






 本文讲述了如何使用Selenium框架和XPath在51job网站上爬取职位信息,包括设置无界面Chrome驱动、获取和操作XPath地址,以及处理数据抓取和存储的过程。
本文讲述了如何使用Selenium框架和XPath在51job网站上爬取职位信息,包括设置无界面Chrome驱动、获取和操作XPath地址,以及处理数据抓取和存储的过程。
最近想要练习一下爬虫,但是打开51job的页进行操作发现,url地址基本不怎么变化,不太容易提取url地址,发现无论是搜索 java 还是 python 地址是不变的,点击页码地址也不会变化。所以用操作地址的爬虫框架就不太容易操作了,下面是使用selenium爬取51job的具体流程,代码部分几乎每一行都有注释
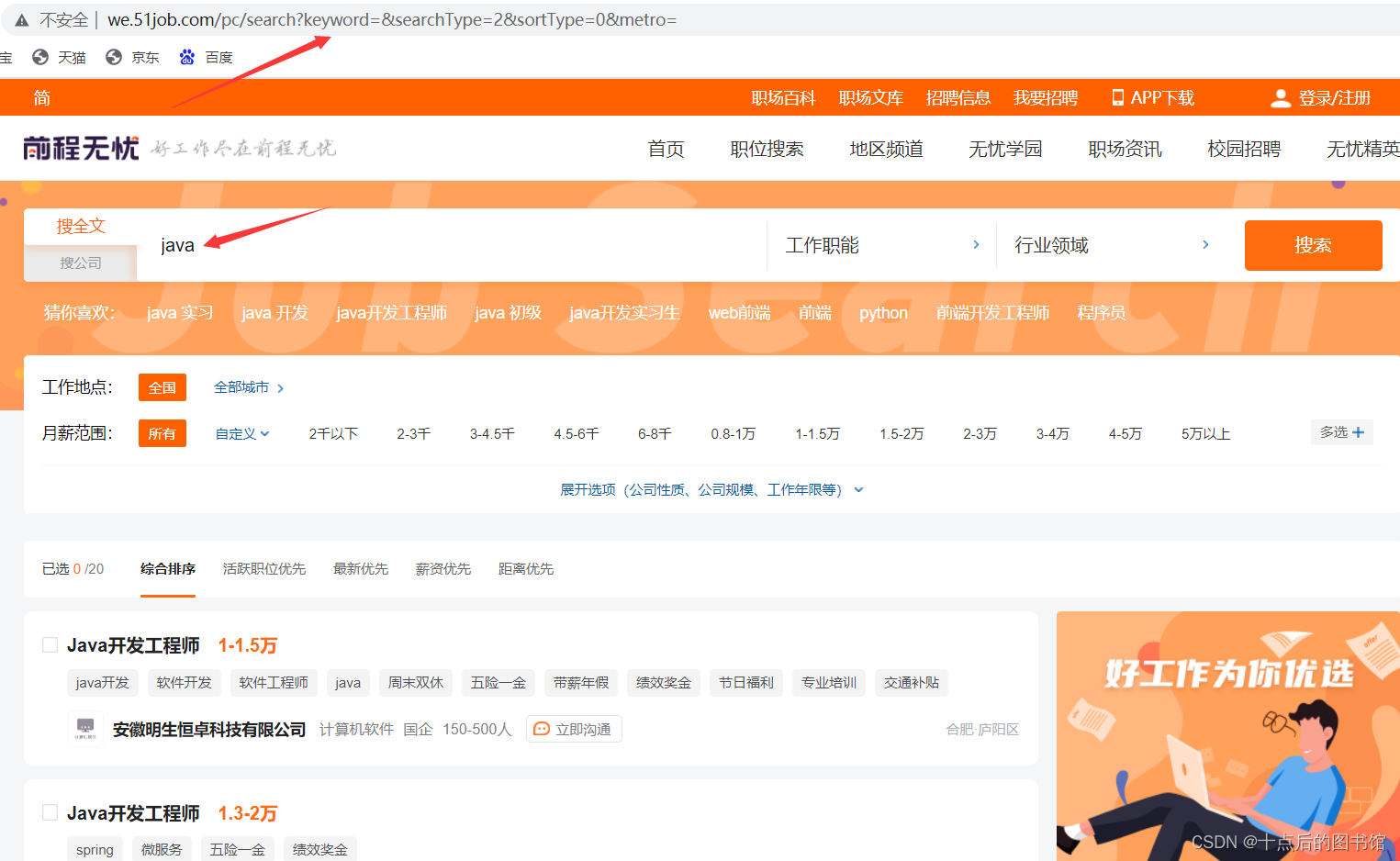

一、在操作之前需要先下载一下与本机chrome版本基本一致的chrome驱动
驱动下载地址 http://chromedriver.storage.googleapis.com/index.html
http://chromedriver.storage.googleapis.com/index.html
谷歌浏览器版本
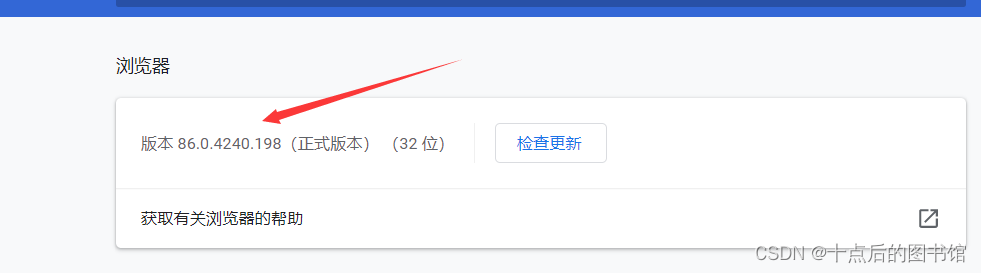
驱动版本

二、 xpath地址的获取方式
以下边第一行代码为例
# 向搜索框传入关键字
web.find_element(By.XPATH, '//*[@id="keywordInput"]').send_keys(keyword)
# 点击搜索
web.find_element(By.XPATH, '//*[@id="search_btn"]').click()


经过上边三步就可以获得xpath地址了,是不是很简单!
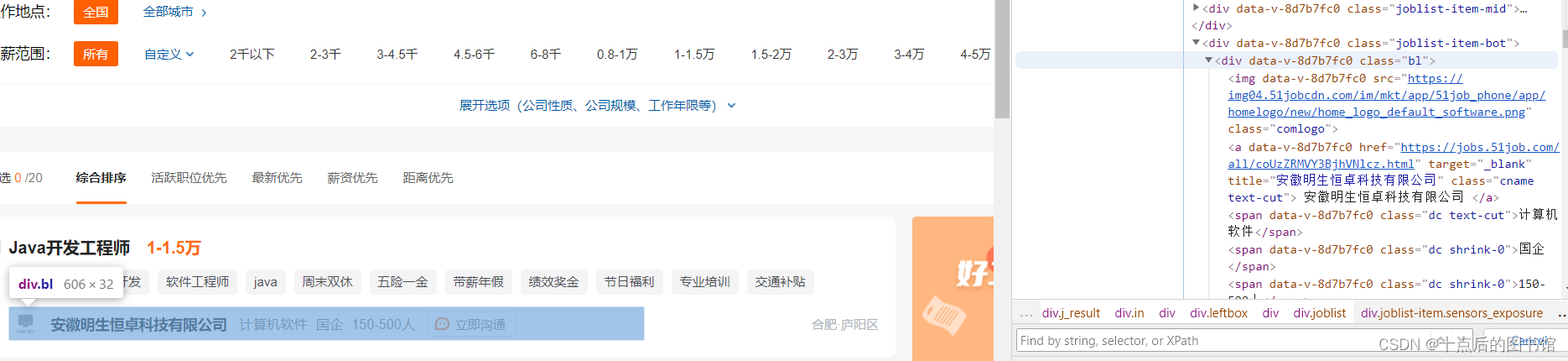
一级页面
观察页面发现有用的数据基本都在这个地方,除了公司名称,公司性质和公司规模

公司名称,公司性质和公司规模 在这个地方
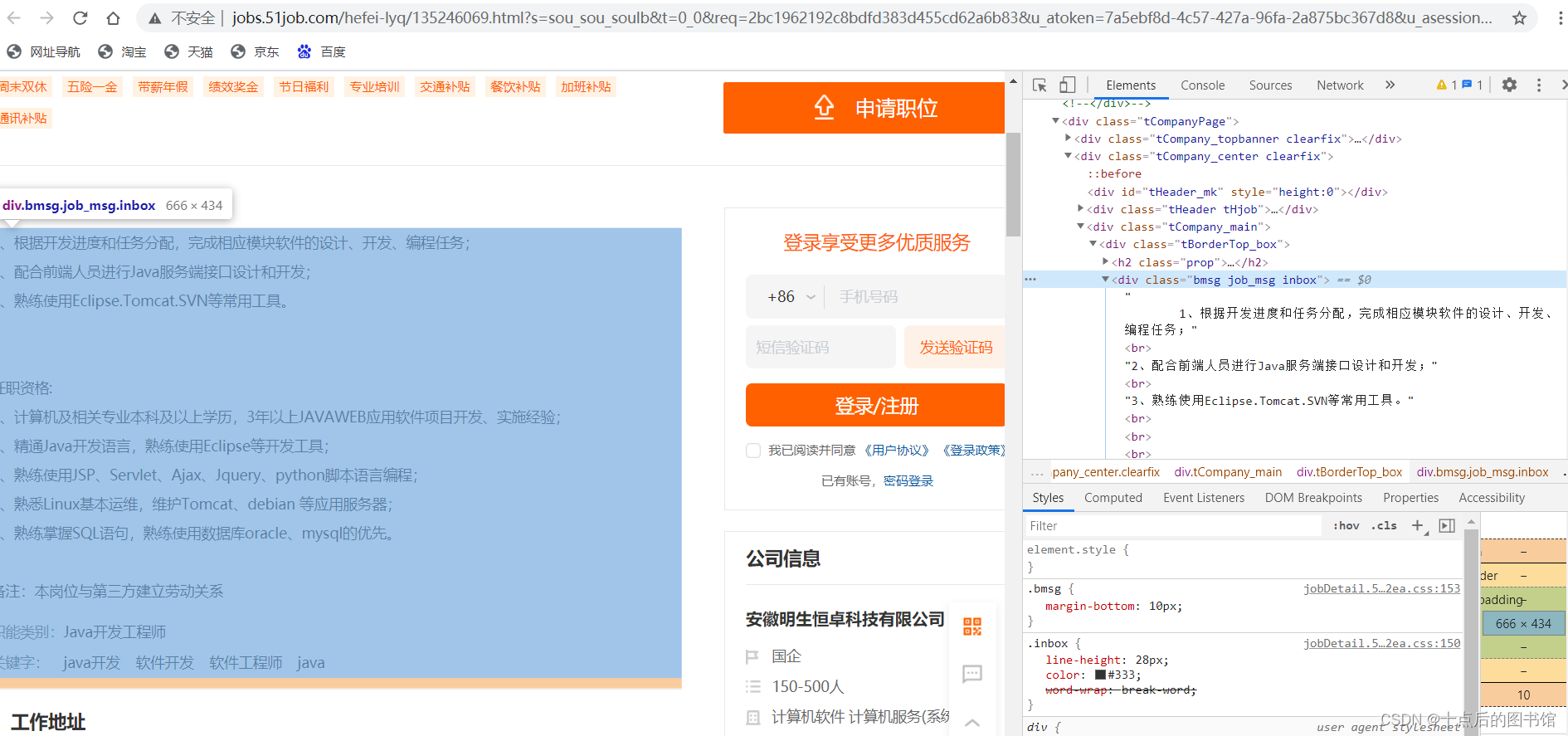
二级页面
三、完整代码
from datetime import datetime
from time import sleep
import json
import ktool
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from mysql_util import MysqlUtil
url = 'https://we.51job.com/pc/search?keyword=&searchType=2&sortType=0&metro=' #初始url地址
opt = Options()
opt.add_argument("--headless") # 无界面启动
opt.add_experimental_option('useAutomationExtension', False) # 禁用Chrome的自动化拓展程序
