







现在有一个具体的案例是这样的:CST电磁仿真软件得到一些txt数据在origin_data文件夹中。需要其中的一些数据来通过origin软件绘制曲线分析一些问题,而且需要里面的所有数据曲线显示在同一个图形中。如果通过手动将txt数据一一复制到origin(或excel)中,txt没有整列复制功能,所有手动复制很麻烦。通过Python脚本提取相关数据就比较容易了。

首先分析一下txt数据格式:
格式1:
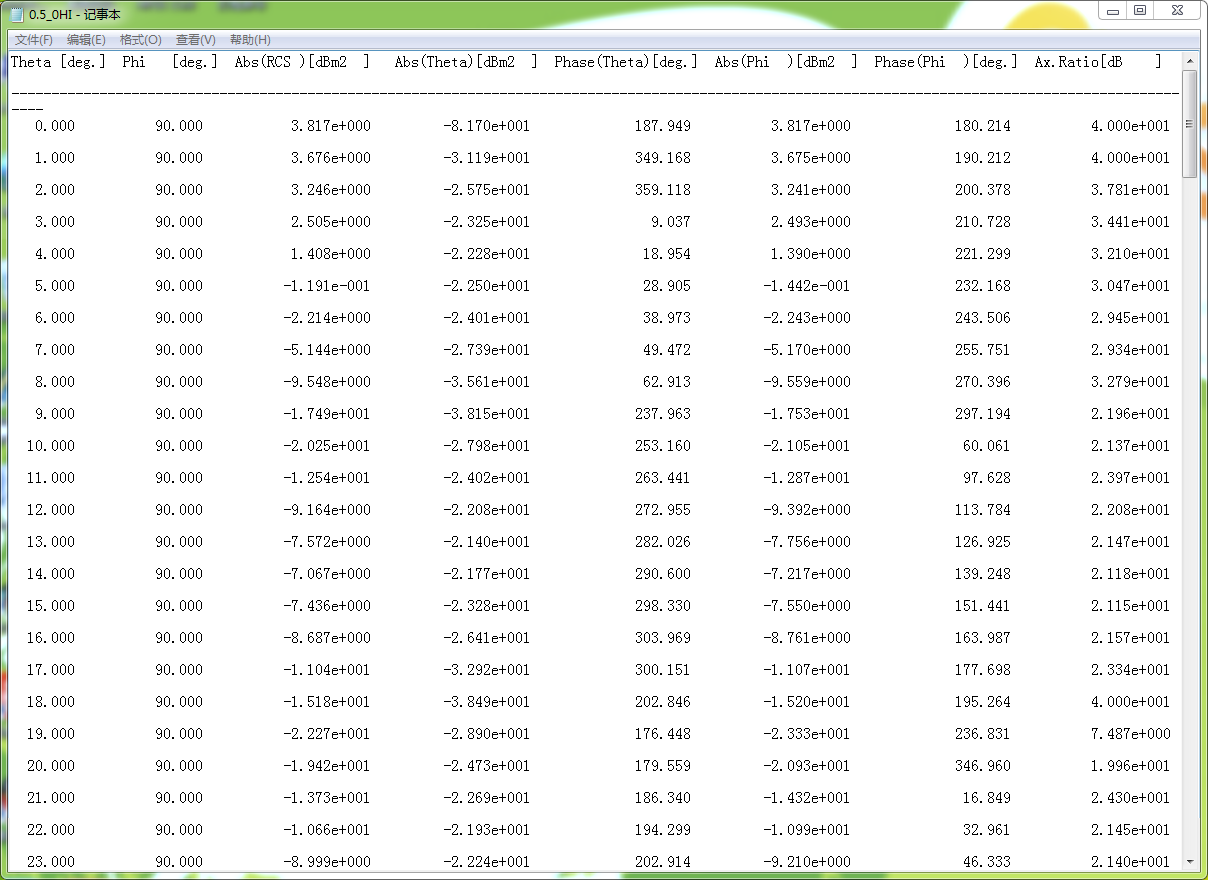
格式2:
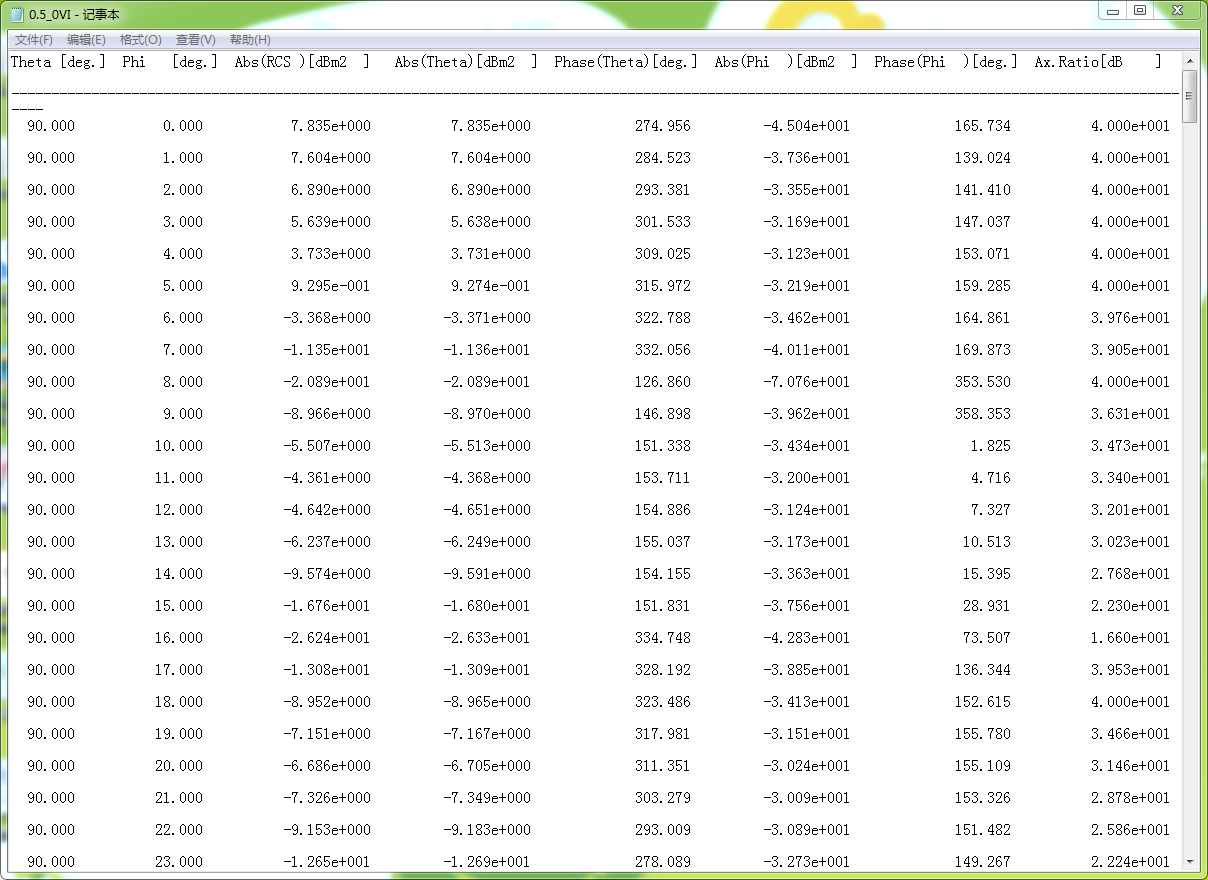
每种格式都是8列数据,一列的数据是关于角度的,我们需要的数据是第3列的rcs数据。之前有一个方案是根据角度来判断需要相应的数据范围,但是这个方案显然有问题,因为两种数据格式中表示角度的数据不在同一列,而且两种格式的角度范围不一样(方位角:0-180;俯仰角:0-360)。所以在已有的代码下,我提出的一种想法是:提取每个txt的第三列rcs数据分别保存为excel文件,然后再限制角度范围进行提取合并(可能是觉得Python操作excel更方便吧,没有尝试直接操作txt的提取合并)。
代码实现:
分两步,第一步保存“分excel”
#! C:\Python27\python
# -*- coding: utf-8 -*-
import os
import xlrd
import sys
from xlwt import *
if __name__ == '__main__': #判断是否直接运行该文件
threadhold_input = sys.argv[1]#运行程序时要输入一个参数表示argv[1]的值
file_directory = 'F:\\origin_data\\' # 指明被遍历的文件夹
savefile=r'F:\origin_data1'#创建目录
if not os.path.isdir(savefile):
os.mkdir(r'F:/origin_data1/')
xls_path='F:\\origin_data1\\'#指定“分excel”保存的路径
for parent, dirnames, filenames in os.walk(file_directory):
for filename in filenames: # 输出文件信息
with open(file_directory+filename, 'r') as fp:# 打开文件夹中的文件内容
excel = xlwt.Workbook()# 创建工作簿
sheet = excel.add_sheet('DataSheet', cell_overwrite_ok=True)
for j, line in enumerate(fp.readlines()[2:]):
rcs = line.strip().split()[2].strip()
sheet.write(j, 0, rcs)#在sheet的第j+2行第1列中写入一个rcs
excel.save(xls_path+filename[:-3]+'xls')通过上面的代码就可以实现保存分excel的功能,并保存在“origin_data1”文件夹中:

