






1. GPT的结构
GPT是Transformer的decoder部分,但是却做了一点结构上的改动,因为GPT只使用的是decoder,那么encoder的输入就不需要了,所以去掉了encoder-decoder 多头自注意力层,剩下了单向掩码多头自注意力层和前馈层。具体模块图示如下,它包含了12个decoder的叠加
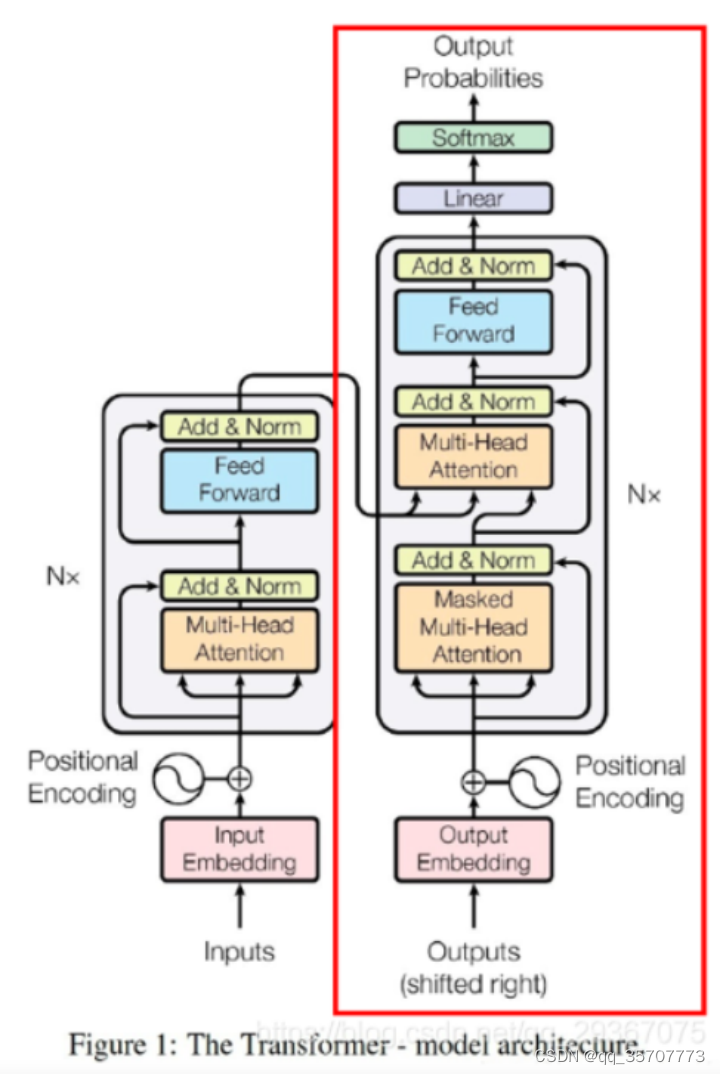
整体看来呢,decoder还是一个类似RNN的时间上递归计算结构,虽然每一步是并行计算的。模型在第t时间步时,只知道t-1时间步及以前的输出情况,而不知道t时间步及以后的输出情况。
2. AR与AE语言模型
AR: Aotoregressive Lanuage Modeling,又叫自回归语言模型。它指的是,依据前面(或后面)出现的tokens来预测当前时刻的token,代表模型有GPT等。
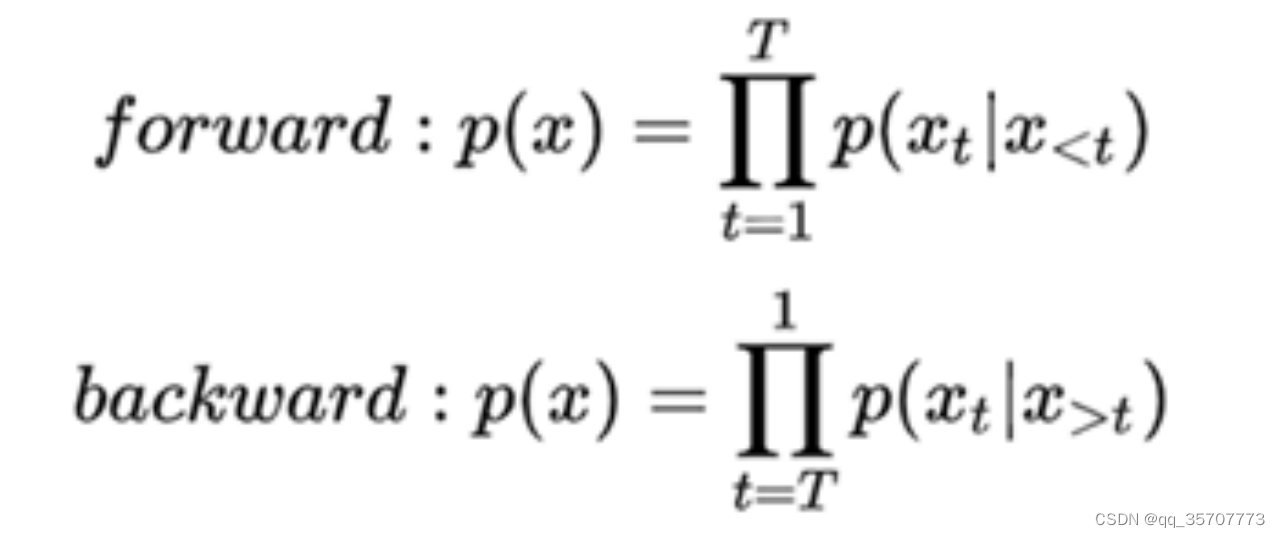
优点:对自然语言生成任务(NLG)友好,天然符合生成式任务的生成过程。
缺点:它只能利用单向语义而不能同时利用上下文信息。
