







NVIDIA DGX 系统分析和探讨
NVIDIA DGX 产品
DGX B200 NVL72

NVIDIA DGX 是Nvidia 推出的turnkey 解决方案,其中按照组合关系:
DGX GB200 NVL72 System
- 36 Nvidia Grace CPU
- 72 BlackWell GPU
- 每台机柜包含18 个GB200 计算节点,每个节点包含2 个GB200s
- 9 个NVSwitches Tray 节点,每个2 颗 NVSwitch 芯片
- 节点间使用nvlink 进行互联,互联线缆使用铜(Cooper),不需要光收发器(铜进光退),机架内通过5000 根铜缆连接所有GPU

下图为1U 高度的NVL72 单节点实物形态,其中每个节点包含两组GB200s 系统,整合水冷散热。

NVL switch tray :NVLink交換器由2組NVLink交換器晶片構成,並提供144組NVLink端子,無阻塞交換劉量答14.4 TB/s,為GB200 NVL72系統提供高頻寬和低延遲資料交換能力。

实物NVL72 机柜: 对应包含的Compute Tray 和Switch Tray

DGX/HGX 的区别
首先区分下DGX和HGX, DGX 是完整的系统解决方案,HGX 只是一个串联GPU 板卡的模组。
最新发布的HGX B100 的实物形态:

DGX 互联架构
早期的DGX-1 v100 互联架构, 采用立方体mesh 互联模式, 串联起8张 v100 GPU卡,其中可以看到未使用NVSwich 芯片:
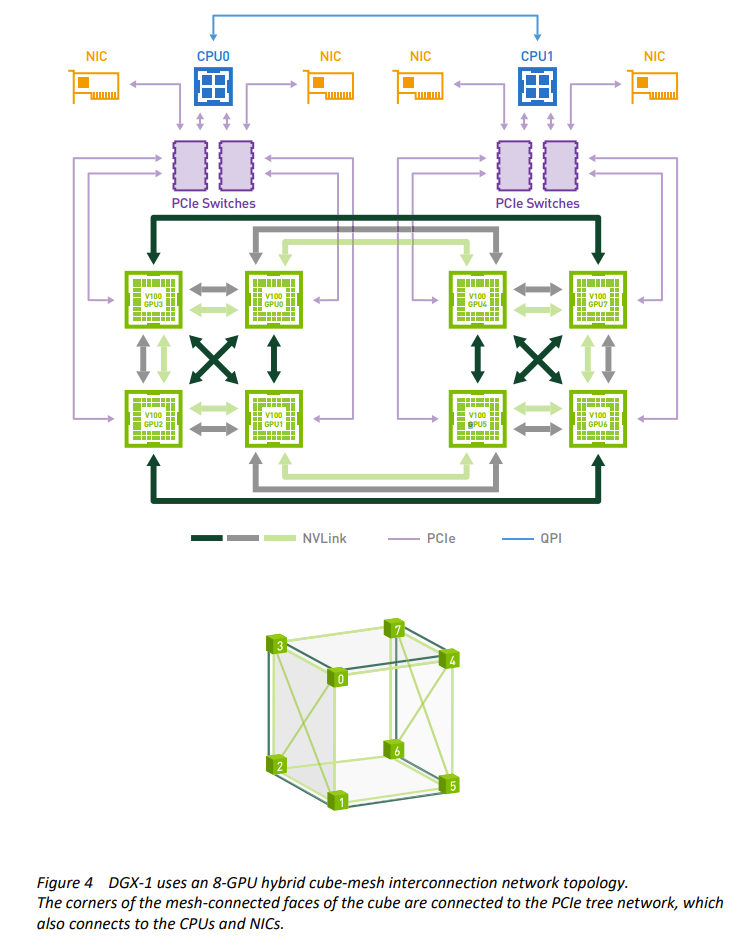
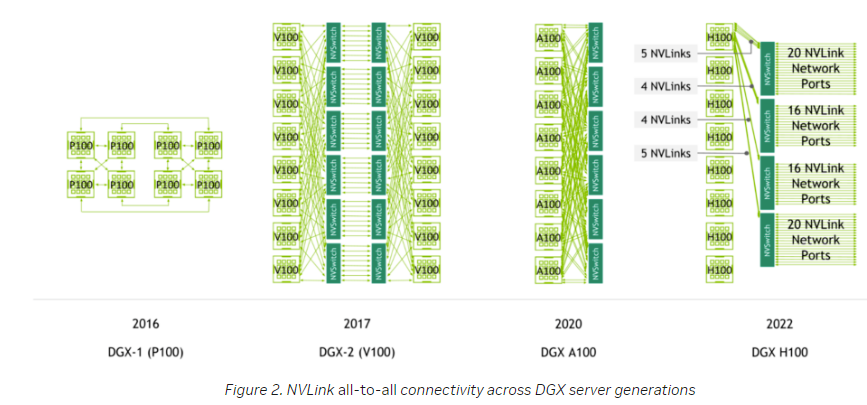
从2017 年DGX-2开始,引入了NVSwitch, 到了H100 hooper 架构, nvlink 第四代, DGX 内部拓扑结构增加了NVSwitch 对DGX 内的所有GPU 做全向直连,内部的互联结构也得到了简化。

