







目录
一、提出任务
- 分组求TopN是大数据领域常见的需求,主要是根据数据的某一列进行分组,然后将分组后的每一组数据按照指定的列进行排序,最后取每一组的前N行数据。
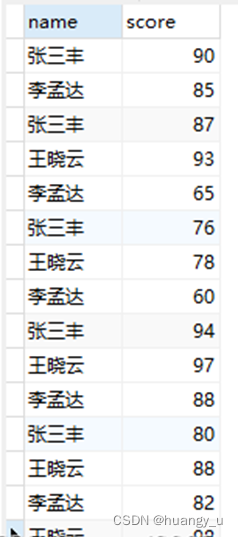
- 有一组学生成绩数据
-
张三丰 90 李孟达 85 张三丰 87 王晓云 93 李孟达 65 张三丰 76 王晓云 78 李孟达 60 张三丰 94 王晓云 97 李孟达 88 张三丰 80 王晓云 88 李孟达 82 王晓云 98 - 同一个学生有多门成绩,现需要计算每个学生分数最高的前3个成绩,期望输出结果如下所示:
-
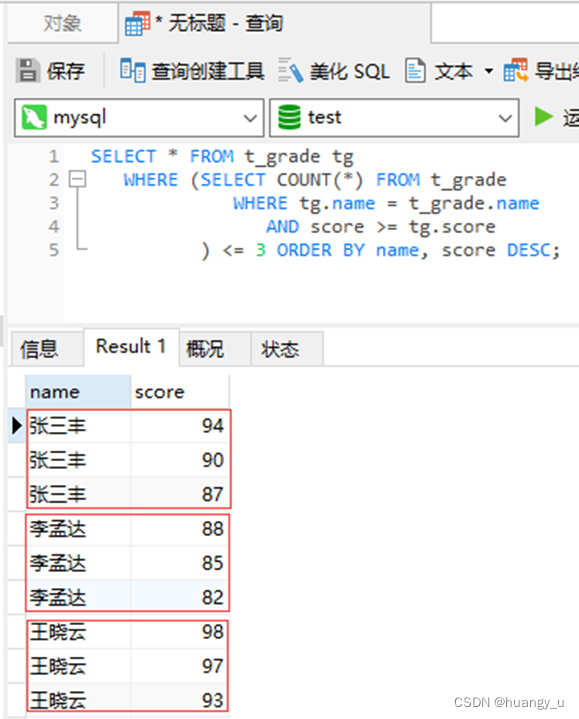
张三丰:94 张三丰:90 张三丰:87 李孟达:88 李孟达:85 李孟达:82 王晓云:98 王晓云:97 王晓云:93 - 数据表
t_grade
- 执行查询

- 预备工作:启动集群的HDFS与Spark
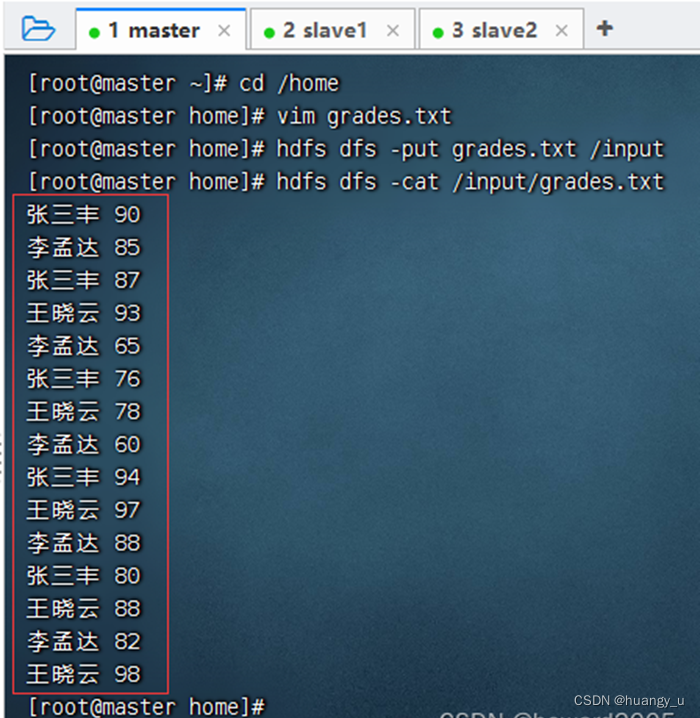
- 将成绩文件 -
grades.txt上传到HDFS上/input目录
二、完成任务
(一)新建Maven项目
- 设置项目信息(项目名、保存位置、组编号、项目编号)
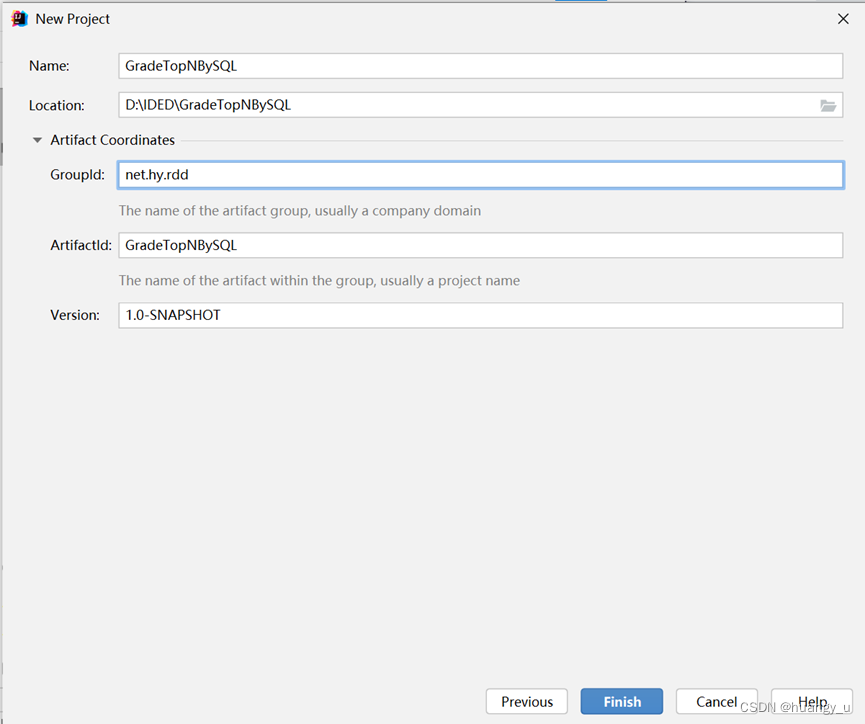
- 单击【Finish】按钮
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









