






0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 招聘网站爬取与大数据分析可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
1 课题背景
本项目利用 python 网络爬虫抓取常见招聘网站信息,完成数据清洗和结构化,存储到数据库中,搭建web系统对招聘信息的薪资、待遇等影响因素进行统计分析并可视化展示。
2 实现效果
首页

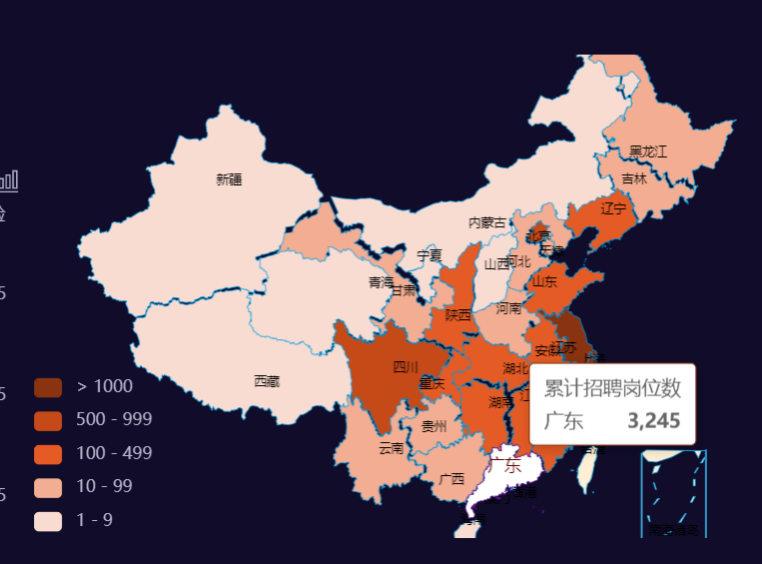
岗位地图
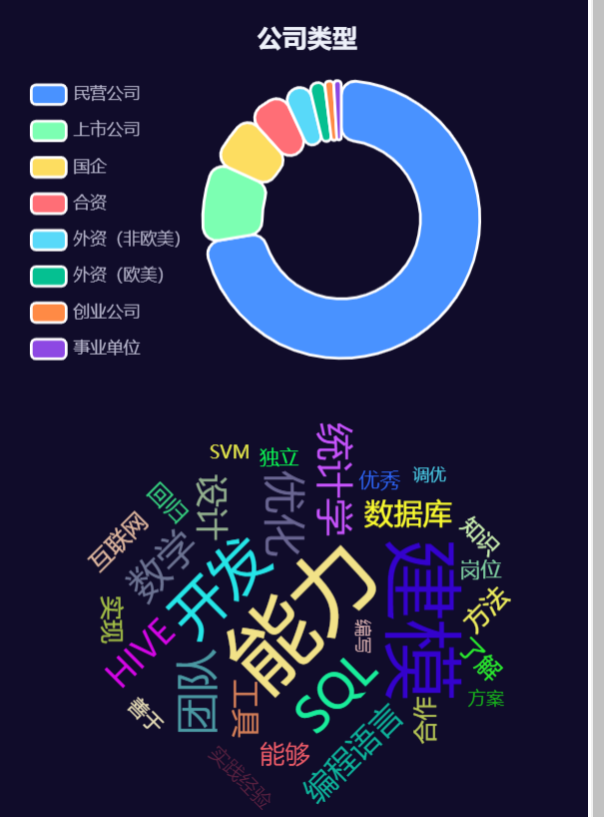
类型、词云
3 Flask框架
简介
Flask是一个基于Werkzeug和Jinja2的轻量级Web应用程序框架。与其他同类型框架相比,Flask的灵活性、轻便性和安全性更高,而且容易上手,它可以与MVC模式很好地结合进行开发。Flask也有强大的定制性,开发者可以依据实际需要增加相应的功能,在实现丰富的功能和扩展的同时能够保证核心功能的简单。Flask丰富的插件库能够让用户实现网站定制的个性化,从而开发出功能强大的网站。
本项目在Flask开发后端时,前端请求会遇到跨域的问题,解决该问题有修改数据类型为jsonp,采用GET方法,或者在Flask端加上响应头等方式,在此使用安装Flask-CORS库的方式解决跨域问题。此外需要安装请求库axios。
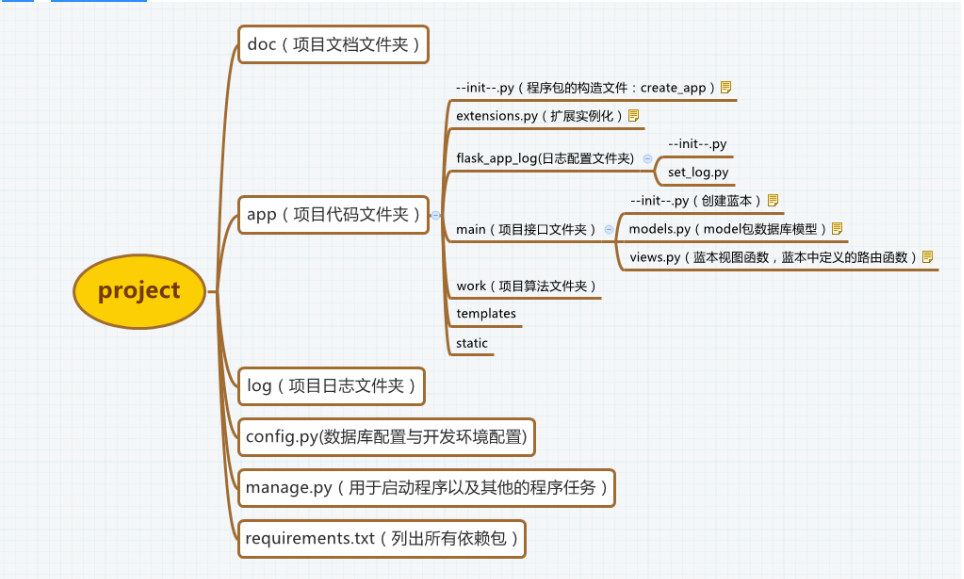
Flask项目结构图
相关代码:
from flask import Flask as _Flask, jsonify, render_template
from flask.json import JSONEncoder as _JSONEncoder
import decimal
import utils
class JSONEncoder(_JSONEncoder):
def default(self, o):
if isinstance(o, decimal.Decimal):
return float(o)
super(_JSONEncoder, self).default(o)
class Flask(_Flask):
json_encoder = JSONEncoder
app = Flask(__name__)
# 这里发现flask根本不会调用我在utils中处理数据的代码,所以直接就在这里定义了两个常量
# 如果想要爬取其它招聘岗位信息的话,先运行utils中的代码,然后运行app.py代码,同时,更改下面的datatable和job_name
datatable = 'data_mining'
job_name = '数据挖掘'
# 路由解析,每映射到一个路由就调用一个函数
@app.route('/')
def index():
return render_template("main.html")
@app.route('/title')
def get_title1():
return job_name
# 获取系统当前时间,每隔1s刷新一次
@app.route('/time')
def get_time1():
return utils.get_time()
# 对数据库中的数据进行计数、薪资取平均值、省份和学历取众数
@app.route('/c1')
def get_c1_data1():
data = utils.get_c1_data(datatable)
return jsonify({"employ": data[0], "avg_salary": data[1], "province": data[2], "edu": data[3]})
# 对省份进行分组,之后统计其个数,使用jsonify来将数据传输给ajax(中国地图)
@app.route('/c2')
def get_c2_data1():
res = []
for tup in utils.get_c2_data(datatable):
res.append({"name": tup[0], "value": int(tup[1])})
return jsonify({"data": res})
# 统计每个学历下公司数量和平均薪资(上下坐标折线图)
@app.route('/l1')
# 下面为绘制折线图的代码,如果使用这个的话需要在main.html中引入ec_left1.js,然后在controller.js中重新调用
# def get_l1_data1():
# data = utils.get_l1_data()
# edu, avg_salary = [], []
# for s in data:
# edu.append(s[0])
# avg_salary.append(s[1])
# return jsonify({"edu": edu, "avg_salary": avg_salary})
def get_l1_data1():