Nvlink 互联结构的演变:
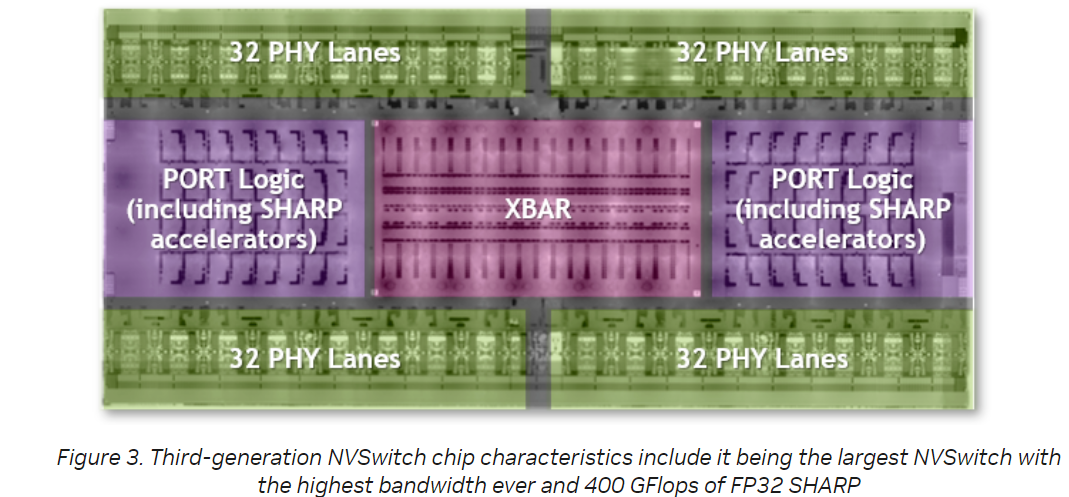
找到一张第三代NVSwitch 芯片的透视图(NVSwitch), 从图中可以看到支持的Link(Lanes).
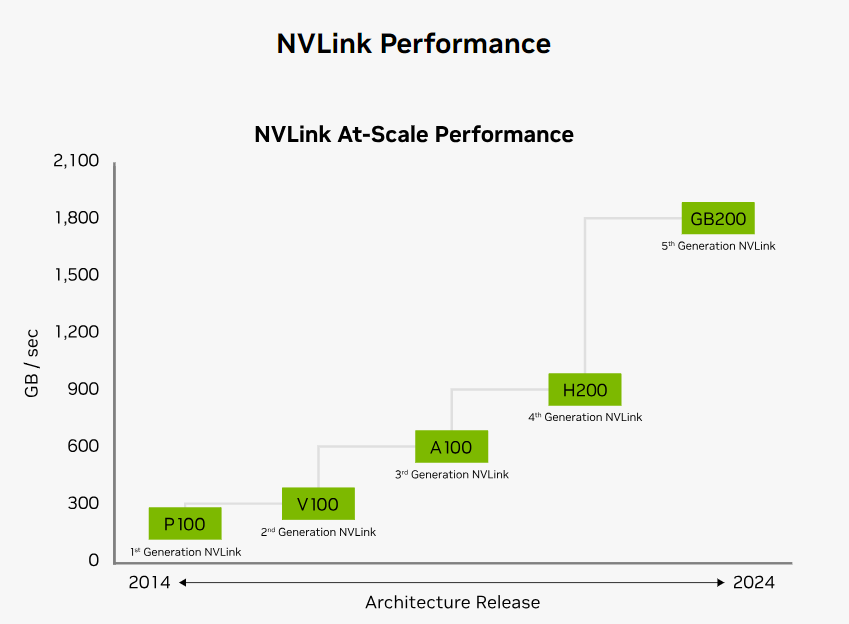
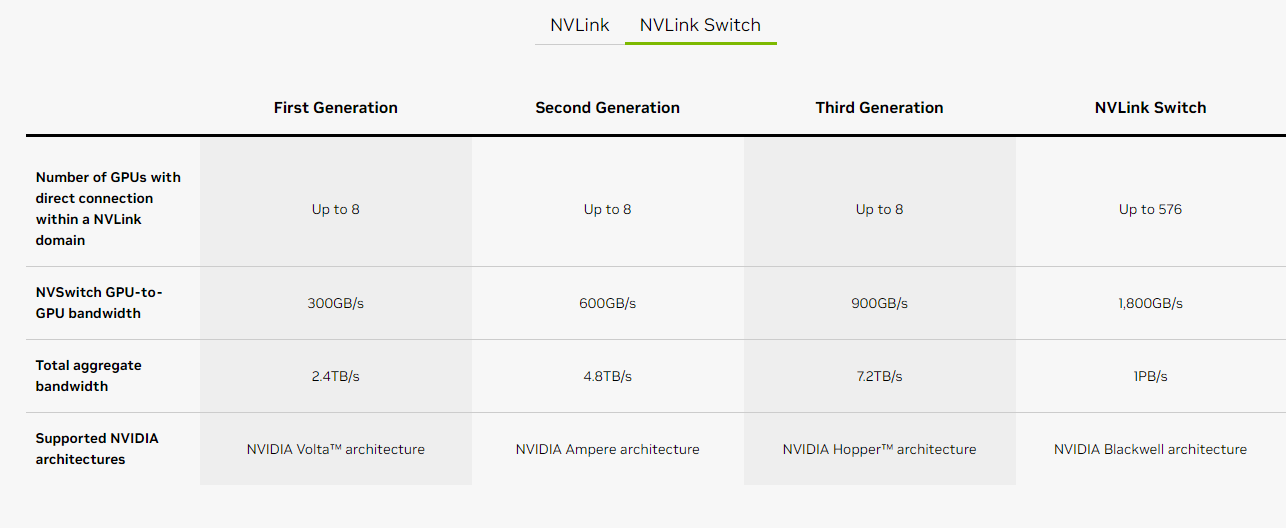

