







背景介绍
之前在做大模型知识库 RAG 优化时,主要参考的都是学术界的论文。最近了解到有道 QAnything 开源了,在线试用 之后,效果看起来还不错,燃起了探索其实现细节的兴趣。
正好对于 RAG 各个环节的最佳实践存在一些疑问,因此深入查看了有道 QAnything 的完整实现流程,学习下来自工业界大厂有道的实践方案,在这边分享给大家。
本文章基于的是 2024-5 月最新的版本 v1.4.0,这个项目还在持续迭代中,后续的版本可能会存在差异。
项目概述
框架设计
首先可以关注下 QAnything 的架构设计,与常规的 RAG 架构进行一些比较
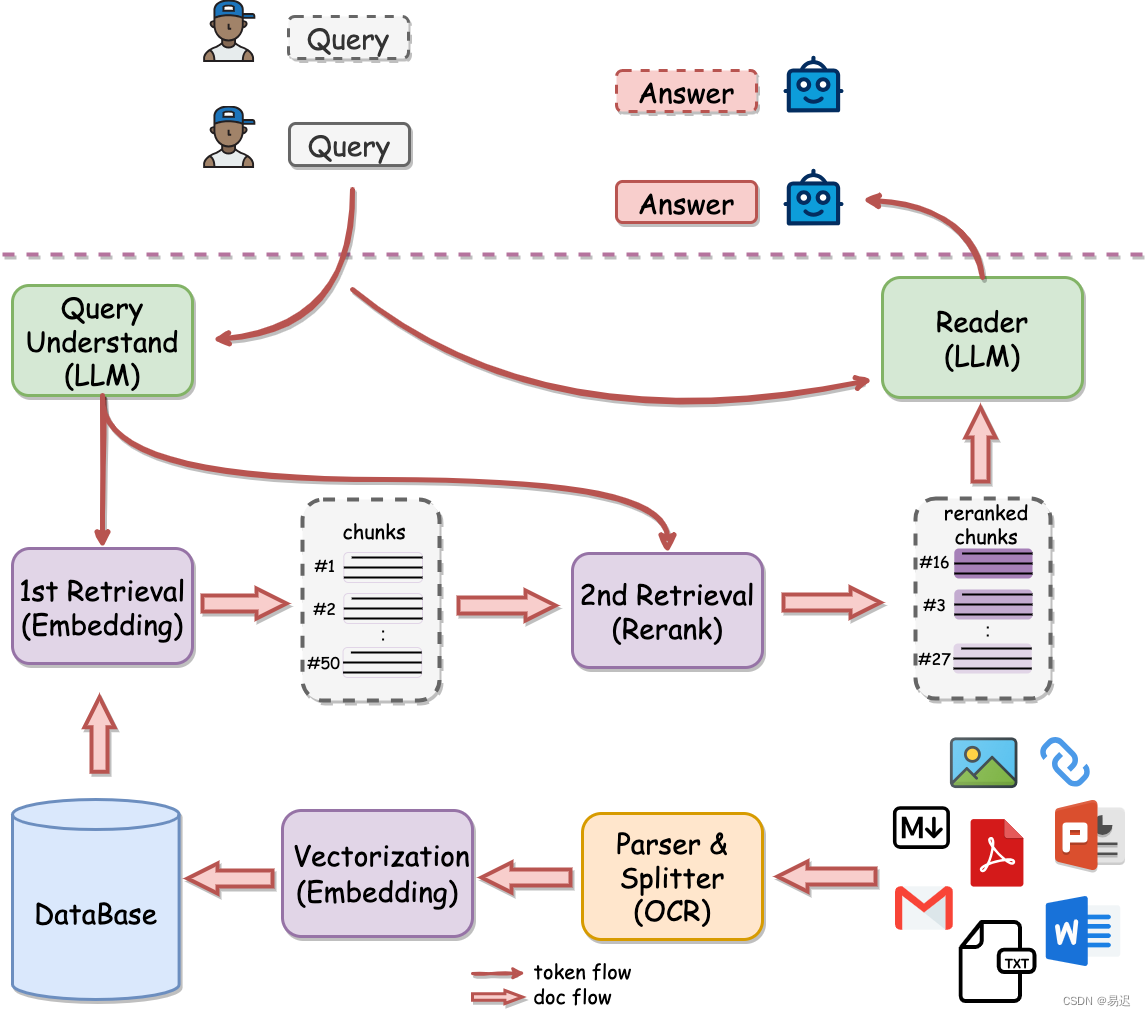
与常规的 RAG 流程图相比,明显更加突出了 Rerank 环节,将 Rerank 作为 2nd Retrieval 进行强调,看起来这是有道对 RAG 的独到理解。
另外 QAnything 官方文档 中也强调,QAnything 使用的向量检索模型 bce-embedding-base_v1 + 向量排序模型 bce-reranker-base_v1 组合才是 SOTA。同样也印证了架构图, Rerank 是 QAnything 是相当重要的模块。
项目源码
QAnything 使用 sanic 实现 web 服务,目前更常规的选择是 FastAPI, 从部分评测来看 sanic 可能更快一些,不过差距不大。
业务数据库使用 MySQL,向量数据库使用 milvus,这些都是常规操作,不需要过多分析。
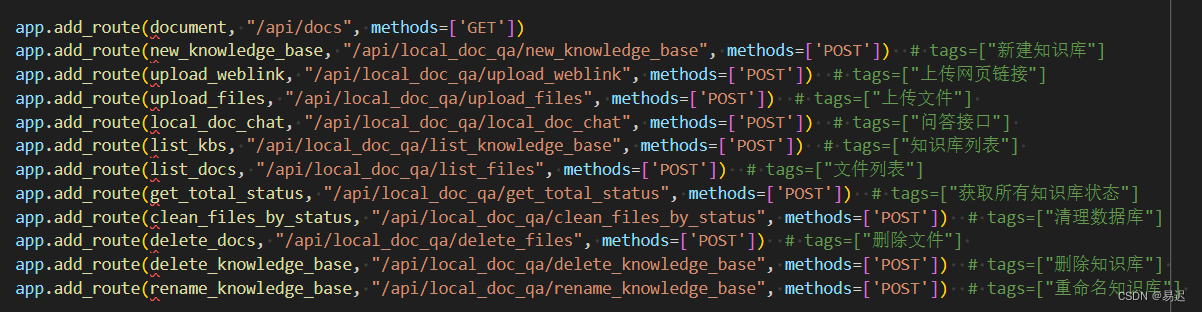
QAnything 的 web 服务的定义在 qanything_kernel/qanything_server/sanic_api.py,可以看到其中涉及的主要 API 接口路由地址, 可以看到目前实现的主要功能。
实现细节
常规的 RAG 主要包含如下所示的模块:
- 文件加载的支持;
- 文件的预处理策略;
- 文件检索的支持 (包含混合检索);
- 检索结果的重排;
- 大模型的处理;
下面就对这些环节的实现细节分别进行探索,看看其中有什么独特的设计。
文件加载的支持
文件的加载肯定是在用户上传时处理的,跟着接口 /api/local_doc_qa/upload_files 进去就可以看到对应的细节,简化后如下所示:
async def upload_files():
for file, file_name in zip(files, file_names):
# 将文件信息存入 MySQL 数据库
file_id, msg = local_doc_qa.milvus_summary.add_file(user_id, kb_id, file_name, timestamp)
local_file = LocalFile(user_id, kb_id, file, file_id, file_name, local_doc_qa.embeddings)
local_files.append(local_file)
# 将文件处理后存入 milvus 向量数据库
asyncio.create_task(local_doc_qa.insert_files_to_milvus(user_id, kb_id, local_files))
主要需要关注的是向量库写入,深入其中查看文件的解析,对应的实现在 qanything_kernel/core/local_file.py 中的 split_file_to_docs() 方法中,我们以 pdf 文件为例,查看对应的实现:
elif self.file_path.lower().endswith(".pdf"):
loader = UnstructuredPaddlePDFLoader(self.file_path, ocr_engine)
texts_splitter = ChineseTextSplitter(pdf=True, sentence_size=sentence_size)
docs = loader.load_and_split(texts_splitter)
pdf 文件的加载使用的是自行封装的 UnstructuredPaddlePDFLoader,深入查看实现细节如下:
class UnstructuredPaddlePDFLoader(UnstructuredFileLoader):
def _get_elements(self) -> List:
def pdf_ocr_txt(filepath, dir_path="tmp_files"):
# 基于 PyMuPDF 解析 pdf 文件
doc = fitz.open(filepath)
txt_file_path = os.path.join(