第二步,对“分excel”通过设置提取的角度来读取相关数据,并写入另一个excel中:
#接上
y='F:\\exc_py\\'
n=Workbook()
new = n.add_sheet('jointdata',cell_overwrite_ok=True)
for parent, dirnames, filenames in os.walk(xls_path):
l=len(filenames)-2#因为此时filenames是一个数组,所有可以通过len返回文件夹中的文件个数,
#由于包含了两个Py文件,所有要去掉(至于运行时py文件和批处理文件为什
#么要和这些xls文件在一起才能运行,一直没弄明白。希望懂的大神,不吝赐教。
j=1
for filename in filenames:
data = xlrd.open_workbook(filename)
#j=filenames.index(filename)+1
#这个函数返回打开的xls文件的索引号,
#但是由于文件夹中有Python文件,还是由于其他的未知原因。
#尝试之后,不能成功运行,放弃这个函数。
table = data.sheets()[0]
for i in range(int(threadhold_input)+1):
rcs1=table.row_values(i)
new.write(i,j,rcs1)
j+=1
if j >l: #将限制条件与文件格式l关联,就可以实现多个文件的自动处理
break
for d in range(int(threadhold_input)+1):
new.write(d,0,d)
n.save(y+'jointdata.xls') #将生成的jiontdata文件单独保存在另一个文件夹中,
#这样可以避免在上一步处理excel文件时,出现个数变更问题 上面代码实现了对上面每个excel数据的选择与合并:
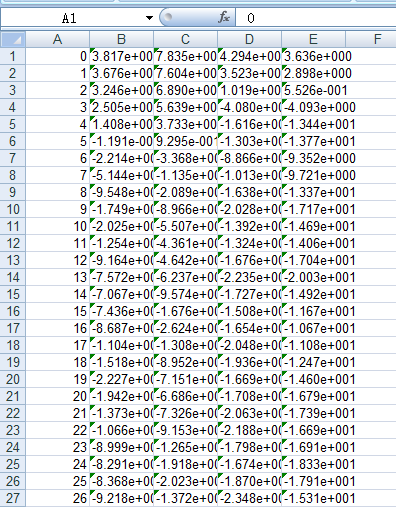
代码部分就是这样子的了。
需要说明的是最后的Python文件放在“origin_data1”文件夹中,不然不能产生“jointdata”excel文件,具体原因我也不太清除(希望各路大神不吝赐教),设置的角度大小不能超过4组数据角度的最小范围。如果从cmd窗口中运行Python文件还是比较麻烦的,所有我写了一个批处理文件,可以通过txt格式打开,修改角度范围:

