







虚拟变量(dummy variables)
虚拟变量,也叫哑变量和离散特征编码,可用来表示分类变量、非数量因素可能产生的影响。
离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
使用pandas可以很方便的对离散型特征进行one-hot编码
说明:对于有大小意义的离散特征,直接使用映射就可以了,{'XL':3,'L':2,'M':1}
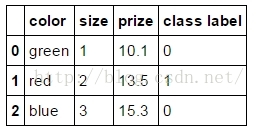
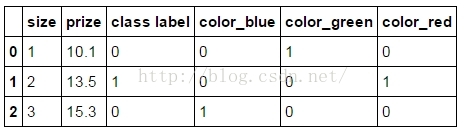
Using the get_dummies will create a new column for every unique string in a certain column:使用get_dummies进行one-hot编码















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









