






GPT-1介绍
发展历程
GPT(Generative Pre-Training)是由Open AI 提出的预训练大语言模型。采用了两阶段模型训练过程。
-
基于大量数据进行无监督的模型预训练
-
基于多种具体任务进行有监督微调(Fine-tuning)
| 模型 | 参数量 | 样本数据量 | 发布时间 |
|---|---|---|---|
| GPT | 1.17亿 | 5GB | 2018.6 |
| GPT-2 | 15亿 | 40GB | 2019.2 |
| GPT-3 | 1750亿 | 45TB | 2020.5 |
GPT-1 原理
GPT的的训练过程氛围两个阶段,第一阶段是基于大量文本进行无监督预训练,得到具有普适性的文本特征。第二阶段是在常见的具体任务场景(比如文本分类、序列标注、摘要生成等)下进行Fine-tuning以解决目标任务。表现形式如下
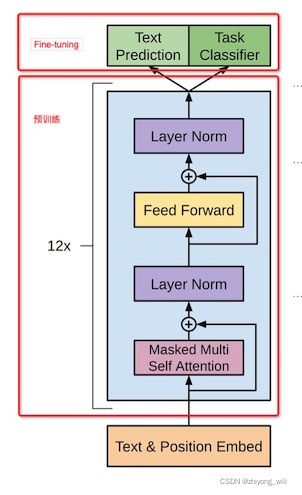
第一阶段:模型预训练
GPT预训练采用的是单向语言模型,即从左到右序列输入的形式。为了获取强大的表征能力,GPT借鉴了Transformer的Decoder模块并进行了改进----只使用Masked Multi-Head Attention(Transformer的Decoder既有Multi-Head Attention,也有Masked Multi-Head Attention)。
为什么使用Transformer的Decoder模块?
因为GPT是单向语言模型,而非BERT系列的双向语言模型。只能看到当前词之前的文本信息。这和Masked Multi-Head Attention的功能一致。
在训练过程中,GPT采用的是语言模型的训练思路,即通过上文预测当前词。给定一个无标签词序列 U = u 1 , u 2 , . . . , u n U={u_1, u_2,...,u_n} U=u1,u2,...,un ,语言模型的目标函数为
L ( U ) = ∑ i l o g P ( u i ∣ u i − k , u i − k + 1 , . . . , u i − 1 ; θ ) L(U)=\sum\limits_i{log} P({u_i}|{u_{i - k}},{u_{i - k + 1}},...,{u_{i - 1}};\theta) L(U)=i∑logP(ui∣ui−k,ui−k+1,...,ui−1;θ)
其中k是滑动窗口的大小,P是条件概率, θ \theta θ 是模型参数。
GPT模型的输入为
h 0 = U W e + W p h_0=UW_e+W_p h0=UWe+Wp
其中 h 0 h_0 h0 表示模型的输入,0代表输入层。 W e W_e We 表示所有词的词向量矩阵, U W e UW_e UWe 则代表当前输入序列所有词的词向量矩阵。 W p W_p Wp 代表位置向量矩阵。
假设当前序列长度为10,词汇表大小为6000,embedding的维度为128。则 W e W_e We 的大小为 6000×128, U W e UW_e UWe 的大小为 10×28, W p W_p Wp 的大小为 10×128.
GPT中的位置向量position embedding采用的随机初始化,让模型自己学习的方式,而不是Transformer的正弦余弦函数。
得到输入 h 0 h_0 h0 之后,将 h 0 h_0 h0 依次传入设计好的Transformer Decoder中,最终得到 h n h_n hn 。
h l = t r a n s f o r m e r b l o c k ( h l − 1 ) v . t . 1 = < l < = n h_l= transformer block(h_{l-1}) \qquad v.t. \; 1=<l<=n hl=transformerblock(hl−1)v.t.1=<l<=n
其中n为使用的层数。得到 h n h_n hn,之后再预测下一个单词的概率
P ( u ) = s o f t m a x ( h n W e T ) P(u) = softmax(h_nW_e^T) P(u)=softmax(hnWeT)
最后输出的大小为10×6000。代表输入的10个词分别预测对应位置的下一个词。
整体流程:将序列中的 num个词的词向量矩阵 U W e UW_e UWe 加上位置嵌入 W p W_p Wp, 输入到 Transformer Decoder中,num个词分别预测该位置的下一个词。