data = utils.get_l1_data(datatable)
edu, sum_company, avg_salary = [], [], []
for s in data:
edu.append(s[0])
sum_company.append(int(s[1]))
avg_salary.append(float(s[2]))
return jsonify({"edu": edu, "sum_company": sum_company, "avg_salary": avg_salary})
# 统计不同学历下公司所招人数和平均经验(折线混柱图)
@app.route('/l2')
def get_l2_data1():
data = utils.get_l2_data(datatable)
edu, num, exp = [], [], []
# 注意sql中会存在decimal的数据类型,我们需要将其转换为int或者float的格式
for s in data:
edu.append(s[0])
num.append(float(s[1]))
exp.append(float(s[2]))
return jsonify({'edu': edu, 'num': num, 'exp': exp})
# 统计不同类型公司所占的数量(饼图)
@app.route('/r1')
def get_r1_data1():
res = []
for tup in utils.get_r1_data(datatable):
res.append({"name": tup[0], "value": int(tup[1])})
return jsonify({"data": res})
# 对猎聘网上的“岗位要求”文本进行分词后,使用jieba.analyse下的extract_tags来获取全部文本的关键词和权重,再用echarts来可视化词云
@app.route('/r2')
def get_r2_data1():
cloud = []
text, weight = utils.get_r2_data(datatable)
for i in range(len(text)):
cloud.append({'name': text[i], 'value': weight[i]})
return jsonify({"kws": cloud})
if __name__ == '__main__':
app.run()
4 Echarts
ECharts(Enterprise Charts)是百度开源的数据可视化工具,底层依赖轻量级Canvas库ZRender。兼容了几乎全部常用浏览器的特点,使它可广泛用于PC客户端和手机客户端。ECharts能辅助开发者整合用户数据,创新性的完成个性化设置可视化图表。支持折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)等,通过导入 js 库在 Java Web 项目上运行。
相关代码:
# 导入模块
from pyecharts import options as opts
from pyecharts.charts import Pie
#准备数据
label=['民营公司','上市公司','国企','合资','外资(欧美)','外资(非欧美)','创业公司','事业单位']
values = [300,300,300,300,44,300,300,300]
# 自定义函数
def pie_base():
c = (
Pie()
.add("",[list(z) for z in zip(label,values)])
.set_global_opts(title_opts = opts.TitleOpts(title="公司类型分析"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c} {d}%")) # 值得一提的是,{d}%为百分比
)
return c
# 调用自定义函数生成render.html
pie_base().render()
5 爬虫
简介
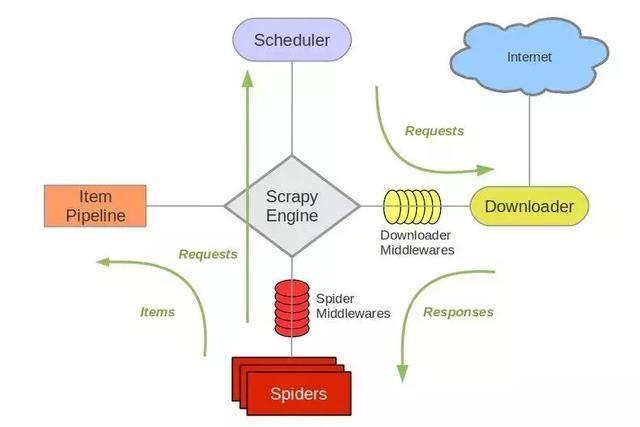
Scrapy是基于Twisted的爬虫框架,它可以从各种数据源中抓取数据。其架构清晰,模块之间的耦合度低,扩展性极强,爬取效率高,可以灵活完成各种需求。能够方便地用来处理绝大多数反爬网站,是目前Python中应用最广泛的爬虫框架。Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。各个组件的作用如下:
-
调度器(Scheduler):说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
-
下载器(Downloader):是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
-
