







 本文是关于Heterogeneous Parallel Programming的学习笔记,主要介绍CUDA编程。内容涵盖GPU与CPU的区别、CUDA计算模型、并行线程阵列、内存模型、CUDA基本函数以及向量加法的示例。CUDA利用GPU的并行计算能力,通过Grid、Block、Thread三级结构实现并行,并通过cudaMalloc等函数管理设备内存。
本文是关于Heterogeneous Parallel Programming的学习笔记,主要介绍CUDA编程。内容涵盖GPU与CPU的区别、CUDA计算模型、并行线程阵列、内存模型、CUDA基本函数以及向量加法的示例。CUDA利用GPU的并行计算能力,通过Grid、Block、Thread三级结构实现并行,并通过cudaMalloc等函数管理设备内存。
好记性不如烂笔记。以下是在Coursera学习Heterogeneous Parallel Programming时记录的一些要点。
Wiki对Heterogeneous Programming的解释如下:
Heterogeneous computing systems refer to electronic systems that use a variety of different types of computational units. A computational unit could be a general-purpose processor (GPP), a special-purpose processor (i.e. digital signal processor (DSP) or graphics processing unit (GPU)), a co-processor, or custom acceleration logic (application-specific integrated circuit (ASIC) or field-programmable gate array (FPGA)).
简要的说,就是采用不同类型的计算节点协同进行计算。而Heterogeneous Parallel Programming则是建立在这种机制上的并行计算。这里使用的是的CUDA。CUDA是NVIDIA推出的建立在C语言和GPU基础上的计算框架。详细情况可参考《NVidia CUDA C Programming Guide》。
1. GPU与CPU
GPU与CPU的设计理念不同:GPU旨在提供高吞吐量,而CPU旨在提供低延迟的操作,如下图所示:

CPU需要降低指令的执行时间,所以有很大的缓存,而GPU则不然。单一的GPU线程执行时间相当长,因此总是多线程并行,这样提高了吞吐量。
综上,在串行计算部分应该使用CPU,而并行计算部分则应使用GPU。
2. CUDA计算模型
CUDA中计算分为两部分,串行部分在Host上执行,即CPU,而并行部分在Device上执行,即GPU。
相比传统的C语言,CUDA增加了一些扩展,包括了库和关键字。CUDA代码提交给NVCC编译器,该编译器将代码分为Host代码和Device代码两部分。Host代码即为原本的C语言,交由GCC或其他的编译器处理;Device代码部分交给一个称为实时(Just in time)编译器的组件,在给代码运行之前编译。
3. Device上的并行线程阵列
并行线程阵列由Grid——Block——Thread三级结构组成,如下图所示:
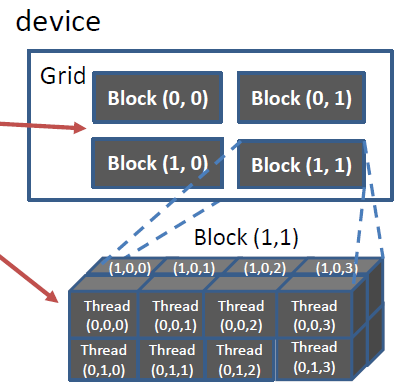
每一个Grid中包含N个Block,每一个Block中包含N个Thread。
这里需要提到SPMD概念:SPMD&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2700
2700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









