







 本文介绍如何使用Python爬虫从某天气网站获取2011年以来的历史天气数据。首先分析URL结构,找到城市代码和年份月份代码,构建URL列表。接着利用正则表达式提取数据,避开2017年前后的数据格式差异。数据解析过程中遇到的坑包括城市代码变化、污染物信息的不确定性等。最后,将数据存储到sqlite3数据库,解决字段动态增加的问题,成功爬取334个城市,100多万条数据。
本文介绍如何使用Python爬虫从某天气网站获取2011年以来的历史天气数据。首先分析URL结构,找到城市代码和年份月份代码,构建URL列表。接着利用正则表达式提取数据,避开2017年前后的数据格式差异。数据解析过程中遇到的坑包括城市代码变化、污染物信息的不确定性等。最后,将数据存储到sqlite3数据库,解决字段动态增加的问题,成功爬取334个城市,100多万条数据。
某天气网站(www.数字.com)存有2011年至今的天气数据,有天看到一本爬虫教材提到了爬取这些数据的方法,学习之,并加以改进。
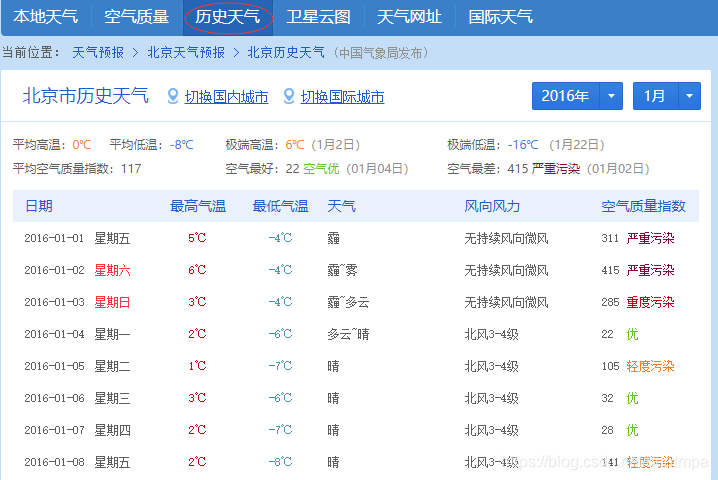
爬之前先分析url。左上有年份、月份的下拉选择框,按F12,进去看看能否找到真正的url:
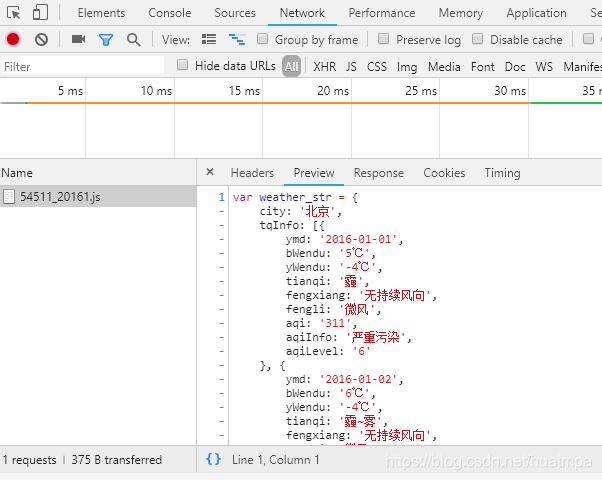
很容易就找到了,左边是储存月度数据的js文件,右边是文件源代码,貌似json格式。
双击左边js文件,地址栏内出现了url:http://tianqi.数字.com/t/wea_history/js/54511_20161.js
url中的“54511”是城市代码,“20161”是年份和月份代码。下一步就是找到城市代码列表,按城市+年份+月份构造url列表,就能开始遍历爬取了。
城市代码也很诚实,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