opt.add_experimental_option('excludeSwitches', ['enable-automation']) # 确保浏览器不会因为启用自动化模式而出现不必要的错误或异常。
opt.add_argument('--disable-blink-features=AutomationControlled') # 禁用由自动化测试或脚本控制的 Blink 功能。
#chrome驱动 这里需要换成自己的驱动位置
web = Chrome(options=opt, executable_path=r'C:\Program Files (x86)\ESBrowser\chromedriver.exe')
web.get(url)
# 网速快的可以把时间调到小一点
sleep(2)
# 搜索关键字,可以自己定义想爬取的职位
keyword = "python"
c_name = '_%s_%s' % (keyword, datetime.now().strftime('%Y_%m_%d'))
# 实例化数据库创建数据表
db = MysqlUtil()
sql = "CREATE TABLE IF NOT EXISTS {} " \
"(id INT AUTO_INCREMENT PRIMARY KEY,jobTitle VARCHAR(50)," \
"company_name VARCHAR(50),jobArea VARCHAR(20),jobDegree VARCHAR(50)," \
"company_nature VARCHAR(50),company_scale VARCHAR(50),jobTime datetime," \
"job_information TEXT,createDatetime datetime)".format(c_name)
db.create_table(sql)
# 向搜索框传入关键字
web.find_element(By.XPATH, '//*[@id="keywordInput"]').send_keys(keyword)
# 点击搜索
web.find_element(By.XPATH, '//*[@id="search_btn"]').click()
sleep(1)
# 原始窗口柄
original_window = web.current_window_handle
# 需要爬取的页数,现在的51job最大也只有50页
total_page = 5
for page in range(total_page):
# 获取每一页的职位信息对象 [list]
job_info = web.find_elements(By.XPATH,
'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[2]/div[1]/div')
for one_job in job_info:
# 获取存有关键内容的数据
job_attributes = one_job.get_attribute('sensorsdata')
# 转换成json格式
job_attributes = json.loads(job_attributes)
# 定义一个字典存储需要的关键信息
search_result = {}