AE:Autoencoding Language Modeling,又叫自编码语言模型。通过上下文信息来预测当前被mask的token,代表有BERT,Word2Vec(CBOW)。
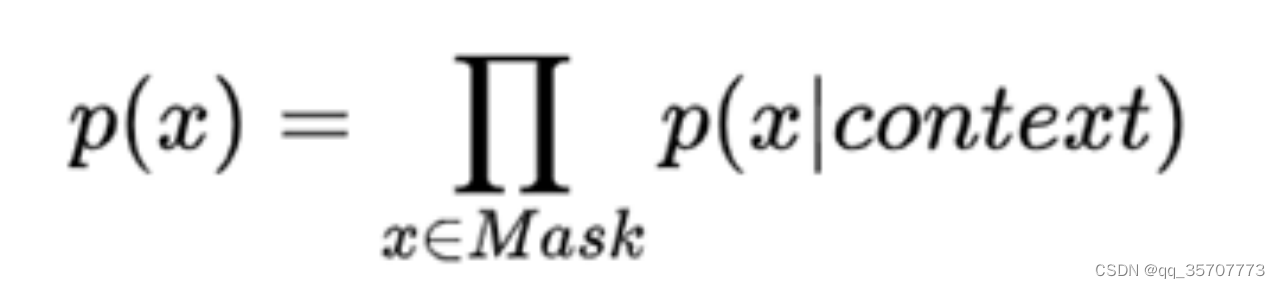
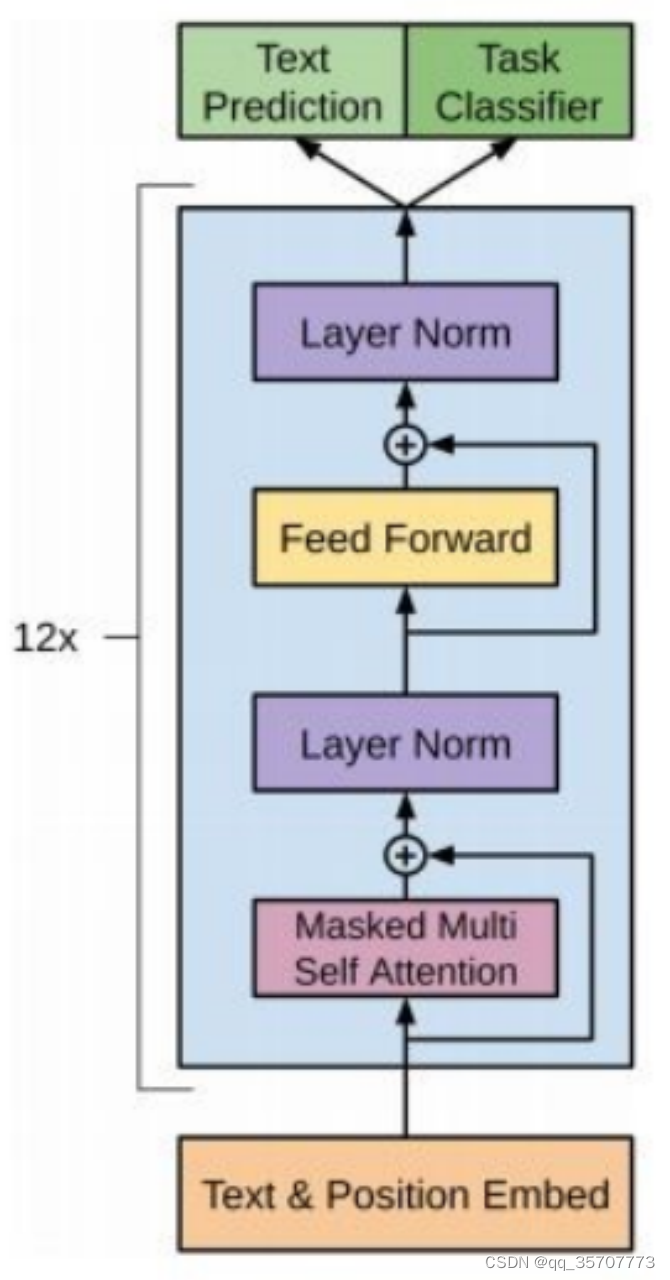
3. GPT的预训练过程
最后经过softmax输出当前生成的token的在词典中的概率,最后极大化似然函数
4. GPT-2的改进
1. 不再针对不同任务分别进行微调建模,模型会自动识别出来需要做什么任务。学习的是一个通用NLP模型。
2. GPT-2使用更多的训练数据,并且都是带有任务信息的数据。
3. 更大的模型规模,堆叠的层数、隐层的维度
4. 每个sub-block最开始加一个layernorm,在最终自注意块之后添加了额外的层标准化,残差层的参数初始化根据网络深度进行调节。(层标准化,自注意力,残差连接(加原始输入)与层标准化,前馈(全连接1+gelu+全连接2),残差连接(加原始输入)与层标准化),最后面还有一个层标准化
5. GPT模型的流程
query (1,12,1,64) key (1,12,29,64), qk后shape=(1,12,1,29) 表示当前这个词对前面词的注意力系数(前面有29个词)
qk=(1,12,1,29) *value= (1, 12, 29, 64) -->(1, 12, 1, 64) 当前词的向量
query 是当前单个词的查询向量 而key和value是不断累积的前面所有词的k和v向量
模型不断生成一个词 作为下一时间步的query
6. GPT训练时和预测时的差别
NLG任务在训练时,对输出部分每个token都做softmax,找到正确的词。只有在测试时,才一个词一个词地生成。
7. GPT如何写诗写对联
在使用古诗词模型进行生成时,需要在输入的文本前加入一个起始符,如:若要输入“梅山如积翠,”,正确的格式为“[CLS]梅山如积翠,”。
对联模型训练时使用的语料格式为“上联-下联”,在使用对联模型进行生成时,需要在输入的文本前加入一个起始符,如:若要输入“丹枫江冷人初去-”,正确的格式为“[CLS]丹枫江冷人初去-”。















 966
966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









