






实验 1:线性模型实现
实验要求
(1)对问题进行简单描述并给出线性判别分析和对数几率回归解决分类问题的原理;
(2)将问题相关数据集划分成训练集和测试集;
(3)给出线性判别分析和对数几率回归解决手写数字识别问题的代码;
(4)对训练后的模型进行交叉验证,进而对不同模型进行比较和评估;
(5)实验报告除了姓名、专业、学号和班号之外,其他所有地方要求用手写(不允许打印)。
具体要求
(1)手写数字识别问题的数据可以通过如下方式生成:
from sklearn.datasets import load_digits
digits = load_digits()
(2)“实验原理”中主要填写如下内容:
a)对手写数字识别问题进行简单的描述;
b)对数据集(保存在变量 digits 里)进行描述:给出数据集样本的个数、样本属性是什么、给出每个样本对应特征向量的维数(或属性个数)、样本标记集合是什么;
c)简单说明下对数几率回归和线性判别分析解决多分类问题的原理,以及如何使用它们解决手写数字识别问题。
(3)“试验过程或内容、结果、分析、讨论、结论”中填写 Python 代码,具体要
求:
a)引入手写数字识别问题的数据,并将数据分成训练集和测试集;
b)引入 Scikit-learn 中对数几率回归模块和线性判别分析模块,并定义相关模型;
c)通过训练集训练相关模型,并利用训练后的模型预测测试集样本的标记和对应的概率(要求利用模型的.predict()方法和.predict_proba()方法)
d)通过如下方式验证和评估模型:
对训练后的两个模型在测试集上应用.score()方法,然后利用返回的结果评价
哪种模型效果更好;
对未经训练的对数几率回归模型和线性判别分析模型应用 10 折交叉验证,通
过验证结果评价下哪种模型效果更好。
注意:在进行 10 折交叉验证时,数据集应当是 digits 中保存的原始数据集合,而不是划分后的训练集。另外,交叉验证中的模型是没有进行训练的模型。
(4)“实验结果”中填写如下内容:
a)两个训练后的模型在测试集上应用.score()方法后返回的结果,并指出依据结果哪种模型效果更好;
b)对两个模型应用 10 折交叉验证,给出交叉验证返回的结果,并指出依据结果哪种模型效果好。
(5)“实验总结”填写内容:
本次实验主要做了什么(与实验目的和要求对照),掌握了什么(与实验目的和要求对照),以及还存在哪些不足?
代码实现
#导入所需要的库包
from sklearn.datasets import load_digits
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import pandas as pd
#数据加载进digits
digits = load_digits()
#查看数据集属性
print(digits.keys())
print(digits.data.shape)
'''结果显示:dict_keys(['data', 'target', 'frame', 'feature_names',
'target_names', 'images', 'DESCR'])'''
#用pandas处理存储数据
#feature_names为列,是数据集特征向量名称
data = pd.DataFrame(digits.data, columns = digits.feature_names)
#class列中存储数据的标签
data['class'] = digits.target
print(data)
得到结果

#取两个属性进行线性判别分析(属性选择)
X = data[data.columns.drop('class')]
Y = data['class']
print(X)
print(Y)
#开始划分数据集(线性分析模块)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y)
#n_components:一个整数。指定了数组降维后的维度(该值必须小于n_classes-1)
#model即训练出的线性模型
model = LinearDiscriminantAnalysis(n_components = 2)
model.fit(X_train, Y_train)
#开始对数据进行预测
#根据上述代码效果已知当前数据金数据共有1797个,但是未知测试集数据个数
#print(X_test)
#[450 rows x 64 columns]
#print(Y_test)
#Name: class, Length: 450, dtype: int32
print("X_test预测值为:\n")
print(model.predict(X_test))
#print("X_test预测对应标签值概率为:\n")
print(model.predict_proba(X_test))
#.score()函数是指预测成功的概率
print(model.score(X_test, Y_test))
得到结果

#对数几率回归方式训练模型
#log即训练出的对数模型
log = LogisticRegression(random_state=0, solver = 'newton-cg')
log.fit(X_train, Y_train)
print(log.score(X_test, Y_test))
结果是0.9577777777777777
#可视化尝试(其实也就看个新鲜)
plt.gray()
plt.matshow(digits.images[0])
plt.show()

要求十折交叉验证
from sklearn.model_selection import cross_val_score
print("线性模型十折验证运算结果:")
#cross_val_score("模型名称",测试集1,测试集2,cv=“折数”)
print(cross_val_score(model,X_test, Y_test, cv=10))
df1 = cross_val_score(model,X_test, Y_test, cv=10)
#mean()函数属于pandas库,作用是计算矩阵内均值。详情自行查阅
print("求出均值为:")
print(df1.mean())

print("对数模型十折验证运算结果:")
print(cross_val_score(log,X_test, Y_test, cv=10))
df2 = cross_val_score(log,X_test, Y_test, cv=10)
print("求出均值为:")
print(df2.mean())
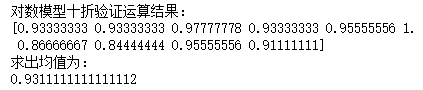
所以根据.score()函数结果来比较的话是对数模型更优秀
十折交叉验证结果也应该是对数更优秀
不同的训练集与测试集划分方法结果不同,数据结果不必强求一样















 1056
1056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