爬虫(Spider):是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
-
实体管道(Item Pipeline):用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
-
Scrapy引擎(Scrapy Engine):Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
官网架构图
相关代码:
# -*- coding: utf-8 -*-
import requests
import re
import json
import time
import pandas as pd
from lxml import etree
# 为了防止被封IP,下面使用基于redis的IP代理池来获取随机IP,然后每次向服务器请求时都随机更改我们的IP(该ip_pool搭建相对比较繁琐,此处省略搭建细节)
# 假如不想使用代理IP的话,则直接设置下方的time.sleep,并将proxies参数一并删除
proxypool_url = 'http://127.0.0.1:5555/random'
# 定义获取ip_pool中IP的随机函数
def get_random_proxy():
proxy = requests.get(proxypool_url).text.strip()
proxies = {'http': 'http://' + proxy}
return proxies
# 前程无忧网站上用来获取每个岗位的字段信息
def job51(datatable, job_name, page):
# 浏览器伪装
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
}
# 每个页面提交的参数,降低被封IP的风险
params = {
'lang': 'c',
'postchannel': '0000',
'workyear': '99',
'cotype': '99',
'degreefrom': '99',
'jobterm': '99',
'companysize': '99',
'ord_field': '0',
'dibiaoid': '0'
}
href, update, job, company, salary, area, company_type, company_field, attribute = [], [], [], [], [], [], [], [], []
# 使用session的好处之一便是可以储存每次的cookies,注意使用session时headers一般只需放上user-agent
session = requests.Session()
# 查看是否可以完成网页端的请求
# print(session.get('https://www.51job.com/', headers=headers, proxies=get_random_proxy()))
# 爬取每个页面下所有数据
for i in range(1, int(page) + 1):
url = f'https://search.51job.com/list/000000,000000,0000,00,9,99,{job_name},2,{i}.html'
response = session.get(url, headers=headers, params=params, proxies=get_random_proxy())
# 使用正则表达式提取隐藏在html中的岗位数据
ss = '{' + re.findall(r'window.__SEARCH_RESULT__ = {(.*)}', response.text)[0] + '}'
# 加载成json格式,方便根据字段获取数据
s = json.loads(ss)
data = s['engine_jds']
for info in data:
href.append(info['job_href'])
update.append(info['issuedate'])
job.append(info['job_name'])
company.append(info['company_name'])
salary.append(info['providesalary_text'])
area.append(info['workarea_text'])
company_type.append(info['companytype_text'])
company_field.append(info['companyind_text'])
attribute.append(' '.join(info['attribute_text']))
# time.sleep(np.random.randint(1, 2))
# 保存数据到DataFrame
df = pd.DataFrame(