full_dir_path, "{}.txt".format(os.path.split(filepath)[-1]))
with open(txt_file_path, "w", encoding="utf-8") as fout:
for i in tqdm(range(doc.page_count)):
page = doc.load_page(i)
# 获取 pdf 中的页,转换为图像
pix = page.get_pixmap()
img = np.frombuffer(pix.samples, dtype=np.uint8).reshape(
(pix.h, pix.w, pix.n))
img_data = {
"img64": base64.b64encode(img).decode("utf-8"),
"height": pix.h,
"width": pix.w,
"channels": pix.n,
}
# 将图像数据发送给 OCR 服务提取内容
result = self.ocr_engine(img_data)
result = [line for line in result if line]
ocr_result = [i[1][0] for line in result for i in line]
fout.write("\n".join(ocr_result))
return txt_file_path
txt_file_path = pdf_ocr_txt(self.file_path)
return partition_text(filename=txt_file_path, **self.unstructured_kwargs)
通过上面的实现可以看到,pdf 文件解析是基于 PyMuPDF 实现的,这是目前 pdf 解析中效率较高的方案。
QAnything 使用 PyMuPDF 提供的 get_pixmap 将原始的 pdf 转换为图像,并调用 OCR 服务提取内容,简单粗暴。
优势是处理简单,不需要区分文字文档,还是图像文档,处理统一。缺点是效率会稍微低一点。从我实际测试的情况来看,解析文字文档时调用 PyMuPDF 提供的 get_text 速度会比 OCR 快很多。
文件的预处理策略
文件的预处理切片目前主要是通过自行实现的 ChineseTextSplitter 来完成的。在此步骤中会执行多余字符的清理,并按照符号进行切分,有不少的特殊处理逻辑,应该是对实践中发现的 bad case 进行了较多的特殊处理。对应的实现如下所示:
def split_text(self, text: str) -> List[str]:
if self.pdf:
text = re.sub(r"\n{3,}", r"\n", text)
text = re.sub('\s', " ", text)
text = re.sub("\n\n", "", text)
# 单字符断句符
text = re.sub(r'([;;.!?。!?\?])([^”’])', r"\1\n\2", text)
# 英文省略号
text = re.sub(r'(\.{6})([^"’”」』])', r"\1\n\2", text)
# 中文省略号
text = re.sub(r'(\…{2})([^"’”」』])', r"\1\n\2", text)
text = re.sub(r'([;;!?。!?\?]["’”」』]{0,2})([^;;!?,。!?\?])', r'\1\n\2', text)
# 如果双引号前有终止符,那么双引号才是句子的终点,把分句符\n放到双引号后,注意前面的几句都小心保留了双引号
text = text.rstrip()
# 很多规则中会考虑分号;,但是这里我把它忽略不计,破折号、英文双引号等同样忽略,需要的再做些简单调整即可。
ls = [i for i in text.split("\n") if i]
for ele in ls:
if len(ele) > self.sentence_size:
ele1 = re.sub(r'([,,.]["’”」』]{0,2})([^,,.])', r'\1\n\2', ele)
ele1_ls = ele1.split("\n")
for ele_ele1 in ele1_ls:
if len(ele_ele1) > self.sentence_size:
ele_ele2 = re.sub(r'([\n]{1,}| {2,}["’”」』]{0,2})([^\s])', r'\1\n\2', ele_ele1)
ele2_ls = ele_ele2.split("\n")
for ele_ele2 in ele2_ls:
if len(ele_ele2) > self.sentence_size:
ele_ele3 = re.sub('( ["’”」』]{0,2})([^ ])', r'\1\n\2', ele_ele2)
