







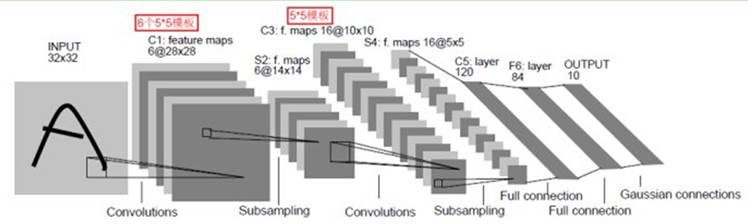
(1) 准备数据
cd $CAFFE_ROOT
./data/mnist/get_mnist.sh
./examples/mnist/create_mnist.sh从MNIST网站上下载数据,并且将数据转换成caffe可以识别的数据.然后,即得到两个数据集 mnist_train_lmdb, and mnist_test_lmdb.
(2) 定义MNIST网络
该网络定义在 lenet_train_test.prototxt 中.关于caffe中protobuf的定义, $CAFFE_ROOT/src/caffe/proto/caffe.proto中有详细解释.
首先,网络名称
name: "LeNet"
Data Layer
layer {
name: "mnist"
type: "Data"
data_param {
source: "mnist_train_lmdb"
backend: LMDB
batch_size: 64
scale: 0.00390625
}
top: "data"
top: "label"
}scale主要是为了归一化,使像素值在[0 1]之间,1/256 约等于0.00390625.
Convolution Layer
layer {
name: "conv1"
type: "Convolution"
param { lr_mult: 1 }
param { lr_mult: 2 }
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "data"
top: "conv1"
}输出20channels(feature map),卷积的kernel size 为5 and stride 为1.filters的参数可以随机产生.对于weight_filler, 用的是xavier算法. bias filler初始为constant,默认为0.lr_mults是学习率, weight learning rate 跟运行时的学习率一样,bias learning rate 一般是两倍.
Pooling Layer
layer {
name: "pool1"
type: "Pooling"
pooling_param {
kernel_size: 2
stride: 2
pool: MAX
}
bottom: "conv1"
top: "pool1"
}**
layer {
name: "ip1"
type: "InnerProduct"
param { lr_mult: 1 }
param { lr_mult: 2 }
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "pool2"
top: "ip1"
}fully connected layer 在caffe里面通常被称为InnerProduct layer
ReLU Layer
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}ReLU Layer 后会再接一个innerproduct layer
layer {
name: "ip2"
type: "InnerProduct"
param { lr_mult: 1 }
param { lr_mult: 2 }
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "ip1"
top: "ip2"
}Loss Layer
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
}(3) MNIST Solver
定义在 $CAFFE_ROOT/examples/mnist/lenet_solver.prototxt:
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: GPU(4) training and test the model
cd $CAFFE_ROOT
./examples/mnist/train_lenet.sh
train_lenet.sh 就是一个简单的脚本
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt最后,model存在
lenet_iter_10000
references
http://caffe.berkeleyvision.org/gathered/examples/mnist.html















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