{'岗位链接': href, '发布时间': update, '岗位名称': job, '公司名称': company, '公司类型': company_type, '公司领域': company_field,
'薪水': salary, '地域': area, '其他信息': attribute})
# 保存数据到csv文件中
df.to_csv(f'./data/{datatable}/51job_{datatable}.csv', encoding='gb18030', index=None)
# 猎聘网上用来获取每个岗位对应的详细要求文本
def liepin(datatable, job_name, page):
# 浏览器伪装和相关参数
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
}
job, salary, area, edu, exp, company, href, content = [], [], [], [], [], [], [], []
# 使用session的好处之一便是可以储存每次的cookies,注意使用session时headers一般只需放上user-agent
session = requests.Session()
# print(session.get('https://www.liepin.com/zhaopin/', headers=headers, proxies = get_random_proxy()))
# 通过输入岗位名称和页数来爬取对应的网页内容
# job_name = input('请输入你想要查询的岗位:')
# page = input('请输入你想要下载的页数:')
# 遍历每一页上的数据
for i in range(int(page)):
url = f'https://www.liepin.com/zhaopin/?key={job_name}&curPage={i}'
# time.sleep(np.random.randint(1, 2))
response = session.get(url, headers=headers, proxies = get_random_proxy())
html = etree.HTML(response.text)
# 每页共有40条岗位信息
for j in range(1, 41):
# job.append(html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[1]/h3/@title')[0])
# info = html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[1]/p[1]/@title')[0]
# ss = info.split('_')
# salary.append(ss[0])
# area.append(ss[1])
# edu.append(ss[2])
# exp.append(ss[-1])
# company.append(html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[2]/p[1]/a/text()')[0])
href.append(html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[1]/h3/a/@href')[0])
# 遍历每一个岗位的数据
for job_href in href:
# time.sleep(np.random.randint(1, 2))
# 发现有些岗位详细链接地址不全,需要对缺失部分进行补齐
if 'https' not in job_href:
job_href = 'https://www.liepin.com' + job_href
response = session.get(job_href, headers=headers, proxies = get_random_proxy())
html = etree.HTML(response.text)
content.append(html.xpath('//section[@class="job-intro-container"]/dl[1]//text()')[3])
# 保存数据
# df = pd.DataFrame({'岗位名称': job, '公司': company, '薪水': salary, '地域': area, '学历': edu, '工作经验': exp, '岗位要求': content})
df = pd.DataFrame({'岗位要求': content})
df.to_csv(f'./data/{datatable}/liepin_{datatable}.csv', encoding='gb18030', index=None)














 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