ele2_id = ele2_ls.index(ele_ele2)
ele2_ls = ele2_ls[:ele2_id] + [i for i in ele_ele3.split("\n") if i] + ele2_ls[ele2_id + 1:]
ele_id = ele1_ls.index(ele_ele1)
ele1_ls = ele1_ls[:ele_id] + [i for i in ele2_ls if i] + ele1_ls[ele_id + 1:]
id = ls.index(ele)
ls = ls[:id] + [i for i in ele1_ls if i] + ls[id + 1:]
return ls
文件检索的支持
检索是 RAG 问答一部分,只需要关注问答接口 /api/local_doc_qa/local_doc_chat 的实现 local_doc_chat() 即可。
跟进调用链路,确认向量库检索的实现是在 qanything_kernel/core/local_doc_qa.py 中的 get_source_documents() 中完成的,具体实现如下:
def get_source_documents(self, queries, milvus_kb, cosine_thresh=None, top_k=None):
milvus_kb: MilvusClient
if not top_k:
top_k = self.top_k
source_documents = []
# 将用户查询向量化
embs = self.embeddings._get_len_safe_embeddings(queries)
# 调用 milvus client 进行向量库查询
batch_result = milvus_kb.search_emb_async(embs=embs, top_k=top_k, queries=queries)
for query, query_docs in zip(queries, batch_result):
for doc in query_docs:
doc.metadata['retrieval_query'] = query
doc.metadata['embed_version'] = self.embeddings.embed_version
source_documents.append(doc)
# 指定阈值情况下可以使用相似分执行过滤
if cosine_thresh:
source_documents = [item for item in source_documents if float(item.metadata['score']) > cosine_thresh]
return source_documents
可以看到实际的检索是调用 MilvusClient 类的 search_emb_async() 方法完成的。深入进去发现,核心的检索是在 MilvusClient 中的 __search_emb_sync() 方法完成。
目前支持了常规的向量检索与混合检索(BM25 + 向量检索),具体的实现如下所示:
def __search_emb_sync(self, embs, expr='', top_k=None, client_timeout=None, queries=None):
if not top_k:
top_k = self.top_k
# 调用 milvus 进行向量检索
milvus_records = self.sess.search(data=embs, partition_names=self.kb_ids, anns_field="embedding",
param=self.search_params, limit=top_k,
output_fields=self.output_fields, expr=expr, timeout=client_timeout)
milvus_records_proc = self.parse_batch_result(milvus_records)
# 混合检索, 调用 ES 客户端执行 BM25 检索,并将检索的结果与向量检索的结果拼接在一起
if self.hybrid_search:
es_records = self.client.search(queries)
es_records_proc = self.parse_es_batch_result(es_records, milvus_records)
milvus_records_proc.extend(es_records_proc)
return milvus_records_proc
值得注意的是,默认流程是没有使用相似度阈值进行过滤的,而且返回的数量 top_k 默认为 100,配置上混合检索后获得的文档数量会更多,可以理解为向量化检索尽可能多地匹配了可能相关的文档。
