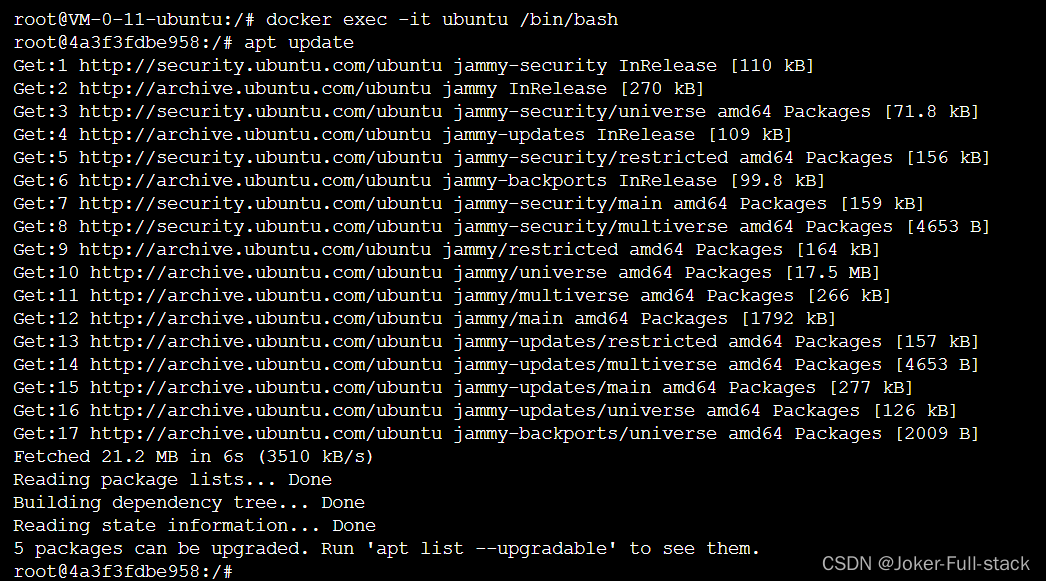
2、首次使用先更新下
apt update
3、安装node
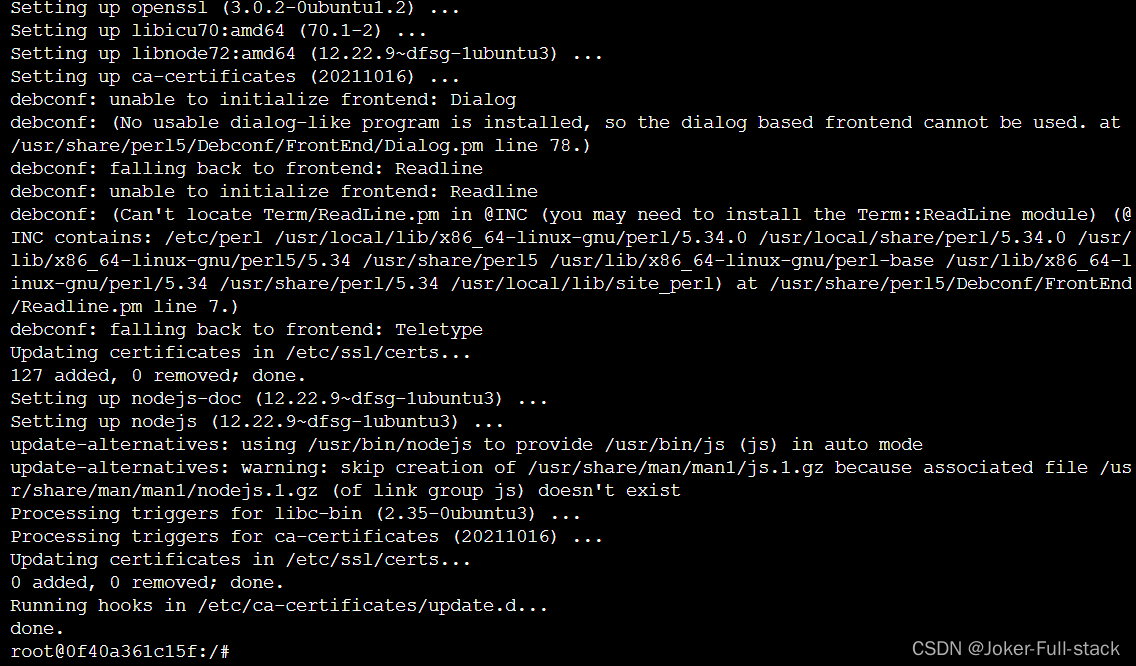
apt install nodejs
出现以下信息或没有报错信息表示安装成功
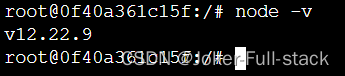
4、验证node 版本
node -v
5、提交镜像为新副本(方便reuse)
像node、apache、mysql等应用可能每个镜像都会有需求的。对于这样的镜像,我们是不需要重复去安装的。只需要将第一次装完的node提交为一个副本,使用以下语句
代码语句
docker commit -m "副本镜像名" -a "创建人" container_id repository/new_image_name
比如下面的语句
docker commit -m "added Node.js" -a "Joker" 4a3f3fdbe958 joker/ubuntu-node
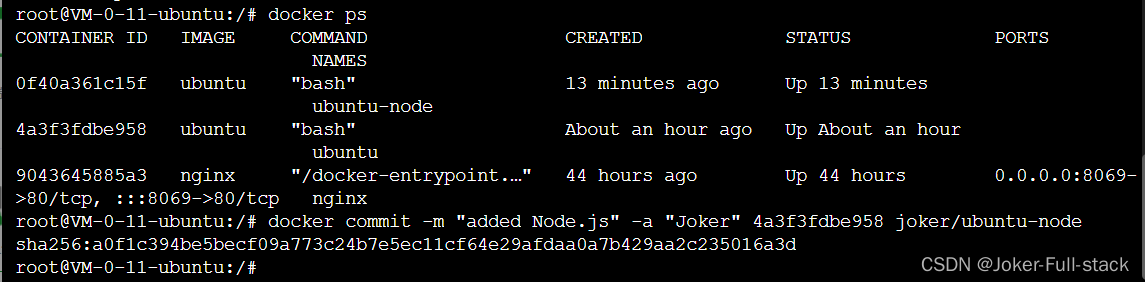
执行后发现多了一个joker/ubuntu-node的镜像
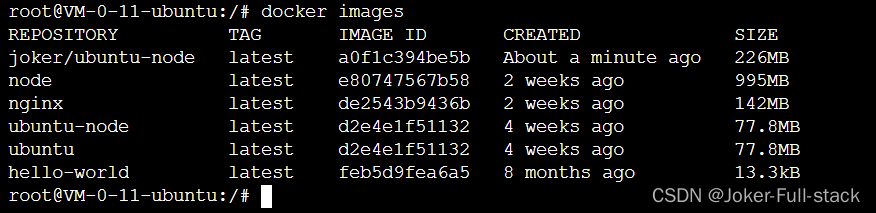


















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