第二阶段:有监督微调 Fine-Tuning
预训练阶段我们得到了一个包含通用知识的预训练模型,现在需要设计具体任务进行模型的微调。以分类任务为例,假设输入的文本序列为 x 1 , x 2 , . . . , x n x_1, x_2,...,x_n x1,x2,...,xn ,其对应的分类标签为 y y y。
现在将 x 1 , x 2 , . . . , x n x_1, x_2,...,x_n x1,x2,...,xn输入Transformer Decoder模型,得到输出层最后一个时刻的输出 h l n h_l^n hln ,现新增一个Softmax层(参数为 W y W_y Wy)进行分类操作。最后用交叉熵计算损失并进行反向传播调整预训练模型的参数以及 W y W_y Wy的参数。等价于最大似然估计:
P ( y ∣ x 1 , x 2 , . . . , x n ) = s o f t m a x ( h l n W y ) P(y|x_1,x_2,...,x_n)=softmax(h_l^nW_y) P(y∣x1,x2,...,xn)=softmax(hlnWy)
微调阶段需要最大化下面的函数:
L ( C ) = ∑ x , y log P ( y ∣ x 1 , x 2 , . . . , x n ) L(C) = \sum\limits_{x,y} {\log P(y|{x_1},{x_2},...,{x_n})} L(C)=x,y∑logP(y∣x1,x2,...,xn)
为了提升模型的泛化性,GPT使用了Multi-Task Leanrning,在微调过程也考虑到预训练过程的损失函数,整体损失函数为
L t o t a l ( C ) = L ( C ) + λ L ( U ) L_{total}(C)=L(C)+\lambda L(U) Ltotal(C)=L(C)+λL(U)
对于预训练的损失函数 L ( U ) L(U) L(U),使用的数据仍然是当前有监督任务的输入数据,并且只使用 x 1 , x 2 , . . . , x n x_1, x_2,...,x_n x1,x2,...,xn,不使用标签信息 y y y。
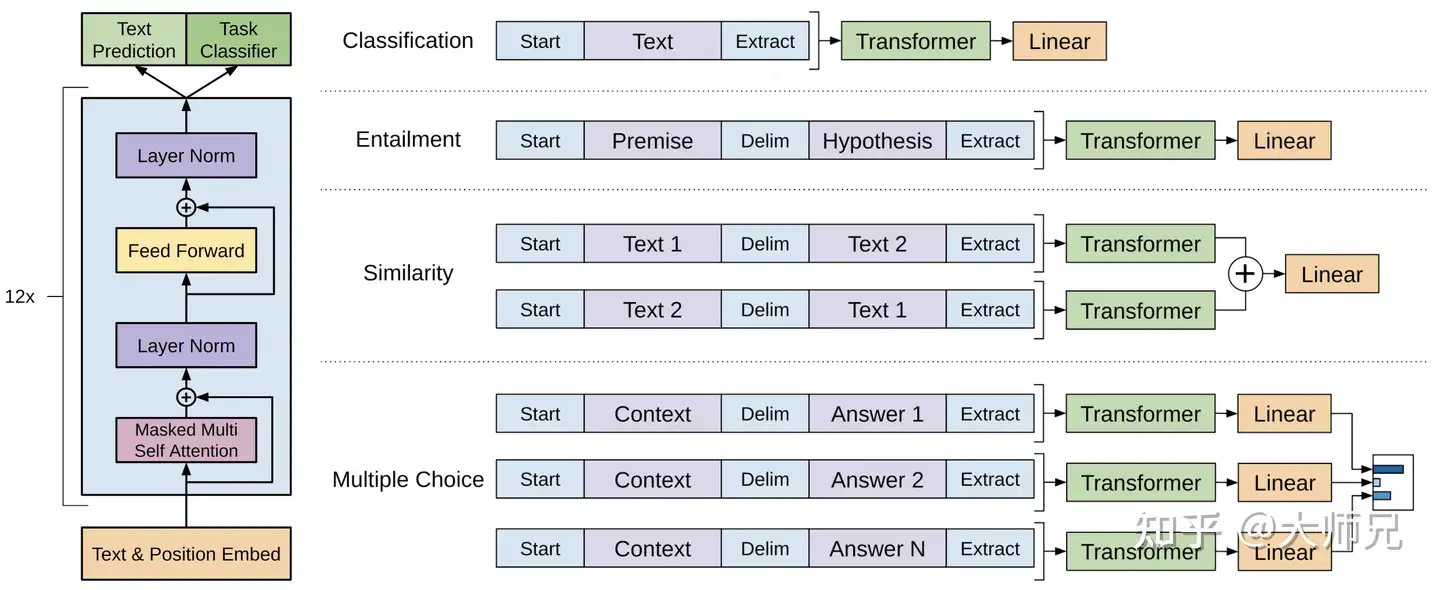
不同任务的输入形式
接下来介绍微调阶段主要的四种任务形式
-
分类任务:将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接层得到目标标签的概率值。
-
自然语言推理:将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果。
-
语义相似度:输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果(二分类–是否相似)。
-
问答和知识推理:将 包含n个选项的问题抽象化为n个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。
GPT使用的数据集
GPT-1使用了BooksCorpus数据集,这个数据集包含 本没有发布的书籍。作者选这个数据集的原因有二:1. 数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系;2. 这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力。
GPT模型细节
-
使用了12层Transformer,每个Transformer块使用12个头。
-
位置编码使用的可学习方式,而不是正余弦函数。
-
使用字节对编码(BPE)处理数据,共有40000个字节对。
-
词编码embedding长度为768。
-
使用的激活函数为GLEU。
-
训练期间的batchsize为64,epoch为100,学习率为 2.5 e − 4 2.5e^{-4} 2.5e−4。序列长度为512。
-
模型参数量1.17亿。
GPT的特点
优点
-
使用Transformer构造强大的特征抽取器,能够有效捕捉长距离记忆信息,且相较于传统的RNN系列方法更易于并行化。
-
预训练和微调两阶段模式,基于通用的预训练模型进行下游任务的微调,避免了针对各个任务进行定制设计的麻烦。
缺点
- GPT属于单向语言模型,根据已知的信息预测当前词,无法利用后面词的信息。














 880
880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









