







Abstract
we introduce: a conceptually simple,scalable, and highly effective BERT-based entity linking model, along with an extensive evaluation of its accuracy-speed trade-off.
We present:a two-stage zero-shot linking algorithm, where each entity is defined only by
a short textual description.
a short textual description.
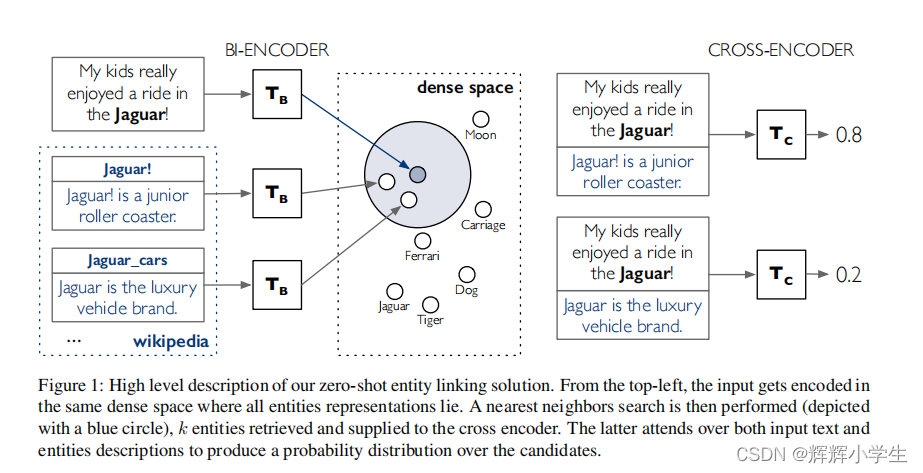
details:he first stage does retrieval in a dense space defined by a bi-encoder that independently embeds the mention context and the entity descriptions.Each candidate is then re-ranked with a crossencoder, that concatenates the mention and entity text.
Introduction
problem:
Scale is a key challenge for entity linking; there are
millions of possible entities to consider for each
mention.
previous works:
manually curated mention tables;Wikipedia link popularity ;
gold Wikipedia entity categories
our work: BERT-based models for large scale entity linking when used in a zero
shot setup, where there is no external knowledge and a short text description provides the only information we have for each entity.present an extensive evaluation of the accuracy-speed tradeoff inherent to large pre-trained models.
shot setup, where there is no external knowledge and a short text description provides the only information we have for each entity.present an extensive evaluation of the accuracy-speed tradeoff inherent to large pre-trained models.
details:
we introduce a two stage ap
proach for zero-shot linking (see Figure
1
for an
overview), based on fifine-tuned BERT architectures
. In the fifirst stage, we do re
trieval in a dense space defifined by a bi-encoder that
independently embeds the mention context and the
entitydescriptions
. Each retrieved candidate is then ex
amined more carefully with a cross-encoder that
concatenates the mention and entity text, follow
ing
Logeswaran et al.
(
2019
). This overall approach
is conceptually simple but highly effective, as we
show through detailed experiments.
Related Work 略
Defifinition and Task Formulation 略
Methodology details 略
The biencoder uses two independent BERT transformers
to encode model context/mention and entity into
dense vectors, and each entity candidate is scored
as the dot product of these vectors. The candi
dates retrieved by the bi-encoder are then passed to
the cross-encoder for ranking. The cross-encoder
encodes context/mention and entity in one trans
former, and applies an additional linear layer to
compute the fifinal score for each pair.
后面都略了 我去看代码了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