# 工作名称
search_result['jobTitle'] = job_attributes['jobTitle']
# 公司名称
try:
search_result['company_name'] = one_job.find_element(By.XPATH, './div[4]/div[1]/a').text
except Exception:
search_result['company_name'] = "null"
# 工作地点
search_result['jobArea'] = job_attributes['jobArea']
# 学历要求
search_result['jobDegree'] = job_attributes['jobDegree']
# 公司性质
try:
search_result['company_nature'] = one_job.find_element(By.XPATH, './div[4]/div[1]/span[2]').text
except Exception:
search_result['company_nature'] = "null"
# 公司规模
try:
search_result['company_scale'] = one_job.find_element(By.XPATH, './div[4]/div[1]/span[3]').text
except Exception:
search_result['company_scale'] = "null"
# 发布时间
search_result['jobTime'] = job_attributes['jobTime']
# 跳转到二级页面
one_job.find_element(By.XPATH, './div[2]').click()
sleep(2)
# 获取二级页面窗口柄
for window_handle in web.window_handles:
if window_handle != original_window:
web.switch_to.window(window_handle)
break
sleep(2)
# 二级页面url
url = web.current_url
# 把二级页面的信息整合到一起,如果没有默认为地址
job_information = ktool.xpath.xpath_union(
web.page_source, '/html/body/div[2]/div[2]/div[3]/div[1]/div/text()',
default=url
)
# 关闭二级页面
web.close()
# 返回一级页面
web.switch_to.window(original_window)
# 创建时间
createDatetime = ktool.date.get_datetime()
# 工作要求
search_result['job_information'] = job_information
search_result['createDatetime'] = createDatetime
print(search_result)
