







希尔排序,也称为递减增量排序算法,是插入排序的一种高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
1.插入排序在对几乎已经排好序的数据操作时,效率高,即可达到线性排序的效率
2.但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
理解希尔排序:
将数组列在一个表中并对列排序(用插入排序),重复这个过程,不过每次用更长的列来进行。最后整个表都只有一列了。将数组转换至表是为了更好的理解这算法,算法本身仅仅对原数组进行排序(通过增加索引的步长,例如用i += step_size而不是i++).
例如,假设有数组[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],以步长5开始排序,则看起来如下:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10然后对每列进行排序:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45将上述四行数字,依序接在一起可看到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ]。这时10已经移到正确位置了,然后再以3为步长进行排序:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45排序后得:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94最后再以1为排序,也就是简单的插入排序了。
实例:
#include <stdio.h>
//int hibbard[]={1,3,7,15,31};
int hibbard[] = { 1, 3, 5 };
void displayoutcome(int *data, int size){
int i;
for (i = 0; i<size; i++)
printf("%d ", *(data + i));
printf("\n");
}
void shellsort(int *data, int size){
int step, stepsp = sizeof(hibbard) / sizeof(int) - 1;//3
printf("%d %d\n", sizeof(hibbard), sizeof(int));
int i, j, tmp;
while (stepsp >= 0){
step = hibbard[stepsp--];
for (i = step; i<size; i++){
tmp = data[i];
for (j = i; j >= step && data[j - step]>tmp; j -= step)
data[j] = data[j - step];
data[j] = tmp;
}
displayoutcome(data, size);
}
}
int main(){
/*
时间复杂度:O(n^2)
空间复杂度:O(1)
思路:对于每个位置,找到最小元素;一次循环后对应位置的数一定是当前最小的。
*/
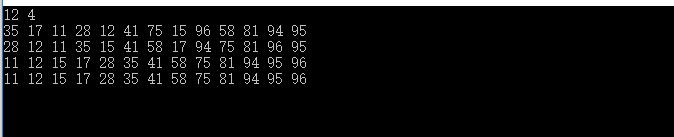
int data[] = { 81, 94, 11, 96, 12, 35, 17, 95, 28, 58, 41, 75, 15 };
int size = sizeof(data) / sizeof(int);
shellsort(data, size);
displayoutcome(data, size);
getchar();
return 0;
}结果:
参考网址
参考希尔排序网址















 5567
5567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









