







solr 7配置中文分词器
这里示例配置solr官方提供的Smartcn的中文分词、IK的中文分词及拼音分词
1、配置smartcn中文分词器
solr安装包有提供Smartcn中文分词架包,在SOLR_ROOT/contrib/analysis-extras/lucene-libs/下,我这里使用solr 7.2.1,所以架包名称为lucene-analyzers-smartcn-7.2.1.jar
- 把smartcn中文分词器架包复制到solr项目的WEB-INF/lib目录下
cp /usr/local/solr-7.2.1/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-7.2.1.jar /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/配置 fieldType
找到solrhome/${collection}/conf/managed-schema
添加smartch中文分词器配置
<schema>
<!-- 配置中文分词器 -->
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
</schema>重启tomcat
新添加架包一定要重启tomcat
查看效果
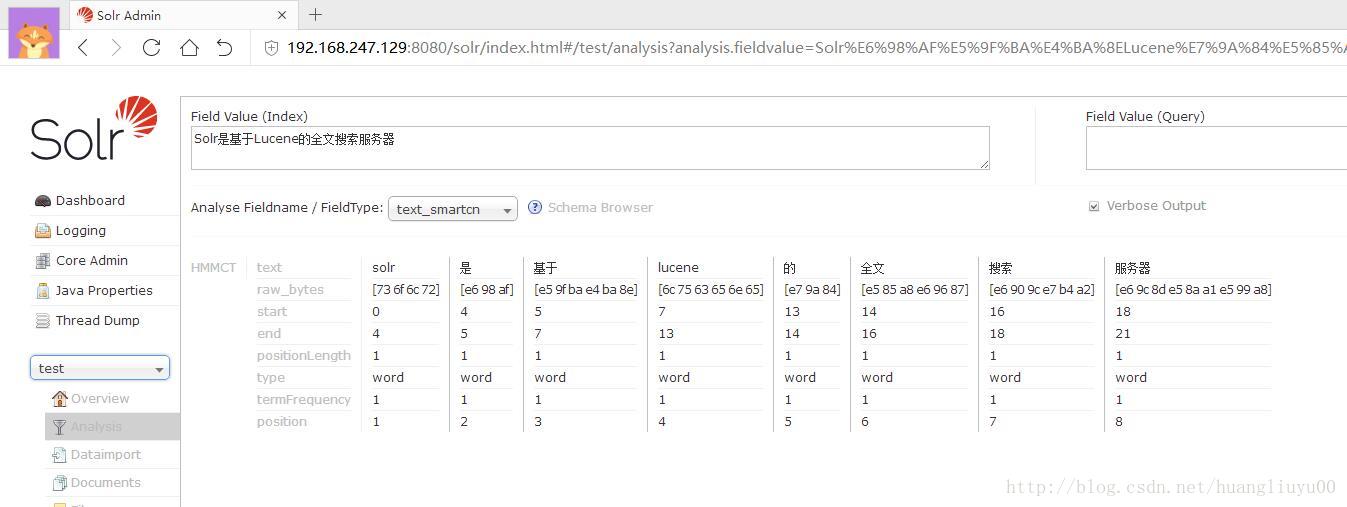
2、配置IK Analyzer中文分词器
先下载 IK Analyzer中文分词器架包及相关配置文件。
听说I分词器不支持**solr 6、7搭建成的**solrcloud,待验证。
里面包括IK Analyzer 2个架包:ik-analyzer-solr5-5.x.jar、solr-analyzer-ik-5.1.0.jar
IK配置文件 IKAnalyzer.cfg.xml、ext.dic、stopword.dic
IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>准备IK中文分词器环境
- 把IK中文分词器架包复制到solr项目的WEB-INF/lib目录下
- 把IK分词器相关配置文件复制到solr项目WEB-INF/classes/ 目录下
配置 fieldType
找到solrhome/${collection}/conf/managed-schema
在solr scheam文件中里添加 IK fieldType。
<schema>
<!-- IK分词 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false"/>
</analyzer>
</fieldType>
</schema>说明:当 useSmart=”false”,分词粒度较小,分词后个数多;当 useSmart=”true”,分词粒度大,分词后个数据少。
效果
分词的效果比官方提供的smartcn中文分词要好,去掉了标点符号,去掉了 的 等词义不重要的字。
3、拼音分词器
先下载 IK拼音分词器架包:pinyin4j-2.5.0.jar、pinyinAnalyzer4.3.1.jar
把相关架包复制到solr项目的WEB-INF/lib目录下
配置fieldType
找到solrhome/${collection}/conf/managed-schema
在solr scheam文件中里添加 IK fieldType
<schema>
<!-- IK 拼音分词 -->
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
</fieldType>
</schema>














 166
166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