下面我们计算下DGX NVLINK 能提供的具体带宽:
Nvlink 第四代,采用112G serdes, 提供了50GB/s 的基础带宽能力,H100 具备18 个全向NVLink 接口(Port),作为对比,A100 具备12 个全向NVLink Port(NVLink 3代)
- Reduce Bandwidth: 即单芯片暴露接口能提供的最大发送或者接收带宽, 也即双向带宽的一半
- 18x 50GB/s = 900/2 GB/s @H100
- 12x 50GB/s = 600/2 GB/s @A100
- Bisection Bandwidth: 也叫二等分带宽,将网络分成节点数最接近的两个子网,在所有分法中,连接两个子网的链路带宽最小值为该网络的对分带宽,
- 8x18x50GB/s = 3600GB/s @8xH100
- 8x12*50Gb/s = 4800GB/s @8xA100
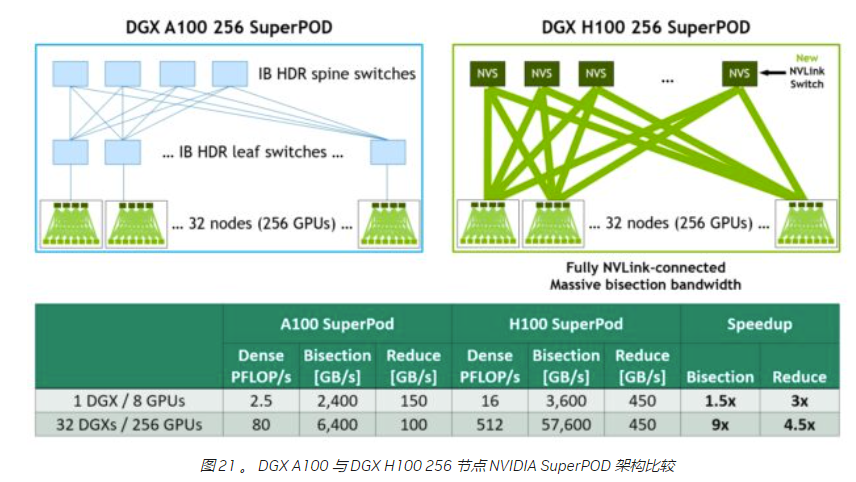
对于256 节点的DGX H100 Superpod 架构,我们进行如下分析:
- Level1 单节点包含4个switch,为8 个H100提供全向连接,总共包含32 个节点(32x8=256);
- Level 1 单节点内总共包含8x18=144 NVLink, 每个NVSwitch 连接 144/4 = 36 条NVLink(NVSwitch 此时带宽有富余,最大支持128 条NVLink 直连);
- Level2 通过32 个switch 为32 个Level1 节点提供全向连接;
- 和DGX A100 SuperPod 相比,不需要IB 网络的引入;
- 同时,DGX H100 还支持 8x NVIDIA ConnectX-7 Ethernet/InfiniBand ports 用于scaleout 到更多的superpod
除了DGX H100 SuperPOD,还支持DGX GH200 SuperPod,具体差别以及如何选择,可以参考这篇文章:NVIDIA DGX™ GH200 vs DGX™ H100 for Large-Scale AI Deployments:
https://www.amax.com/engineering/dgx-gh200-vs-dgx-h100-for-large-scale-ai-deployments/
DGX GB200 NVL72