检索结果的重排
检索结果的重排是通过调用 API 请求本地的重排服务器实现的,默认调用的是 http://0.0.0.0:8776/rerank 地址
def rerank_documents_for_local(self, query, source_documents):
source_documents_reranked = []
# 调用重排服务执行文档的重排
response = requests.post(f"{self.local_rerank_service_url}/rerank",
json={"passages": [doc.page_content for doc in source_documents], "query": query}, timeout=60)
scores = response.json()
for idx, score in enumerate(scores):
source_documents[idx].metadata['score'] = score
# 将重排分数小于 0.35 的文档过滤
if score < 0.35 and len(source_documents_reranked) > 0:
continue
source_documents_reranked.append(source_documents[idx])
# 根据重排得分重新排序文档
source_documents_reranked = sorted(source_documents_reranked, key=lambda x: x.metadata['score'], reverse=True)
return source_documents_reranked
注意 QAnything 是根据 Rerank 的得分进行过滤的,与常规 RAG 根据相似度过滤存在一些差异。另外考虑到 QAnything 默认检索 100 个文档,使用 Rerank 得分 0.35 进行过滤后数量也可能会超过大模型的请求 token 数量。
重排服务是在 qanything_kernel/dependent_server/rerank_for_local_serve/rerank_server.py 定义的,并在 LocalRerankBackend.predict() 实际完成对重排请求的处理,实现如下所示:
def predict(self,
query: str,
passages: List[str],
):
# 原始 query 和文档内容 tokenize 转换
tot_batches, merge_inputs_idxs_sort = self.tokenize_preproc(query, passages)
tot_scores = []
for k in range(0, len(tot_batches), self.batch_size):
batch = self.tokenizer.pad(
tot_batches[k:k + self.batch_size],
padding=True,
max_length=None,
pad_to_multiple_of=None,
return_tensors="np"
)
# 重排推理得到对应的分数
scores = self.inference(batch)
tot_scores.extend(scores)
merge_tot_scores = [0 for _ in range(len(passages))]
for pid, score in zip(merge_inputs_idxs_sort, tot_scores):
merge_tot_scores[pid] = max(merge_tot_scores[pid], score)
return merge_tot_scores
在此方法中会将原始的文本内容 tokenizer 转换为对应的标记,接下来调用 triton 部署的 Rerank 模型对每个文档进行评分,作为最终过滤和调整顺序的依据。
大模型的处理
在实际进行大模型请求时,包含下面这几部分的内容:
- 原始问题;
- 检索获得的文档 context;
- 历史聊天记录;
- 将所有数据组织在一起的 prompt;
前面在获取相关文档时相对宽松,重排时进行了过滤掉了得分低于 0.35 的文档,但是并没有限制匹配的数量,因此依旧会出现匹配的文档的数量超过大模型单次请求的最大 token 数量。
因此在实际发起请求时,QAnything 会根据实际调用的大模型可用 token 计算确定实际可用的文档 context 的数量,从而避免超过大模型的 token 数量从而导致请求失败。对应的过滤实现如下所示:
def reprocess_source_documents(self, query: str,