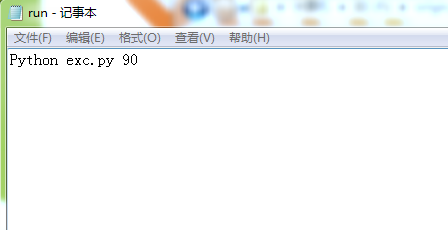
涉及的文件夹及文件如下:



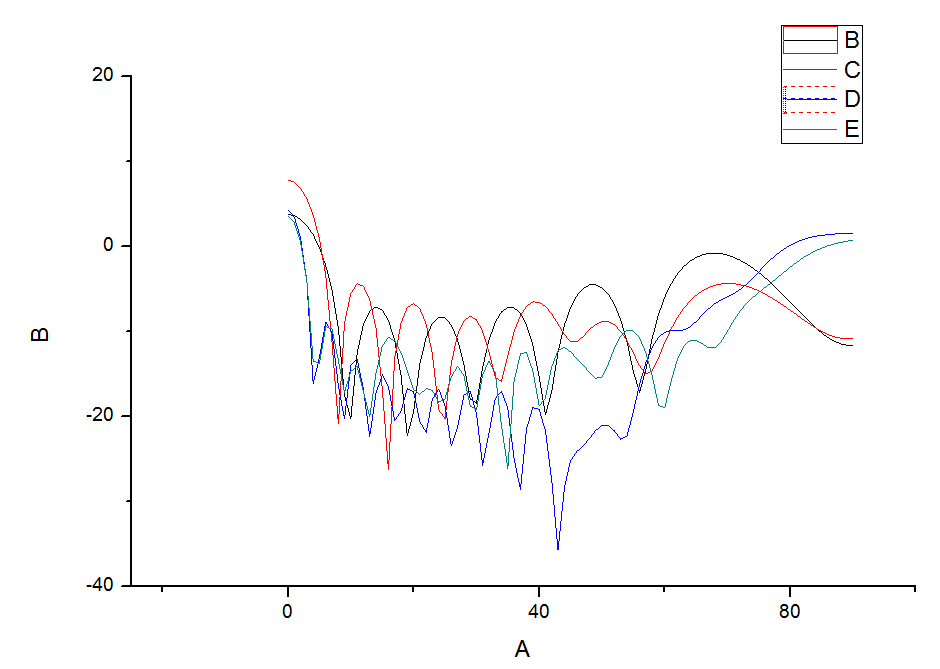
最后附一张通过origin导入代码生成的“jointdata.xls”而绘制的曲线(横坐标是角度(0-90),纵坐标是4组rsc数据):
第一次写技术类博客,资质尚浅。希望各路技术大神不吝赐教。如青眼有加,愿共同探讨学习Python数据处理问题。QQ:15298063683(非诚勿扰)















 1960
1960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









