







1.链式数据结构
在链表中,每个节点包含列表中下一个节点的引用. 其它的链表结构包括树和图,其中节点可以包含多个其它节点的引用。
简单的节点Demo
public class ListNode {
public Object node;
public ListNode next;
//init Node
public ListNode() {
this.node = null;
this.next = null;
}
//usually use as the head
public ListNode(Object node) {
this.node = node;
this.next = null;
}
//normal node
public ListNode(Object node, ListNode next) {
this.node = node;
this.next = next;
}
@Override
public String toString() {
return "ListNode{" + "node=" + node + ", next=" + next + '}';
}
}
ListNode提供了几个构造函数,可以让你为data和next提供值,或将它们初始化为默认值,null.
创造一个链表
ListNode node1 = new ListNode(1);
ListNode node2 = new ListNode(2);
ListNode node3 = new ListNode(3);
node1.next = node2;
node2.next = node3;
node3.next = null;
ListNode node0 = new ListNode(0,node1);
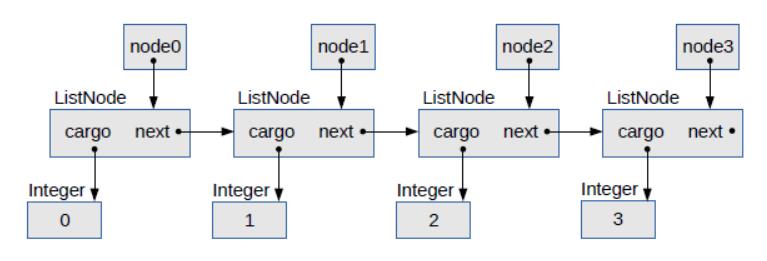
2.LinkedList初始化结构
构造内嵌函数Node
//内嵌函数(Nested Function set the Node)
private class Node {
public E data;
public Node next;
public Node() {
this.data = null;
this.next = null;
}
public Node(E data) {
this.data = data;
this.next = null;
}
public Node(E data, Node next) {
this.data = data;
this.next = next;
}
}
初始化结构
public class MyLinkedList<E> implements List<E> {
private int size; // keeps track of the number of elements
private Node head; // reference to the first node
public MyLinkedList() {
head = null;
size = 0;
}
}
存储元素数量不是必需的,并且一般来说,保留冗余信息是有风险的,因为如果没有正确更新,就有机会产生错误。它还需要一点点额外的空间。
但是如果我们显式存储
size,我们可以实现常数时间的size方法;否则,我们必须遍历列表并对元素进行计数,这需要线性时间。
因为我们显式存储
size明确地存储,每次添加或删除一个元素时,我们都要更新它,这样一来,这些方法就会减慢,但是它不会改变它们的增长级别,所以很值得。
3.LinkedList方法划分
Add方法
@Override
public boolean add( E element) {
if (head == null) {
head = new Node(element);
} else {
Node node = head;
for (; node.next != null; node = node.next) {} //loop until the next one
node.next = new Node(element);
}
size++;
return true;
}
indexOf方法
@Override
public int indexOf(Object target) {
Node node = head;
for (int i=0; i<size; i++) {
if ( equals(target,node.data) ) {
return i;
}
node = node.next;
}
return -1;
}
那么这种方法的增长级别是什么?
- 每次在循环中,我们调用了
equals,这是一个常数时间(它可能取决于target或data大小,但不取决于列表的大小)。循环中的其他操作也是常数时间。- 循环可能运行
n次,因为在更糟的情况下,我们可能必须遍历整个列表。所以这个方法的运行时间与列表的长度成正比(换言之,是线性的)。
Add双参方法
@Override
public void add(int index, E element) {
if (head == null) {
Node node = new Node(element);
} else {
Node node = getNode(index-1);
node.next = new Node(element,node.next);
}
size++;
}
辅助方法
private Node getNode(int index){
if (index<0 || index>=size) {
throw new IndexOutOfBoundsException();
}
Node node = head;
for (int i=0; i<index; i++) {
node = node.next;
}
return node;
}
getNode类似indexOf,出于同样的原因也是线性的。- 在
add中,getNode前后的一切都是常数时间。所以放在一起,
add是线性的。
Remove方法
@Override
public E remove(int index) {
E element = get(index);
if (index == 0) {
head = head.next;
} else {
Node node = getNode(index-1);
node.next = node.next.next;
}
size--;
return element;
}
remove使用了get查找和存储index处的元素。然后它删除包含它的Node。如果
index==0,我们再次处理这个特殊情况。否则我们找到节点index-1(这个真的是心机,得防止它漏过)并进行修改,来跳过node.next并直接链接到node.next.next。这有效地从列表中删除node.next,它可以被垃圾回收。当人们看到两个线性操作时,他们有时会认为结果是平方的,但是只有一个操作嵌套在另一个操作中才适用。如果你在一个操作之后调用另一个,运行时间会相加。如果它们都是
O(n)的,则总和也是O(n)的。所以Remove()是线性的
4.ArrayList和LinkedList的对比
| MyArrayList | MyLinkedList | |
|---|---|---|
add(末尾) | 1 | n |
add(开头) | n(剩余的都往后) | 1 |
add(一般) | n | n |
get / set | 1 | n |
indexOf / lastIndexOf | n | n |
isEmpty / size | 1 | 1 |
remove(末尾) | 1 | n |
remove(开头) | n | 1 |
remove(一般) | n | n |
MyArrayList的优势操作是,插入末尾,移除末尾,获取和设置。MyLinkedList的优势操作是,插入开头,以及移动开头。(链式结构头容易获取)
要用哪种看具体的需求
原书链接:https://wizardforcel.gitbooks.io/think-dast/content/5.html
GitHub链接(提供源码):https://github.com/huoji555/Shadow/tree/master/DataStructure















 9028
9028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









