







0 概述
ElasticSearch是一个基于Lucene的实时数据分析全文搜索工具。它提供了一个分布式的多用户能力的全文搜索引擎,基于RESTful web接口。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官网
1 基本概念介绍
- Cluster(集群)
当数据量或者查询压力超过单机负载时候,需要多个节点来协同处理,所有这些节点组成的系统成为集群(cluster)。集群同时也是无间断提供服务的一种解决方案。即便在某些节点因为宕机或者不可用时。在ElasticSearch配置一个集群很容易。 - 节点
单个ElasticSearch 服务实例称为节点。 - index(索引)
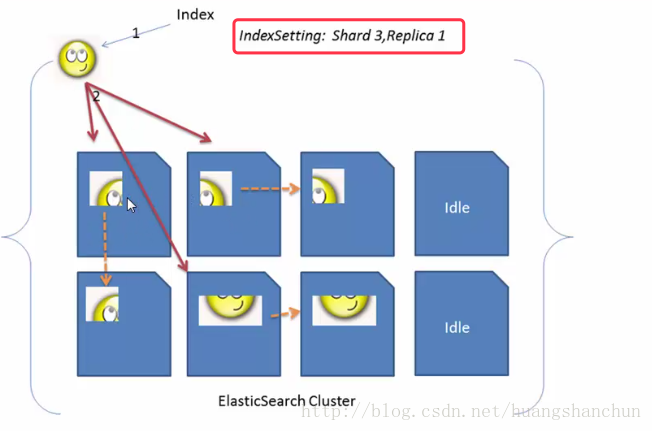
ElasticSearch将它的数据存储在一个或者多个索引(index)中。用关系数据来类比,索引就像是数据库。可以向索引中写入文档或者从索引中读取文档,并通过在其内部使用Luence将数据写入索引或者从索引中检索。值得说明的是:ElasticSearch中的索引可能由一个或多个Luence索引构成,具体细节由ElasticSearch的索引分片(shard)、复制(replica)机制及配置决定。 - type(类型)
一个索引中,可以定义一种或者多种类型。用关系数据库来类比,类型就像数据库中的表。 - document(文档)
文档是ElasticSearch世界中的主要实体。用关系数据来类比,文档就像是数据库中表数据行即数据库中的表的实体。文档由字段构成,每个字段都有它的字段名以及一个或多个字段值(这种情况下,该字段被称为多值的,即文档中有多个同名字段)。从客户端角度来看,文档就是一个JSON对象。 - field(字段)
字段是ElasticSearch中的最小单位,其包含字段名称和内容。用关系数据库来类比,字段就像数据库中的表中的列。 - shard(分片)
ElasticSearch将索引分成若干份,每个部分就是一个shard;这么做原因是:1)一个索引可能会超过单个节点容量2)如果数据都放在一个节点行那么请求也会变慢。 - replica(副本)
ElasticSearch为了防止数据丢失以及负载均衡,就采用的副本这一方案,即为每一个分片创建冗余的副本。
gateway (网关)
在ElasticSearch 的工作过程中,关于集群的状态,索引设置的各种信息都会被收集起来,并在网关中持久化。mapping(映射)
创建索引的时候,可以预先定义字段的类型以及相关属性。这样会让索引建立得更加细致和完善。
官方文档
2 ElasticSearch和关系数据库
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
| 关系数据库 | Elasticsearch |
|---|---|
| 数据库 database | 索引 index |
| 表 table | 类型 type |
| 数据行 row | 文档 document |
| 数据列 column | 字段 filed |














 1883
1883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