从DGX GB200 SPEC 中看到有几个参数:
- ConnectX®-7
- 72x OSFP
- 400Gb/s InfiniBand
- 36x dual-port NVIDIA BlueField®-3 VPI with 200Gb/s InfiniBand and Ethernet
- NVLINK 第五代接口
GB200 封装了两块die,die to die 之间通过NV-HBI(nvidia hight-bandwidth interface) 进行C2C 的互联,提供10TB/s 的带宽。这里我们主要讨论模块之间的互联,即GPU2GPU。
参考资料
- NVIDIA GB200 NVL72 Delivers Trillion-Parameter LLM Training and Real-Time Inference: https://developer.nvidia.com/blog/nvidia-gb200-nvl72-delivers-trillion-parameter-llm-training-and-real-time-inference/
- Upgrading Multi-GPU Interconnectivity with the Third-Generation NVIDIA NVSwitch: https://developer.nvidia.com/blog/upgrading-multi-gpu-interconnectivity-with-the-third-generation-nvidia-nvswitch/
- https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-to-dgxh100.html
- DGXH100 userguide: https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-to-dgxh100.html
- NVIDIA Hopper 深入研究架构:https://developer.nvidia.com/zh-cn/blog/nvidia-hopper-architecture-in-depth/
- DGXA100 系统架构:https://www.skyblue.de/uploads/Datasheets/nvidia_twp_dgx_a100_system_architecture.pdf
- NVLink :https://www.nvidia.com/en-us/data-center/nvlink/


















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