db = MysqlUtil()
sql = "INSERT INTO %s (jobTitle, company_name, jobArea, jobDegree, " \
"company_nature, company_scale, jobTime, job_information, createDatetime)" \
"VALUES ('%s', '%s','%s','%s','%s','%s','%s','%s','%s')"\
% (c_name,search_result['jobTitle'],search_result['company_name'],search_result['jobArea'],
search_result['jobDegree'],search_result['company_nature'],search_result['company_scale'],
search_result['jobTime'],search_result['job_information'],search_result['createDatetime'])
# 插入数据库
db.insert(sql)
# 下一页按钮
web.find_element(By.XPATH,
'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[3]/div/div/div/button[2]').click()
sleep(1)
web.quit()数据库部分
import pymysql
class MysqlUtil():
def __init__(self):
'''
初始化方法,连接数据库
'''
host = '127.0.0.1' # 主机名
user = 'root' # 数据库用户名
password = '123456' # 数据库密码
database = '51job' # 数据库名称
self.db = pymysql.connect(host=host, user=user, password=password, db=database) # 建立连接
self.cursor = self.db.cursor(cursor=pymysql.cursors.DictCursor) # 设置游标,并将游标设置为字典类型
# 创建表
def create_table(self,sql):
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
print("发生异常", e)
self.db.rollback()
finally:
self.db.close()
# 插入数据
def insert(self,sql):
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
print("发生异常", e)
self.db.rollback()
finally:
self.db.close()
















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