source_docs: List[Document],
history: List[str],
prompt_template: str) -> List[Document]:
# 计算原始 query 问题的 token 数量
query_token_num = self.llm.num_tokens_from_messages([query])
# 计算会话历史的 token 数量
history_token_num = self.llm.num_tokens_from_messages([x for sublist in history for x in sublist])
# 计算构造请求的 prompt 模板的 token 数量
template_token_num = self.llm.num_tokens_from_messages([prompt_template])
# 根据大模型自身的 token 数量与已经使用的 token 数量确定预留给检索文档的 token 数量
limited_token_nums = self.llm.token_window - self.llm.max_token - self.llm.offcut_token - query_token_num - history_token_num - template_token_num
new_source_docs = []
total_token_num = 0
for doc in source_docs:
doc_token_num = self.llm.num_tokens_from_docs([doc])
# token 够用
if total_token_num + doc_token_num <= limited_token_nums:
new_source_docs.append(doc)
total_token_num += doc_token_num
# token 不够用了,尝试切分最后一个匹配的文档
else:
remaining_token_num = limited_token_nums - total_token_num
doc_content = doc.page_content
doc_content_token_num = self.llm.num_tokens_from_messages([doc_content])
while doc_content_token_num > remaining_token_num:
# Truncate the doc content to fit the remaining tokens
if len(doc_content) > 2 * self.llm.truncate_len:
doc_content = doc_content[self.llm.truncate_len: -self.llm.truncate_len]
else:
doc_content = ""
break
doc_content_token_num = self.llm.num_tokens_from_messages([doc_content])
doc.page_content = doc_content
new_source_docs.append(doc)
break
return new_source_docs
可以看到通过动态计算大模型实际可用的 token 数量,保证尽可能多的填充检索的文件,从而提升大模型的回答的效果。
实际请求大模型时,最终默认使用的 prompt 模板如下所示:
"""参考信息:
{context}
---
我的问题或指令:
{question}
---
请根据上述参考信息回答我的问题或回复我的指令。前面的参考信息可能有用,也可能没用,你需要从我给出的参考信息中选出与我的问题最相关的那些,来为你的回答提供依据。回答一定要忠于原文,简洁但不丢信息,不要胡乱编造。我的问题或指令是什么语种,你就用什么语种回复,
你的回复:"""
其中 context 对应的就是检索的文档的内容。
结论
通过上面的完整流程的介绍,基本看到了一个来自工业界的 RAG 服务 QAnything 的全貌,和最初的猜测一致,有道 QAnything 主要是在 Rerank 阶段做了不少的优化,十分强调 Rerank 对于 RAG 的重要性。
在 Embedding Query 阶段,QAnything 没有应用目前学术界经常提到的 Rewrite, Query2Doc 和 Self-RAG 等优化机制。
实践是检验真理的唯一手段,是否有效还得试了才知道,大家尽可以借鉴各个方案的优秀之处,最终才能不断提升服务的效果。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











